[TOC]
嵌入式复习
第一章 嵌入式系统概述
1.嵌入式系统概念:定义、特点、应用、典型嵌入式系统结构
从技术的角度定义:以应用为中心、以计算机技术为基础、软件硬件可裁剪、对功能、可靠性、成本、体积、功耗严格要求的专用计算机系统。 从系统的角度定义:嵌入式系统是设计完成复杂功能的硬件和软件,并使其紧密耦合在一起的计算机系统
特点:
特点一:嵌入式系统中运行的任务是专用而确定的
- 嵌入式系统中运行的任务是专用而确定的
- 桌面通用系统需要支持大量的、需求多样的应用程序
特点二:嵌入式系统往往对实时性提出较高的要求。
-
嵌入式系统往往对实时性提出较高的要求。
-
实时系统:指系统能够在限定的响应时间内提供所需水平的服务。
-
嵌入式实时系统可分为:
强实时型:响应时间μs~ms级;
一般实时:响应时间ms~s级;
弱实时型:响应时间s级以上。
-
-
嵌入式系统中使用的操作系统一般是实时操作系统
特点三:嵌入式系统运行需要高可靠性保障,比桌面系统的故障容忍能力弱很多
-
嵌入式系统运行需要高可靠性保障,比桌面系统的故障容忍能力弱很多
-
嵌入式系统需要忍受长时间、无人值守条件下的运行
-
嵌入式系统运行的环境恶劣
特点四:嵌入式系统大都有功耗约束
- 嵌入式系统大都有功耗约束
特点五:嵌入式系统的开发需要专用工具和特殊方法
- 嵌入式系统比桌面通用系统可用资源少得多
- 嵌入式系统的开发需要专用工具和特殊方法
| 服务器 | 个人计算机 | 嵌入式系统 | |
|---|---|---|---|
| CPU计算能力 | 高 | 中等 | 低/多样 |
| 能耗 | 高 | 中等/低 | 更低 |
| 应用领域 | 数据中心 | 日常应用 | 多样 |
| 可靠性 | 高 | 低 | 严格 |
| 成本 | 高 | 低 | 多样 |
应用:

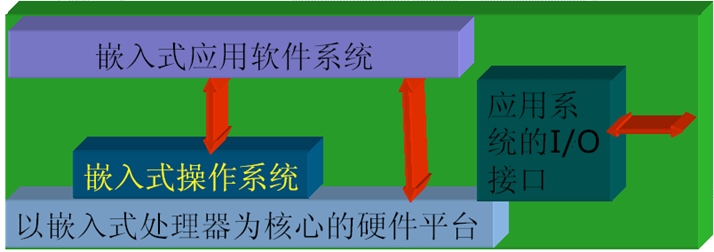
典型嵌入式系统结构
嵌入式系统一般由
- 嵌入式处理器
- 外围硬件设备
- 嵌入式操作系统(可选)
- 以及用户的应用软件系统
等四个部分组成
2.嵌入式系统开发过程,交叉编译的概念
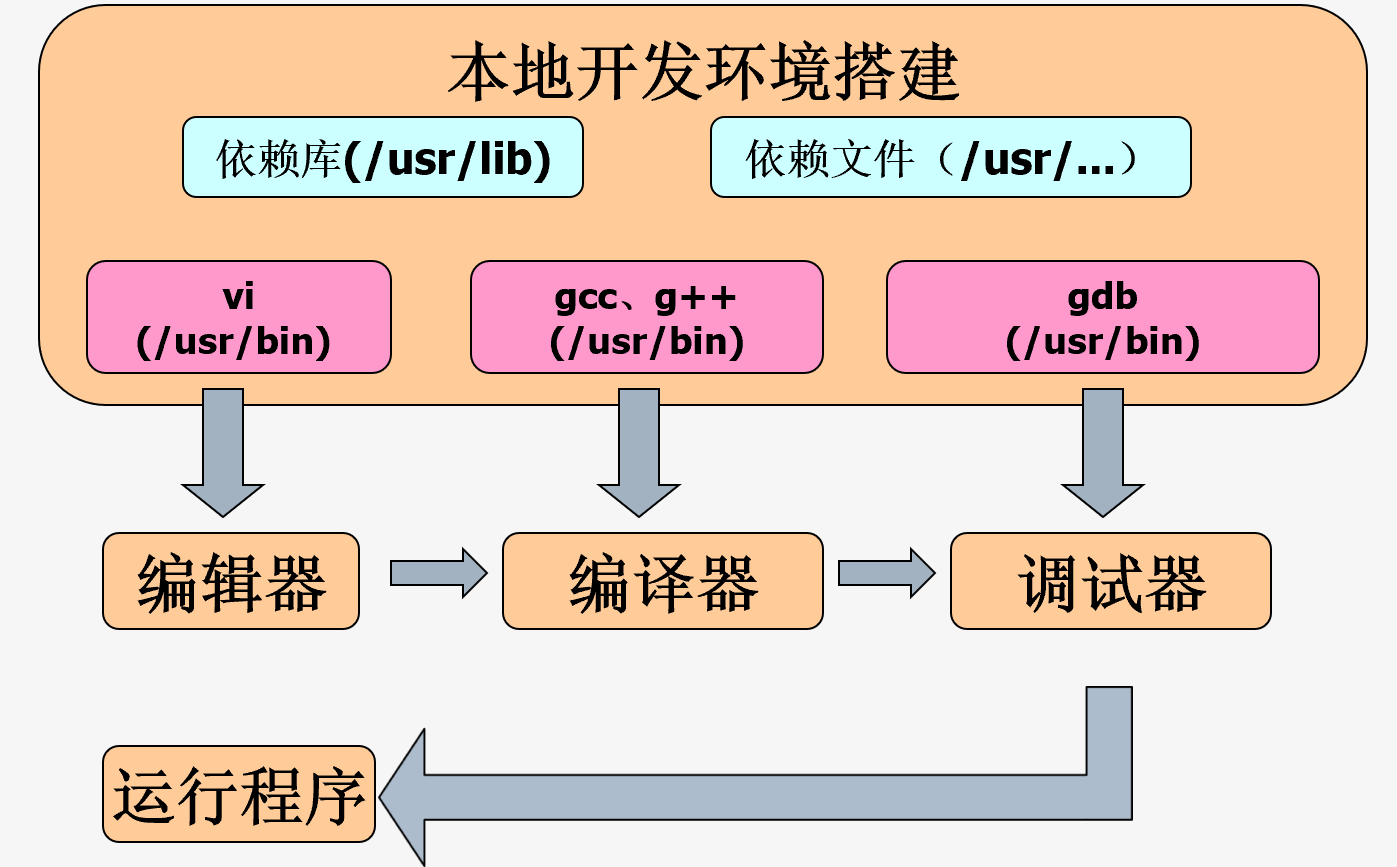
一般应用程序的开发的过程
在linux下本地软件开发的过程
gcc编译的过程
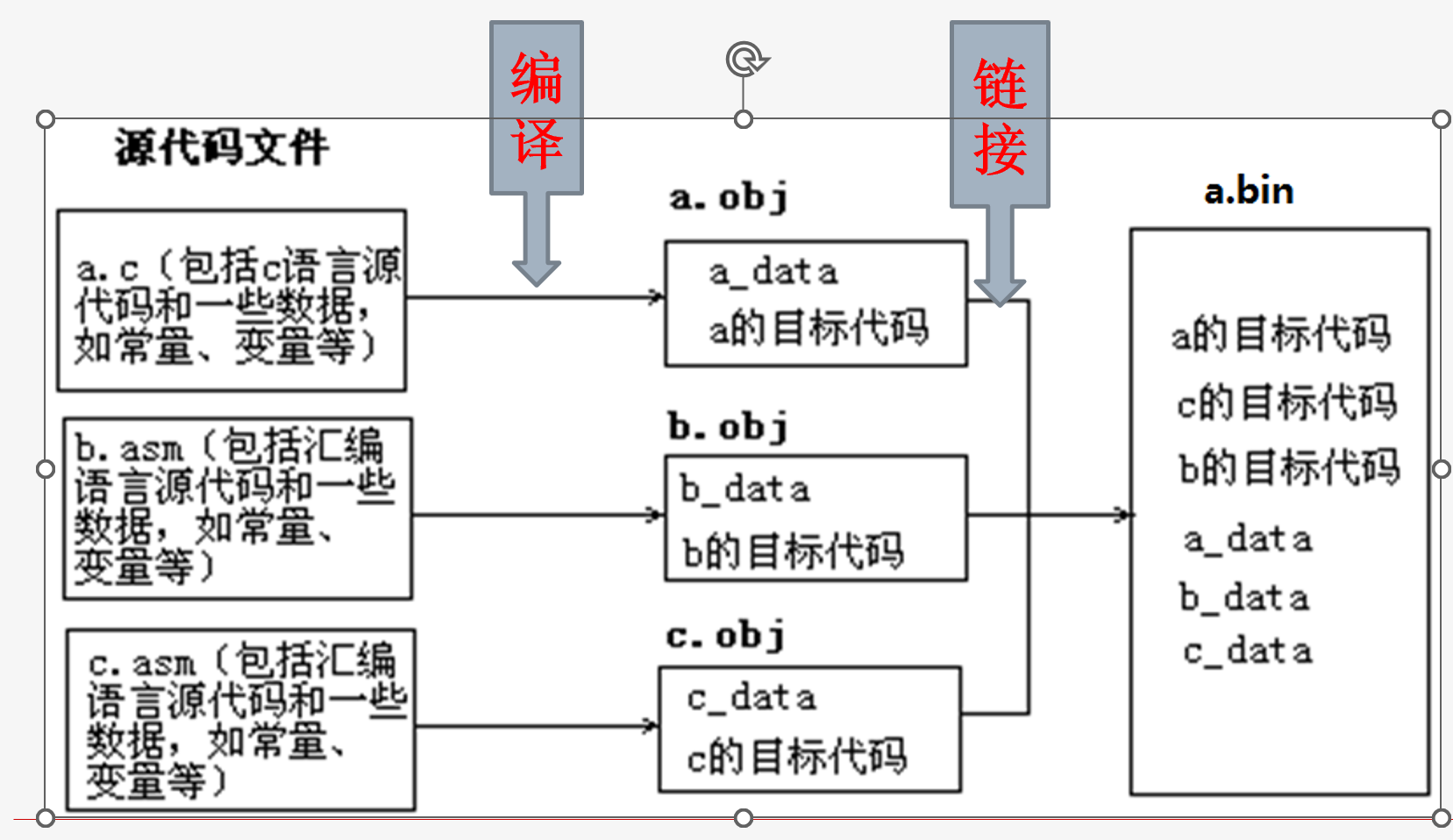
gcc的是GNU C Compiler 的缩写,gcc的整个编译过程,实质上是分四步进行的,这四步分别是:
- 预处理(也称预编译,Preprocessing),调用cpp命令,对源文件中的包含文件和预编译语句进行分析并展开
- 编译(Compilation),用cc命令编译源文件生成目标文件
- 汇编(Assembly) ,针对汇编语言的步骤,调用as命令生成目标文件
- 链接(Linking),由ld命令来完成。
嵌入式软件开发模式
嵌入式系统资源受限,直接在嵌入式系统硬件平台上编写软件较为困难。 解决方法:
- 首先在通用计算机上编写软件
- 然后通过交叉编译生成目标平台上可以运行的二进制代码格式
- 最后再下载到目标平台上运行
宿主-目标机开发模式
嵌入式系统采用双机开发模式:宿主机-目标机开发模式,利用资源丰富的PC机来开发嵌入式软件。

嵌入式软件开发流程
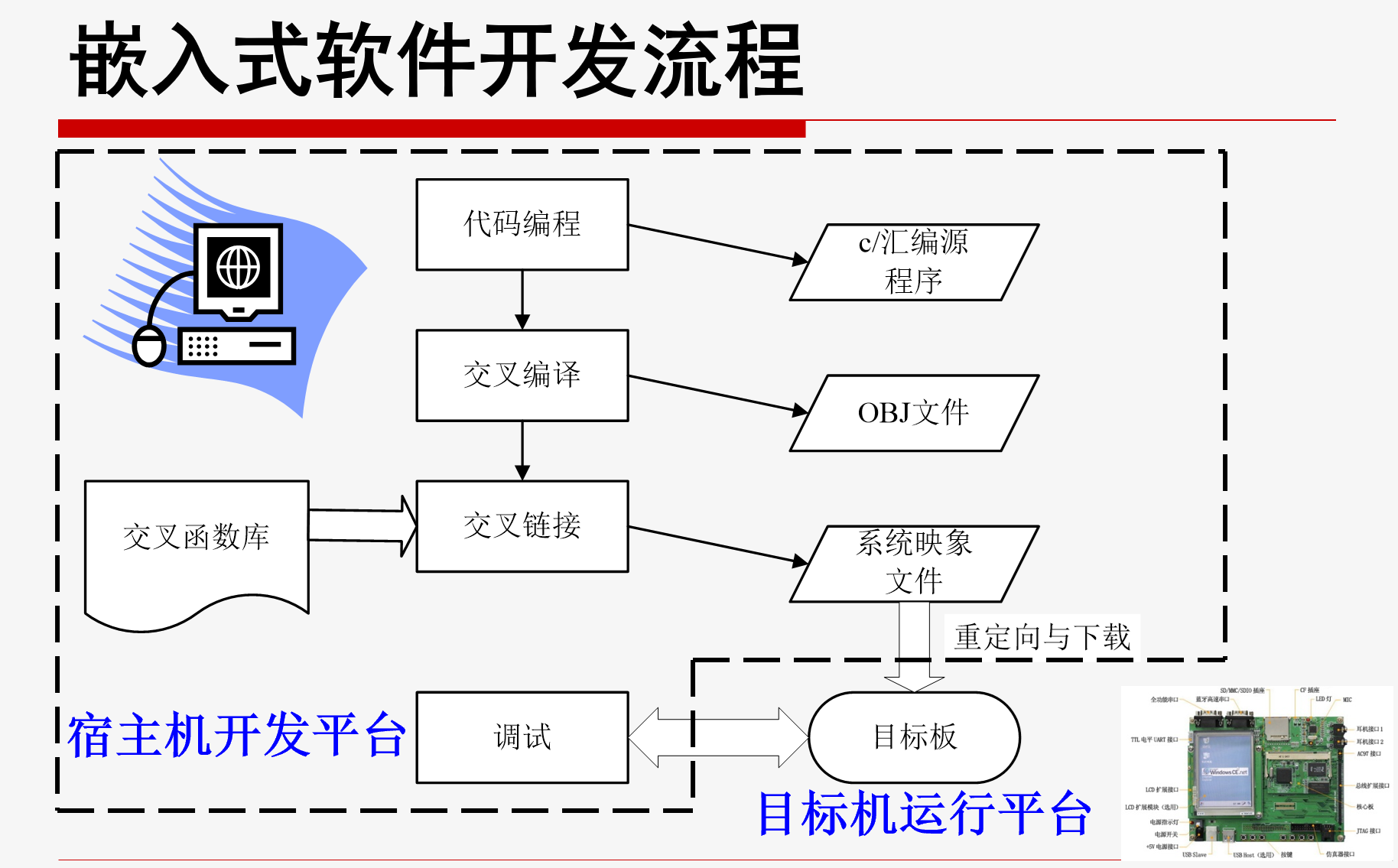
什么是交叉编译(Crossing-compiling)
在一种平台上编译出能在另一种平台(体系结构不同)上运行的程序;
交叉编译器和交叉链接器是指能够在宿主机上安装,但是能够生成在目标机上直接运行的二进制代码的编译器和链接器
| 交叉编译 | 本地调试 |
|---|---|
| 调试器和被调试程序运行在不同的计算机上 | 调试器和被调试程序运行在同一台计算机上 |
| 可独立运行 | 需要操作系统的支持 |
| 可以调试不同指令集的程序 | 只能调试相同指令集的程序 |
| 需要通过外部通信的方式来控制被调试程序 | 不需要通过外部通信的方式来控制被调试程序 |
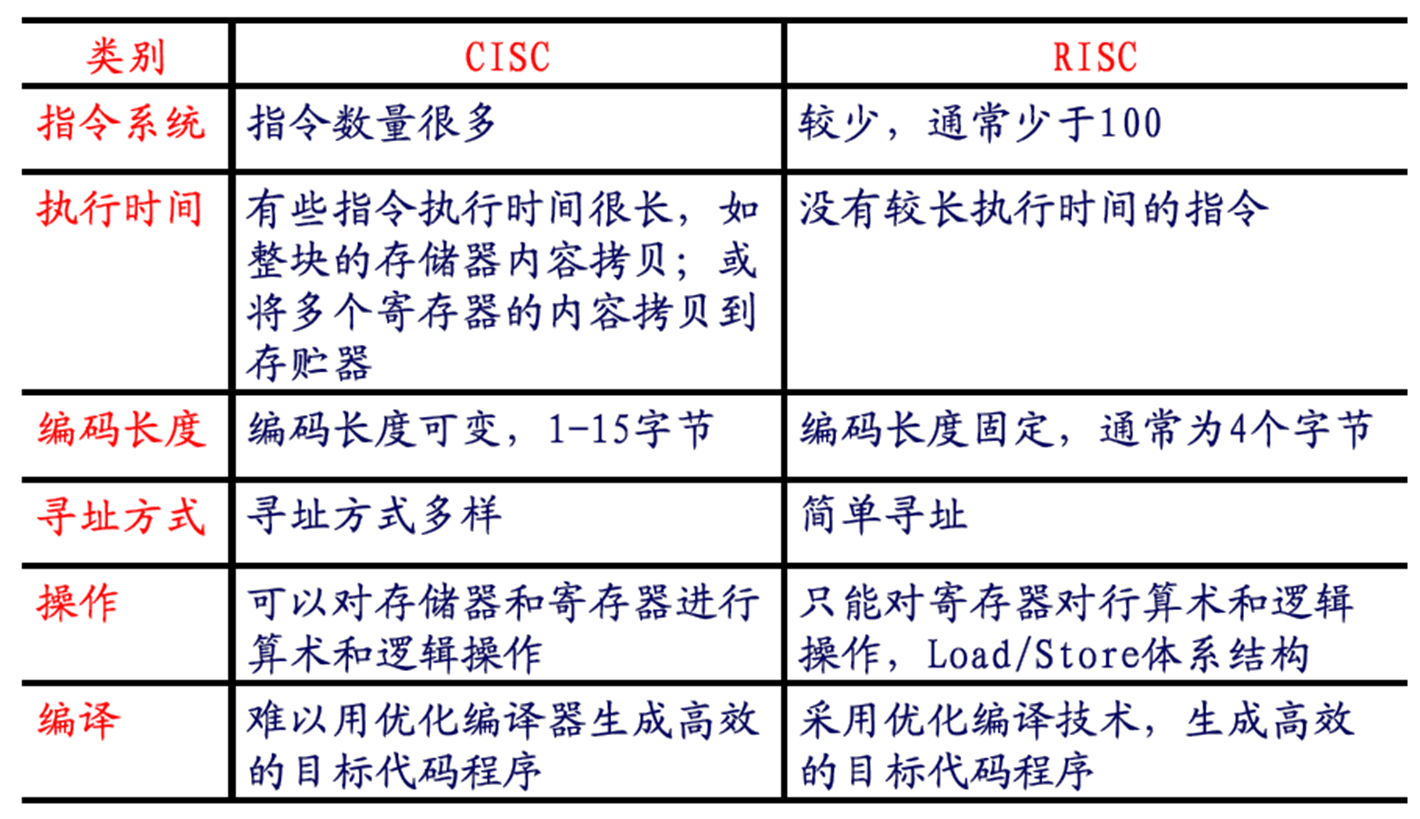
3.处理器结构:哈弗 vs 冯诺依曼,CISC vs RISC
CISC: Complex Instruction Set Compute 复杂指令集 适用于通用计算机
RISC: Reduce Instruction Set Compute 精简指令集 适用于嵌入式系统
RISC中,CPU与memory之间不能直接进行数据传输必须通过load/store指令把数据从内存搬到register,CPU再操作register里面的数据
4.常见的嵌入式处理器、操作系统
嵌入式微处理器
常见的嵌入式微处理器
- ARM:体积小、低功耗、低成本、高性能
- PowerPC (Performance Optimization With Enhanced RISC - Performance Computing)基于RISC
处理器组成:
- 控制单元: 取指令
- 执行运算:数据运算
处理器结构(详细解释):
-
哈佛结构:取指令和数据有各自的总线,执行效率高,设计复杂度高
-
冯诺依曼结构:存储程序原理,代码本身也是数据;简化了结果降低了复杂度,总线的吞吐量成为性能提升的瓶颈
-
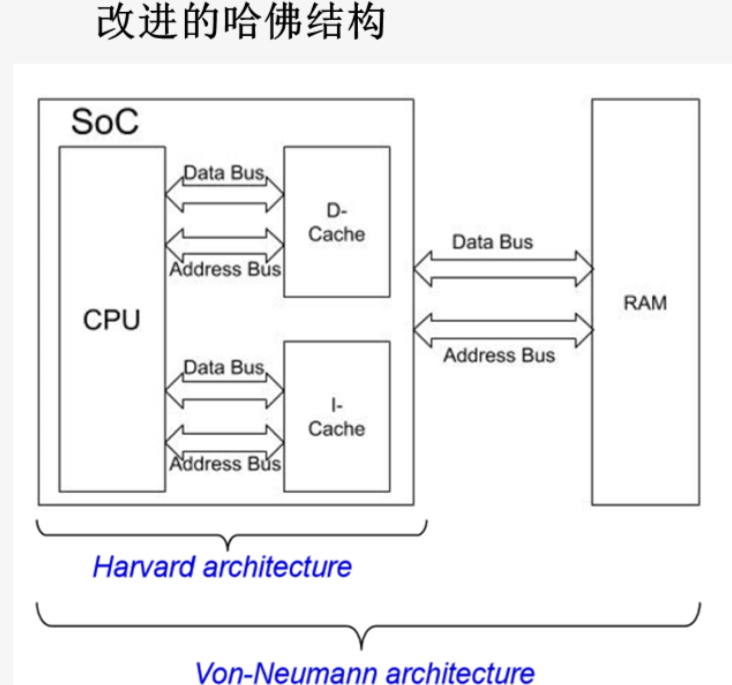
改进的哈佛结构
改进型哈佛结构虽然也使用两个不同的存储器:程序存储器和数据存储器,但它把两个存储器的地址总线合并了,数据总线也进行了合并,即原来的哈佛结构需要4条不同的总线,改进后需要两条总线。
嵌入式处理的结构:
- 嵌入式微处理器 MPU
- 嵌入式微控制器 MCP
- 嵌入式DSP处理器 DSP
- 嵌入式片上系统 System On Chip
嵌入式操作系统:
- 嵌入式操作系统实时操作系统的特点
- 嵌入式实时操作系统应用于实时性要求高的实时控制系统,而且应用程序的开发过程是通过交叉开发来完成的,即开发环境与运行环境是不一致。
- 嵌入式实时操作系统具有规模小(一般在几K~几十K内)、可固化使用实时性强(在毫秒或微秒数量级上)的特点 。
-
嵌入式系统使用实时操作系统的必要性
- 嵌入式操作系统在目前的嵌入式应用中用得越来越广泛,尤其在功能复杂、系统庞大的应用中显得愈来愈重要。
- 在嵌入式应用中,只有把CPU嵌入到系统中,同时又把操作系统嵌入进去,才是真正的计算机嵌入式应用。
- 使用实时操作系统主要有以下几个因素:
- 提高了系统的可靠性
- 提高了开发效率,缩短了开发周期
- 充分发挥了32位CPU的多任务潜力
-
嵌入式实时操作系统的优缺点
- 优点
- 在嵌入式实时操作系统环境下开发实时应用程序使程序的设计和扩展变得容易,不需要大的改动就可以增加新的功能。
- 通过将应用程序分割成若干独立的任务模块,使应用程序的设计过程大为简化;而且对实时性要求苛刻的事件都得到了快速、可靠的处理。
- 通过有效的系统服务,嵌入式实时操作系统使得系统资源得到更好的利用。
- 缺点
- 需要额外的ROM/RAM开销,2~5%的CPU额外负荷。
- 优点
-
操作系统的典型性能指标
- 内核大小:几K~几百K;
- 调度时间:1ms;
- 实时任务响应时间:20~40微妙
- 一般任务响应时间:20微妙~几百毫秒
-
常见嵌入式操作系统
- uClinux
- 开源、针对没有MMU的CPU、适用于没有虚拟内存或内存管理单元(MMU)的处理器
- 保留了Linux的大部分优点:稳定、良好的移植性、优秀的网络功能、完备的对各种文件系统的支持、以及标准丰富的API等。
- WinCE
- Windows CE 是精简的 Windows 95
- 图形用户界面相当出色
- 使绝大多数的应用软件只需简单的修改和移植就可以在Windows CE平台上继续使用。
- Android
- Android是一种基于Linux自由及开放源代码的操作系统
- IOS
- iOS与苹果的Mac OS X操作系统一样,属于类Unix的操作系统
- VxWorks
- 良好的持续发展能力、高性能的内核以及友好的用户开发环境,在嵌入式实时操作系统领域占据一席之地。
- 它以其良好的可靠性和卓越的实时性被广泛地应用在通信、军事、航空、航天等高精尖技术及实时性要求极高的领域中。
- $\mu C/OS-H$
- 源码公开、可移植、可固化、可裁剪、占先式的实时多任务操作系统。
- 用 C写的,使其可以方便地移植并支持大多数类型的处理器。
- μC/OS-II占用很少的系统资源
- eCos
- embedded Configurable operating system
- 是一个可配置、可移植的嵌入式实时操作系统,
- eCOS的所有部分都开放源代码,可以按照需要自由修改和添加。
- eCOS的关键技术是操作系统可配置性,允许用户组和自己的实时组件和函数以及实现方式,
- uClinux
嵌入式系统的设计流程
可以把嵌入式系统的开发看作对一个项目的实施。
项目的生命周期一般分为
- 识别需求
- 提出解决方案
- 执行项目
- 结束项目
嵌入式系统的开发流程
第二章 ARM 体系结构
第二章目录
- ARM微处理器概述
- ARM处理器系列
- RISC体系结构
- ARM微处理器体系结构
- ARM微处理器的工作状态 ARM和Thumb状态
- ARM体系结构的存储器格式
- 处理器模式
- 寄存器组织
- 异常
ARM(Advanced RISC Machines),既可以认为是一个公司的名字,也可以认为是对一类微处理器的通称,还可以认为是一种技术的名字。
基于ARM的SOC设计
- 从ARM或其他第三方购买IP
- 集成IP,仿真,验证,完成SoC设计
- 半导体制造公司完成流片
特点
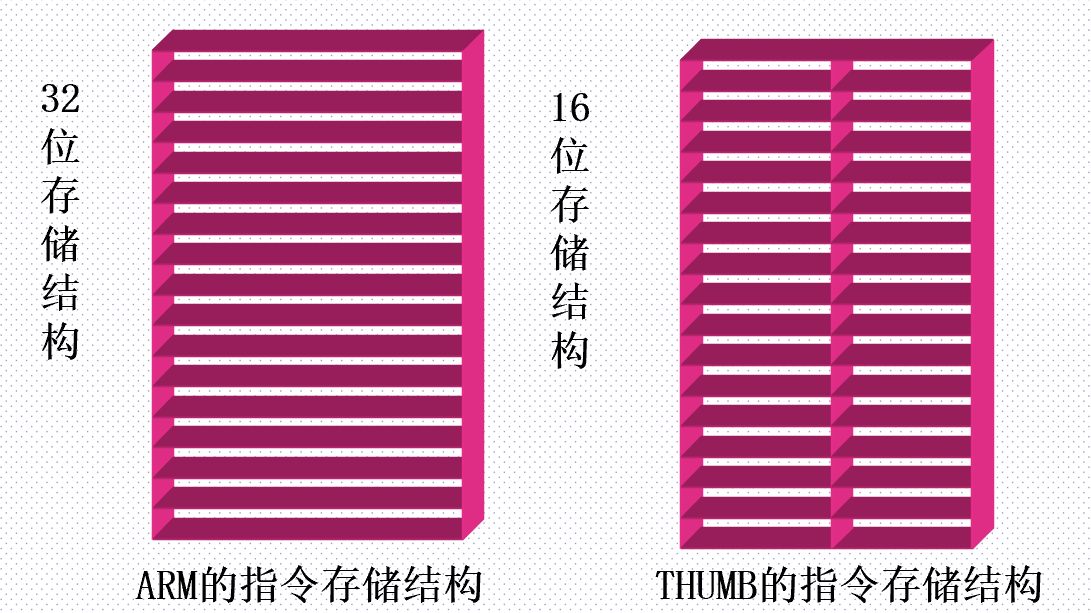
- 支持Thumb(16位)/ARM(32位)双指令集
- 使用寄存器,指令执行速度更快
- 大多数数据操作都在寄存器中完成
- 寻址方式灵活简单,执行效率高
- 指令长度固定
1. IP 核的概念:软核、硬核、固核
IP核(Intellectual Property) 知识产权
硅知识产权核是预先设计好的电路功能模块,根据IP核的提供方式,分为软核(Soft IP Core),固核(Firm IP Core)硬核(Hard IP Core)
- 软核:综合之前的RTL代码,只经过功能仿真,需要经过综合以及布局布线才能使用。
- 固核:完成软核的设计外,及门级电路综合和时序仿真等设计环节,以门级电路网表的形式提供给用户。
- 硬核:基于物理描述并经过工艺验证,提供给用户的形式是电路物理结构、掩模版图和全套工艺文件。
2.了解:指令集架构、处理器系列、嵌入式系统总线
RISC体系结构
特点:精简指令集计算机RISC结构的产生是相对于传统的复杂指令集计算机CISC 结构而言的。
CISC(Complex Instruction Set Computer,复杂指令集计算机)缺点:
- 随着计算机技术的发展而不断引入新的复杂指令集,为支持这些新增的指令,计算机的体系结构会越来越复杂
- 然而,在CISC指令集的各种指令中,其使用频率却相差悬殊,约20%的指令会被反复使用,占整个程序代码的80%。而余下的80%的指令却不经常使用,在程序设计中只占20%
基于不合理性提出了RISC(Reduced Instruction Set Computer,精简指令集计算机)的概念:
- 指令系统相对简单,只要求硬件执行很有限且最常用的那部分指令,大部分复杂的操作则使用成熟的编译技术,由简单指令合成。
- RISC不是简单地减少指令, 而是把着眼点放在 :
- 使计算机的结构更加简单;
- 合理地提高运算速度。
- RISC优先选取使用频度最高的简单指令,避免复杂指令;
- 将指令长度固定,指令格式和寻址方式种类减少;
RISC特点:
- 指令规整、对称、简单。指令小于100条,基本寻址方式有2~3种。
- 指令字长度一致,单拍完成,便于流水操作;
- ARM7 三级流水线:取值,译码,执行;
- ARM9 五级流水线:取值,译码,执行,访存,回写;
- 大量的寄存器。寄存器不少于32个。数据处理器的指令只对寄存器的内容操作。只有加载/存储指令可以访问存储器。
CISC vs RISC
ARM处理系列
ARM处理器的分类
- 基于指令集体系结构版本分类
- v1,v2,v5,v6,v7,v8,v9等
-
基于处理器系列分类
-
基于ARM体系结构设计的处理器系列
-
ARM7,ARM9,ARM10,ARM11,StrongARM,XScale等
-
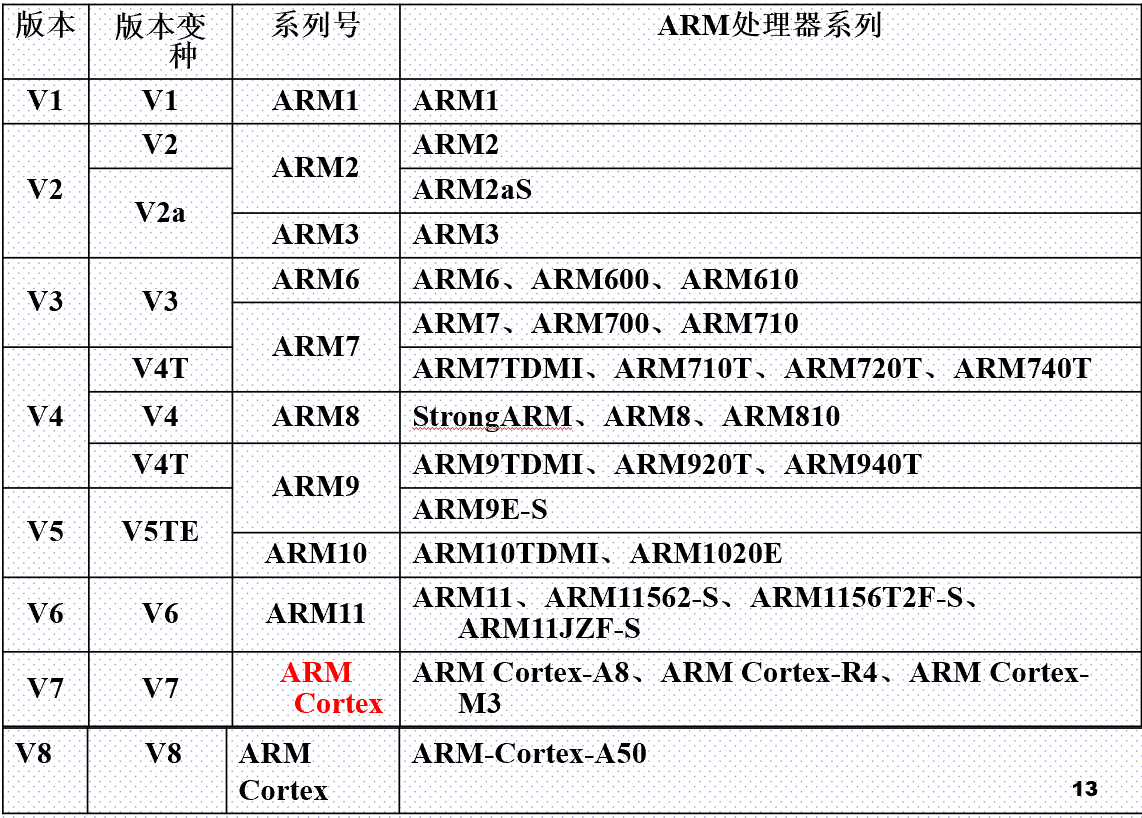
ARM架构发展系列
- V1版本 该版架构只在原型机ARM1出现过,其基本性能:
- 基本的数据处理指令(无乘法)
- 字节、半字和字的LOAD/STORE指令
- 转移指令,包括子程序调用及链接指令
- 软件中断指令
- 寻址空间:64M字节(26)
- V2版架构 该版架构对V1版进行了扩展,如ARM2采用了V2架构,ARM3采用v2a架构,增加了以下功能:
- 乘法和乘加指令
- 支持协处理器操作指令
- 快速中断模式
- SWP/SWPB指令,实现存储器与寄存器数据交换
- 寻址空间:64M字节(26)
- V3版架构 从V3开始,ARM体系结构被大规模应用
- 寻址空间增至32位(4G字节)
- 增加了当前程序状态寄存器CPSR和备份程序状态寄存器SPSR以便于异常的处理。
- CPSR: Current Program Status Register
- SPSR: Saved Program Status Register
- MRS指令将状态寄存器的值保存到通用寄存器,
- MSR将通用寄存器中的值还原到状态寄存器
- 增加了中止abort和未定义二种异常模式。
- ARM6就采用该版架构
- 指令集变化如下:
- 增加了MRS/MSR指令,以访问新增的CPSR/SPSR寄存器
- 改进了从异常处理返回的指令功能
- V4版架构 V4版架构是应用最广泛的ARM体系结构, ARM7、ARM8、ARM9和StrongARM都采用该版架构。对V3版架构进行了进一步扩充, 引入了16位的Thumb指令集,处理器存在两种工作状态,使ARM使用更加灵活。指令集中增加了以下功能:
- 有符号、无符号的半字和有符号字节的Load/Store指令。
- 引入了16位Thumb指令集
- 完善了软件中断SWI指令的功能
- 增加了处理器的系统模式。
- V5版架构 在V4版基本上增加了一些新的指令, ARM9E,ARM10和XScale都采用v5版架构,这些新增指令有:
- 提高ARM和Thumb指令集混合使用的效率
- 增加了前导零计数CLZ指令
- 引入了软件断点指令BKPT,进行中断调试
- 增加了信号处理指令
- 为协处理器增加更多可选择的指令 CLZ:Count Leading Zeros,计算最高符号位与第一个1之间的0的个数;
- V6版架构
- 2001年发布
- 首先在ARM11处理器中使用
- 具备高性能DSP功能
- 引入全新的Jazelle技术,降低Java应用程序对内存的空间占用
- 增加了 SIMD(单指令流多数据流 )功能扩展,提高了嵌入式应用系统的语音,图像处理能力。SIMD:Single Instruction Multiple Data,(XYZW,RGBA)
- 适合使用电池供电的便携式设备
- V7版架构
- 目前为止32位ARM处理器体系结构的最高版本
- Cortex系列基于V7架构
- Cortex-A—面向性能密集型系统的应用处理器内核
- Cortex-R—面向实时应用的高性能内核
- Cortex-M—面向各类嵌入式应用的微控制器内核
- V8版架构
- 2011年11月发布
- 首款支持64位指令集的处理器器架构
- 针对有更高性能要求的产品,如高档消费类电子
- 64位兼容32位
- ARMv8架构包含两个执行状态:AArch64和AArch32
- V9版架构
- 2021年3月发布
- 支持64位指令集的处理器器架构
- 针对有更高性能要求的产品,如高档消费类电子
- 64位兼容32位
- 引入机密计算技术Realm模块,防止像Spectre和Meltdown这样的新型安全漏洞攻击
- 对AI模块的升级,重点在于改善CPU的AI性能
- 扩展到PC、HPC高性能计算、深度学习等新市场
ARM处理器系列
[!NOTE]
命名规则
| 标志 | 含义 | 说明 |
|---|---|---|
| T | 支持Thumb指令集 | Thumb指令集版本1:ARMv4T Thumb指令集版本2:ARMv5T Thumb-2:ARMv6T |
| D | 片上调试 | 一个边界扫描链 JTAG,可使 CPU 进入调试模式 |
| M | 快速乘法器 | 32位乘32位得到64位,32位的乘加得到64位 |
| I | Embedded ICE | 嵌入式跟踪宏单元,用于实现断点观测及变量观测的逻辑电路部分。提供片上断点和调试点 |
| E | DSP指令 | 增加了DSP算法处理器指令:16位乘加指令,饱和的带符号数的加减法,双字数据操作,cache预取指令 |
| J | Java加速器Jazelle | 提高java代码的运行速度 |
| S | 可综合 | 提供VHDL或Verilog语言设计文件 |
- ARM7
- 低功耗
- EmbededICE软件调试方式 ICE:In Circuit Emulation,在线仿真器
- 0.9MIPS/MHz的3级流水线结构 MIPS:Million Instruction Per Second 每秒百万条指令
- 32位ARM指令集和16位的Thumb指令集
- 主频最高可达130MHz
- 该系列包括ARM7TDMI、ARM7TDMI-S、带有高速缓存处理器宏单元的ARM720T和扩充了Jazelle( java加速器)的ARM7EJ-S。
- ARM7系列广泛应用于多媒体和嵌入式设备,网络和调制解调器设备,以及移动电话、PDA等无线设备。
- AMR9 特点:
- 1.1MIPS/MHz的哈佛结构,5级流水线
- 32位ARM指令集和16位Thumb指令集
- 支持32位的高速AMBA总线接口
- 全性能的MMU,支持Windows CE、Linux、Palm OS等多种主流嵌入式操作系统 MMU:Memory Management Unit
- 支持数据Cache和指令Cache,具有更高的指令和数据处理能力
- 该系列包括ARM9TDMI、ARM920T和带有高速缓存处理器宏单元的ARM940T。
- 主要应用于引擎管理、仪器仪表、安全系统和机顶盒等领域
- ARM10E ARM10E系列微处理器具有高性能、低功耗的特点,与ARM9器件相比较,在相同的时钟频率下,性能提高了近50%。
- 支持DSP指令集,适合于需要高速数字信号处理的场合。
- 6级整数流水线,指令执行效率更高,1.25MIPS/MHZ。
- 支持64位的高速AMBA总线接口。
- 支持VFP10浮点处理协处理器。
- 全性能的MMU,支持Windows CE、Linux、Palm OS等多种主流嵌入式操作系统。
- 支持数据Cache和指令Cache,具有更高的指令和数据处理能力
- 主频最高可达400M。
- ARM10E系列微处理器主要应用于下一代无线设备、数字消费品、成像设备、工业控制、通信和信息系统等领域。
- ARM10E系列微处理器包含ARM1020E、ARM1022E和ARM1026EJ-S三种类型,以适用于不同的应用场合。
- SecurCore
- 该系列涵盖了SC100、SC110、SC200和SC210处理核。
- 该系列处理器主要针对新兴的安全市场,以一种全新的安全处理器设计为智能卡和其它安全IC开发提供独特的32位系统设计。
- 主要应用于一些对安全性要求较高的应用产品及应用系统,如电子商务、电子政务、电子银行业务、网络和认证系统等领域。
嵌入式系统总线
ARM微控制器使用的是AMBA总线体系结构
AMBA(Advanced Microcontroller Bus Architecture)是ARM公司公布的总线标准,AMBA 2.0规范定义了三种总线:
- AHB总线(Advanced High-performance Bus):用于连接高性能系统模块。它支持突发数据传输方式及单个数据传输方式,所有时序 参考同一个时钟沿。
- ASB总线(Advanced System Bus):用于连接高性能系统模块,在不必要使用AHB的高速特性的场合,它支持突发数据传输模式。
- APB总线(Advance Peripheral Bus):是一个简单接口支持低性能的外围接口。
- 3.0 引入AXI总线 (Advanced eXtensible Interface)
[!NOTE]
会画图

3.ARM 处理器的两种工作状态,及如何切换
ARM和Thumb状态
ARM微处理器的工作状态一般有两种:
- ARM状态—处理器执行32位的字对齐的ARM指令,伪指令CODE32声明;
- Thumb状态—处理器执行16位的、半字对齐的Thumb指令,伪指令CODE16声明。
Thumb指令可以看做是ARM指令压缩形式的子集
Thumb指令集的功能是32位ARM指令集的功能子集。Thumb在性能和代码大小之间提供了出色的折中。
-
正在执行Thumb指令集的处理器是工作在Thumb状态下。
-
正在执行ARM指令集的处理器是工作在ARM状态下。
-
带状态切换的分支指令BX
代码密度:单位存储空间中包含的指令的个数。
4. 三级流水 vs 五级流水,大端格式 vs 小端格式
三级流水
- 第一级取指:取指级的任务是从程序存储器中读取指令。
- 第二级译码:译码级完成对指令的解析,并为下一个周期准备数据路径需要的控制信号。由指令与译码逻辑完成,不占用数据通路。
- 第三级执行:执行完成指令要求的操作,并根据需要将结果写回目的寄存器。
注意:PC指向正被取指的指令,而非正在执行的指令
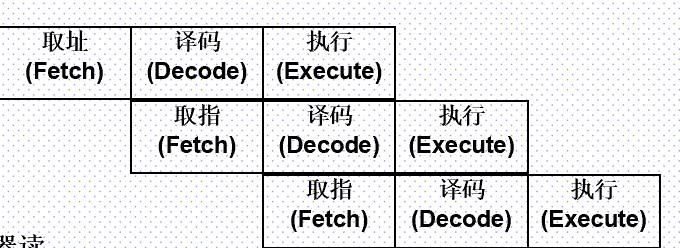
五级流水
- 第一级取指:取指级的任务是从程序存储器中读取指令。
- 第二级译码:译码级完成对指令的解析,并为下一个周期准备数据路径需要的控制信号。由指令与译码逻辑完成,不占用数据通路。
- 第三级执行:执行完成指令要求的操作,并根据需要将结果写回目的寄存器。
- 第四级访存:如果不是对存储器的访问指令,本级流水线为一个空的时钟周期
- 第五级写入:
ARM9具有5级流水线,将存储器的访问和寄存器写操作分别有单独的流水线来处理,解决了3级流水线LDR/STR指令执行阶段的延迟,提高了指令执行效率。
ARM体系结构的存储器格式
ARM体系结构可以用两种方法存储字数据,称为大端格式(Big-Endian)和小端格式(Little-Endian )。
-
大多数CPU是小端格式,如DSP,PC机
-
单片机、网络传输的TCP/IP协议,是大端格式
-
51单片机,是大端格式
-
ARM默认小端格式,但用户可设置大、小端格式。
-
所以在使用TCP/IP协议通信的时候,要注意大、小端格式转换
大端格式(Big Endian)
字数据的高字节存储在低地址中,而字数据的低字节则存放在高地址中。
小端格式(Little Endian)
低地址中存放的是字数据的低字节,高地址存放的是字数据的高字节。
5. 处理器的工作模式,每种模式的特点,特权模式,异常模式
ARM体系结构支持7种处理器模式,分别为:
用户模式、系统模式、快中断模式、中断模式、管理模式、中止模式、未定义模式。
—–更好地支持操作系统并提高工作效率。
| 处理器模式 | 说明 | 备注 |
|---|---|---|
| 用户(usr) | 正常程序工作模式 | 不能直接切换到其它模式 |
| 系统(sys) | 用于支持操作系统的特权任务等 | 与用户模式类似,但具有可以直接切换到其它模式等特权 |
| 快中(fiq) | 支持高速数据传输及通道处理 | FIQ异常响应时进入此模式 |
| 中断(irq) | 用于通用中断处理 | IRQ异常响应时进入此模式 |
| 管理(svc) | 操作系统保护代码 | 系统复位和软件中断响应时进入此模式 |
| 中止(abt) | 用于支持虚拟内存和/或存储器保护 | 预取中止和数据中止 |
| 未定(und) | 支持硬件协处理器的软件仿真 | 未定义指令异常响应时进入此模式 |
-
除用户模式外,其它模式均为特权模式。ARM内部寄存器和一些片内外设在硬件设计上只允许(或者可选为只允许)特权模式下访问。此外,特权模式可以自由地切换处理器模式,而用户模式不能直接切换到别的模式。
-
除去(用户和系统)这五种模式称为异常模式。它们除了可以通过程序切换进入外,也可以由特定的异常进入。当特定的异常出现时,处理器进入相应的模式。每种异常模式都有一些独立的寄存器,以避免异常退出时用户模式的状态不可靠。
-
用户模式和系统模式这两种模式使用完全相同的寄存器组。 系统模式是特权模式,不受用户模式的限制。操作系统在该模式下访问用户模式的寄存器就比较方便,而且操作系统的一些特权任务可以使用这个模式访问一些受控的资源。
处理器启动时的模式转换图
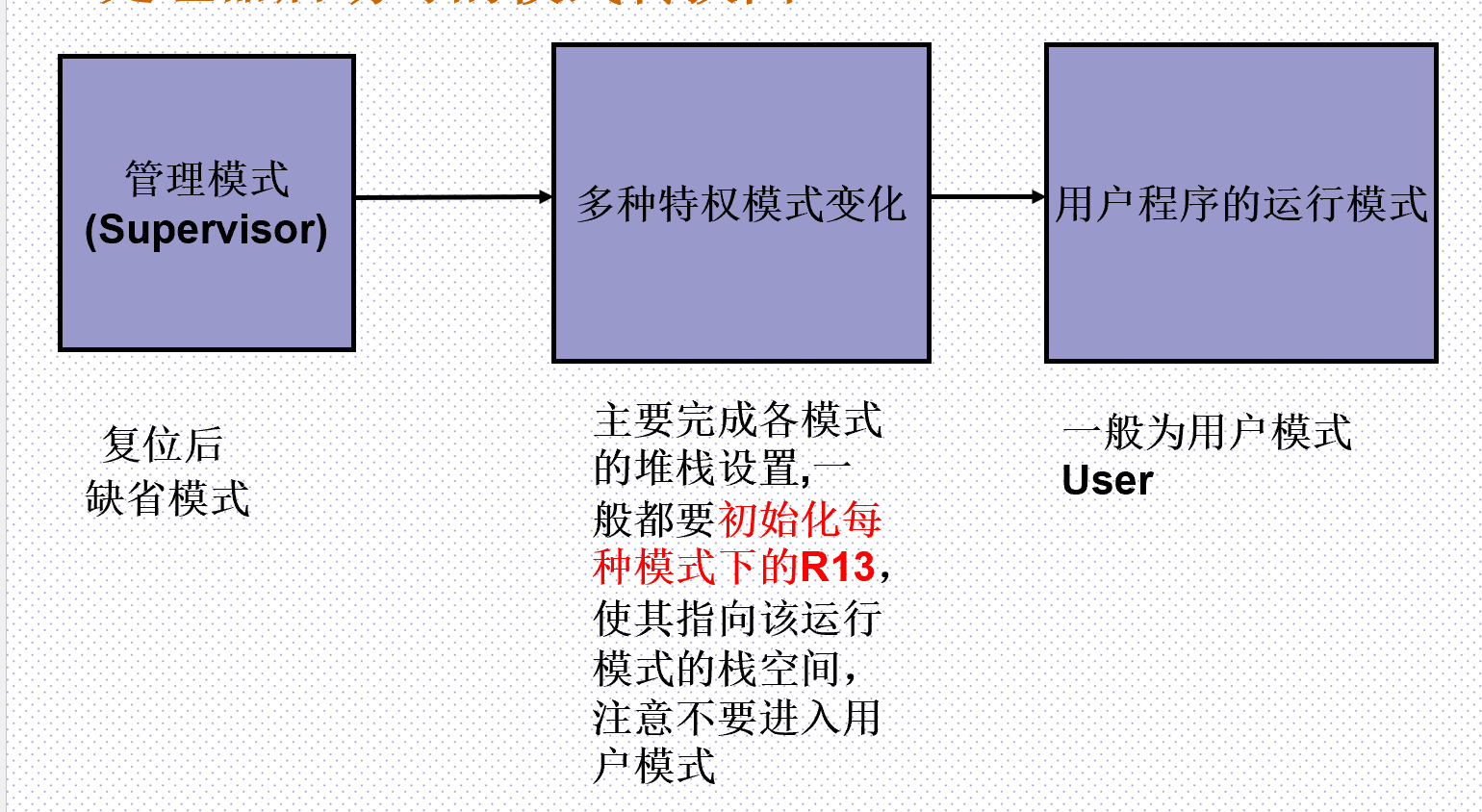
总结:
-
ARM微处理器的运行模式可以通过软件改变(特权模式),也可以通过外部中断或异常处理改变。
-
特权模式可以自由地访问系统资源和改变模式。
-
大多数的应用程序运行在用户模式下,当处理器运行在用户模式下时,某些被保护的系统资源是不能被访问的。也不能改变模式。除非异常发生。
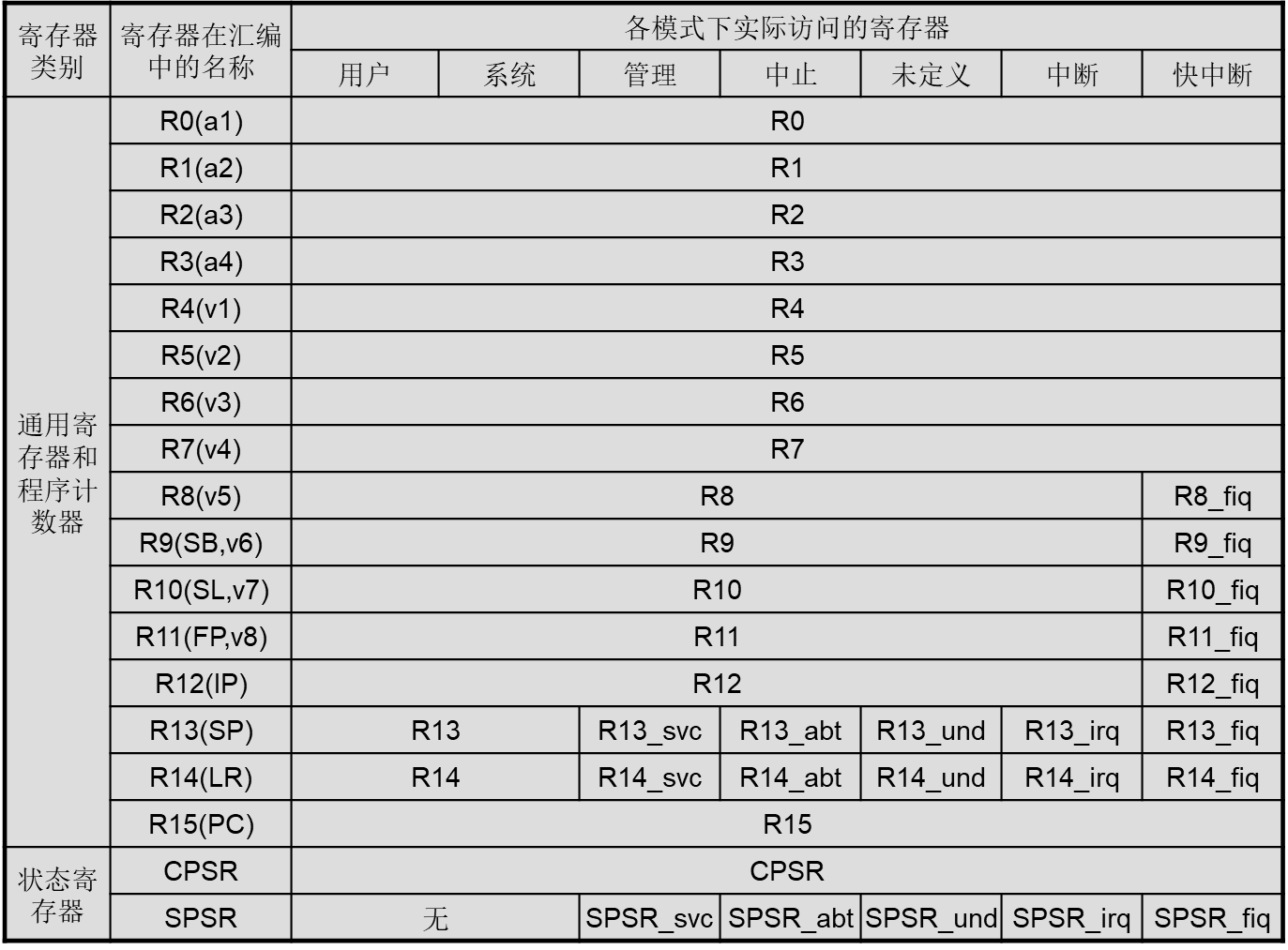
6. 寄存器组织,个数,特殊含义的寄存器 R13 R14 R15,CPSR,SPSR(读写 指令 MRS,MSR)
- ARM处理器有37(31+6)个物理寄存器,31个通用寄存器和6个状态寄存器 。
- 寄存器被安排成部分重叠的组。每种处理器模式都有不同的寄存器组。
- 分组的寄存器在异常处理和特权操作时,可得到快速的上下文切换。
ARM状态下各模式寄存器
-
所有的37个寄存器,分成两大类:
-
31个通用32位寄存器;
-
6个状态寄存器
-
-
寄存器R13、R14分别有6个分组的物理寄存器。一个用于用户和系统模式,其余5个分别用于5种异常模式。
-
寄存器R13常作为堆栈指针(SP)。在ARM指令集当中,没有以特殊方式使用R13的指令或其它功能,只是习惯上都这样使用。但是在Thumb指令集中存在使用R13的指令。
-
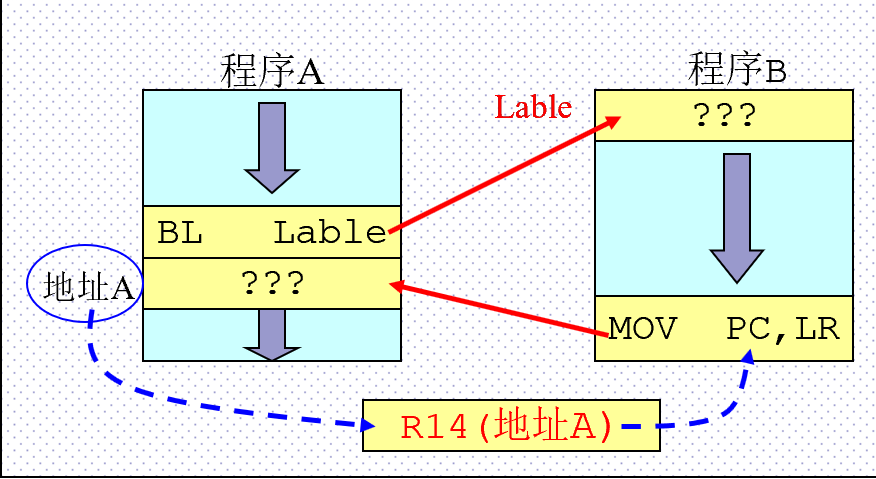
R14为链接寄存器(LR),在结构上有两个特殊功能:
-
在每种模式下,模式自身的R14版本用于保存子程序返回地址;
-
当发生异常时,该模式下的R14被设置成该异常模式将要返回的地址。
-
R14寄存器与子程序调用的操作流程:
-
程序A执行过程中调用程序B;
-
程序跳转至标号Lable,执行程序B。同时硬件将“BL Lable”指令的下一条指令所在地址存入R14;
-
程序B执行最后,将R14寄存器的内容放入PC,实现子程序返回,返回程序A;MOV PC, LR;
-
-
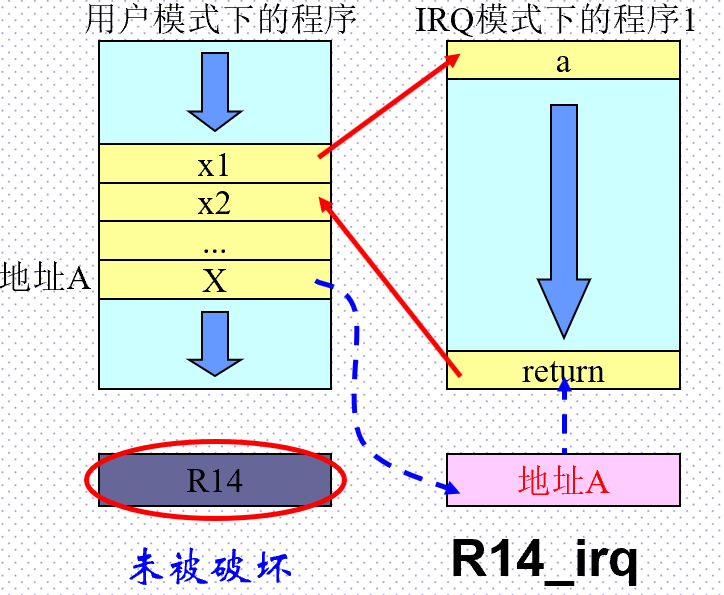
R14寄存器与异常发生
异常发生时,程序要跳转至异常服务程序,对返回地址的处理与子程序调用类似,都是由硬件完成的。
区别在于有些异常有一个小常量的偏移。
-
IRQ服务程序A执行完毕,将R14_irq寄存器的内容减去某个常量后存入PC,返回之前被中断的程序;
-
在程序B返回到程序A,然后在返回到用户模式下被中断的程序时,发生错误,将不能正确返回;
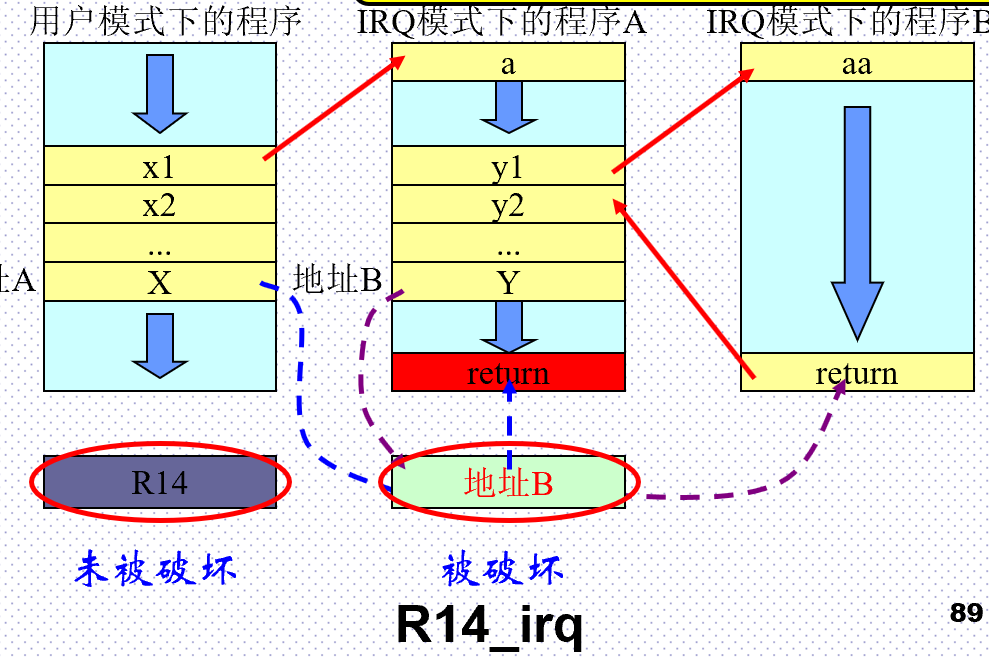
解决办法是确保R14的对应版本在发生中断嵌套时不再保存任何有意义的值(将R14入栈),或者切换到其它处理器模式下,或进入IRQ之后修改CPSR关闭使能位。
-
-
寄存器R15为程序计数器(PC),它指向正在取指的地址。
-
可以认为它是一个通用寄存器,但是对于它的使用有许多与指令相关的限制或特殊情况。
-
如果R15使用的方式超出了这些限制,那么结果将是不可预测的。
-
读取R15的限制
正常操作时,从R15读取的值是处理器正在取指的地址,即当前正在执行指令的地址加上8个字节(两条ARM指令的长度)。
由于ARM指令总是以字为单位,所以R15寄存器的最低两位总是为0。
-
写R15的限制
正常操作时,写入R15 的值被当作一个指令地址,程序从这个地址处继续执行(相当于执行一次无条件跳转)。
-
-
程序状态寄存器CPSR 为程序状态寄存器
- 在异常模式中,另外一个寄存器“程序状态保存寄存器(SPSR)”可以被访问。
- 每种异常都有自己的SPSR,在因为异常事件而进入异常时它保存CPSR的当前值,异常退出时可通过它恢复CPSR。
Thumb状态下的寄存器(32位)(不考)
Thumb状态下的寄存器集是ARM状态集的子集,程序员可以直接访问的寄存器为:
- 8个通用寄存器R0~R7;
- 程序计数器(PC);
- 堆栈指针(SP);
- 链接寄存器(LR);
- 有条件访问程序状态寄存器( CPSR)。
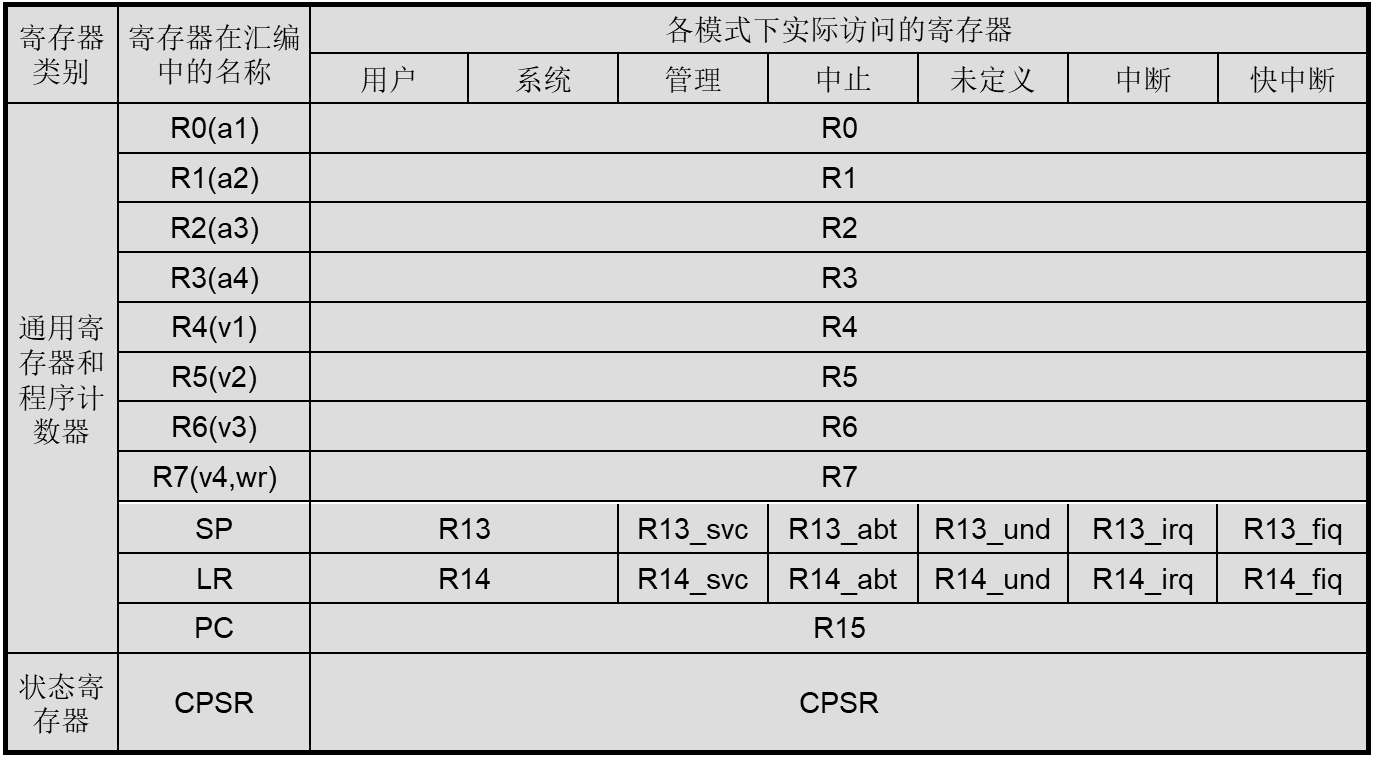
Thumb状态寄存器在Arm状态寄存器上的映射
程序状态寄存器—CPSR(1)+SPSR(5)
CPSR反映了当前处理器的状态:
- 4个条件码标志;
- 2个中断控制位;
- 5个对当前处理器模式进行编码的位;
- 1个指示当前执行指令的工作状态位;
- 保留位。
SPSR:备份程序状态字,保存异常事件发生之前的CPSR.
- 每个异常模式带有一个备份程序状态寄存器,用于保存在异常事件发生之前的CPSR;CPSR和SPSR通过特殊指令进行访问。

-
条件代码标志
- 大多数“数值处理指令”可以选择是否影响条件代码标志位(指令带S后缀);但有些指令执行总是影响条件代码标志。
- 所有ARM指令都可按条件来执行,而Thumb指令中只有分支指令可按条件执行。
- N:运算结果的最高位反映在N标志位。对于有符号二进制补码,结果为负数时N=1,结果为正数或零时N=0;
- Z:指令结果为0时Z=1(表示比较结果“相等”),否则Z=0;
- C:
- 当进行加法运算,并且最高位产生进位时C=0,否则C=1。
- 当进行减法运算,并且最高位产生借位时C=0,否则C=1。
- 对于移位操作指令,C为从最高位最后移出的值,其它指令C通常不变;
- V: 当进行加法运算,并且发生有符号溢出时V=1,否则V=0,其它指令V通常不变。
-
保留位
- 保留位被保留将来使用。为了提高程序的可移植性,当改变CPSR标志和控制位时,请不要改变这些保留位。另外,请确保程序的运行不受保留位的值影响,因为将来的处理器可能会将这些位设置为1或者0。
-
控制位
-
最低8位为控制位,当发生异常时,这些位被硬件改变。当处理器处于一个特权模式时,可用软件操作这些位。
-
CPSR模式位设置表
M[4:0] 模式 M[4:0] 模式 10000 用户 10111 中止 10001 快中断 11011 未定义 10010 中断 11111 系统 10011 管理 注意:不是所有模式位的组合都定义了有效的处理器模式,如果使用了错误的设置,将引起一个无法恢复的错误。
-
CPSR/SPSR的读写指令
状态寄存器访问指令MRS,MSR:
- MRS: 状态寄存器到通用寄存器的传送指令(读状态寄存器)
- MSR: 通用寄存器到状态寄存器的传送指令(写状态寄存器)
- MRS和MSR指令可以实现对状态寄存器的读、修改、写操作,即修改状态寄存器的值。
MRS R1, CPSR ;读取CPSR保存到通用寄存器R1
MSR CPSR, R1 ; 传送R1到CPSR
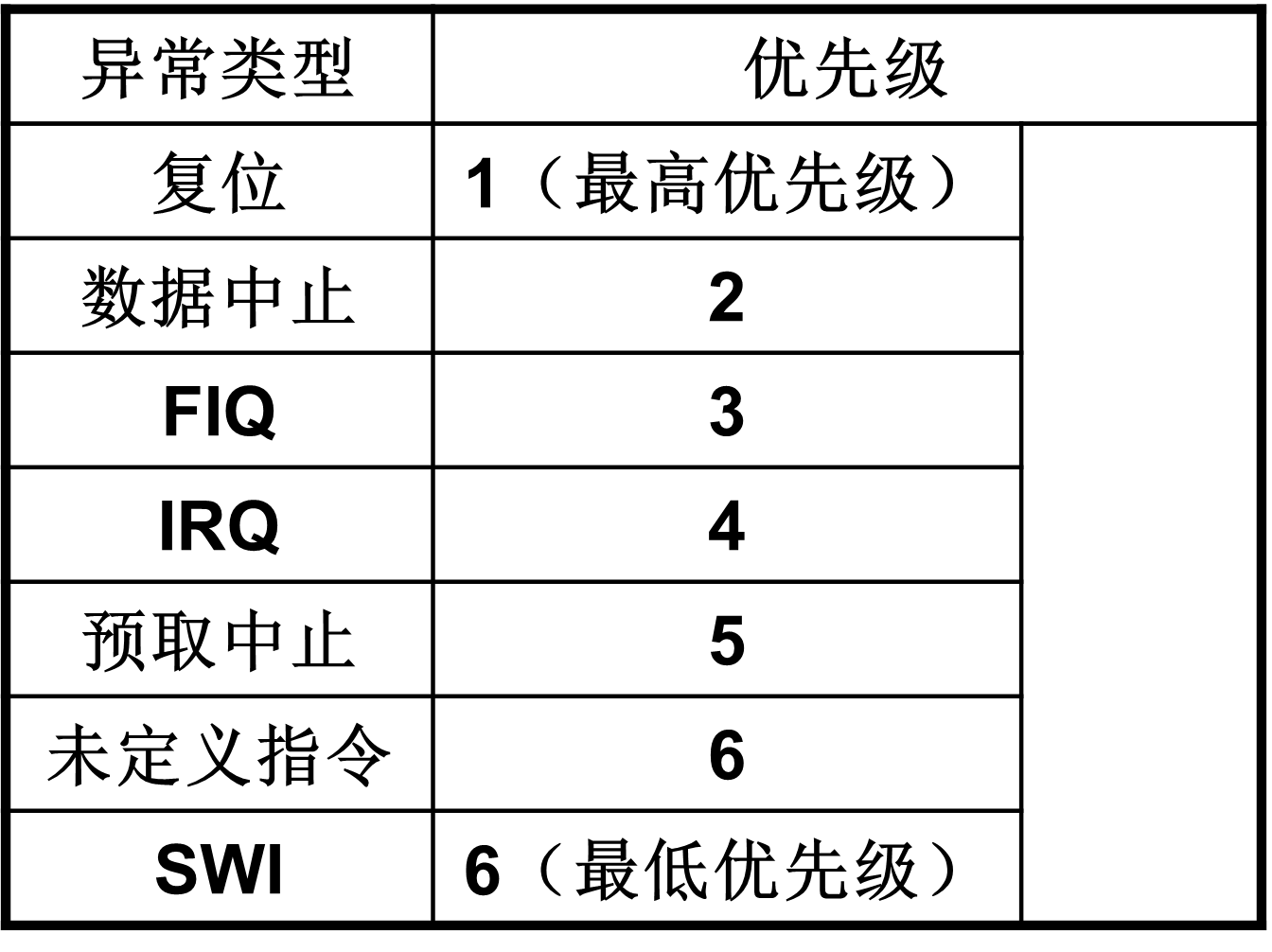
7. 五种异常模式,7 种异常类型,复位的向量地址 0x0,复位的优先级
异常:
只要正常的程序流被暂时中止,处理器就进入异常模式。
例如响应一个来自外设的中断。在处理异常之前,ARM7TDMI内核保存当前的处理器状态,这样当处理程序结束时可以恢复执行原来的程序。
如果同时发生两个或更多异常,那么将按照固定的顺序来处理异常,详见“异常优先级”部分。
异常处理模式
| 异常类型 | 模式 | 向量地址 |
|---|---|---|
| 复位 | 管理 | 0x00000000 |
| 未定义指令 | 未定义 | 0x00000004 |
| 软件中断(SWI) | 管理 | 0x00000008 |
| 预取中止(取指令存储器中止) | 中止 | 0x0000000C |
| 数据中止(数据访问存储器中止) | 中止 | 0x00000010 |
| IRQ(中断) | IRQ | 0x00000018 |
| FIQ(快速中断) | FIQ | 0x0000001C |
异常优先级
异常类型
- 复位:
- 当nRESET信号被拉低时(一般外部复位引脚电平的变化和芯片的其它复位源会改变这个内核信号),ARM7TDMI处理器放弃正在执行的指令。
- 当nRESET信号再次变为高电平时,ARM处理器执行下列操作:
- 强制M[4:0]变为b10011(管理模式);
- 置位CPSR中的I和F位;写入1,先禁止.
- 清零CPSR中的T位;写入0,处理器为arm状态。
- 强制PC从地址0x00开始进行取指;
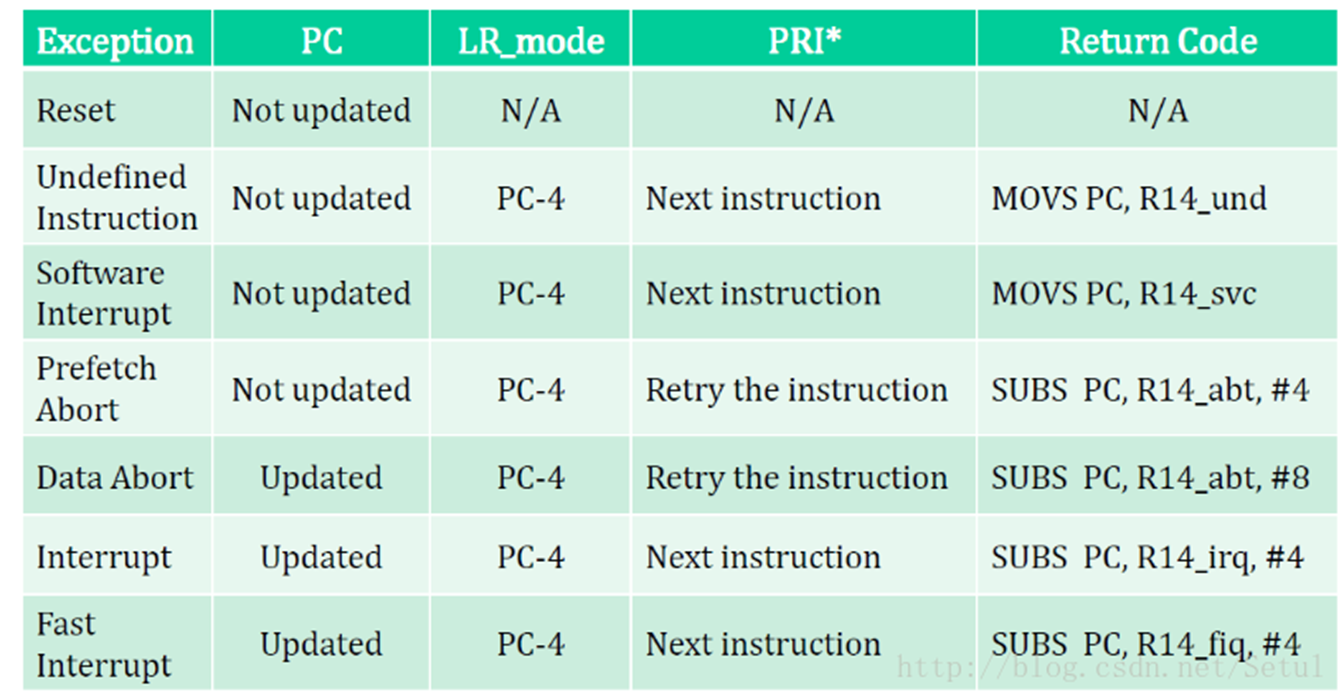
8. 异常进入、退出过程、7 种异常类型的返回地址
异常的入口和出口
如果异常处理程序已经把返回地址拷贝到堆栈,那么可以使用一条多寄存器传送指令来恢复用户寄存器并实现返回。
中断处理代码的开始部分和退出部分
SUB LR,LR,#4 ;计算返回地址(偏移-4) LR就是R14该模式下的R14被设置成该异常模式将要返回的地址 STMFD SP!,{R0-R3,LR} ;保存使用到的寄存器 这条指令将R0、R1、R2、R3和LR寄存器的内容保存到堆栈中。 . . . LDMFD SP!,{R0-R3,PC}^ ;中断返回 这条指令将R0、R1、R2、R3和PC寄存器的内容从堆栈中恢复。注意:
- 中断返回指令的寄存器列表(其中必须包括PC)后的“^”符号表示这是一条特殊形式的指令。这条指令在从存储器中装载PC的同时(PC是最后恢复的),CPSR也得到恢复。
- 这里使用的堆栈指针SP(R13)是属于异常模式的寄存器,每个异常模式有自己的堆栈指针。如R13_irq
- 这个堆栈指针应必须在系统启动时初始化。
- 指令末尾的“!”告诉汇编器,在寄存器被保存后,栈指针(SP)应该被更新。
进入异常
在异常发生后,ARM7TDMI内核会作以下工作:
-
在适当的LR中保存下一条指令的地址(R14_irq),当异常入口来自:
- ARM状态,那么ARM7TDMI将当前指令地址加4或加8复制(取决于异常的类型)到LR中
-
将CPSR复制到适当的SPSR(如SPSR_irq)中;
-
置位I位(禁止IRQ中断) 清零T位(进入ARM状态) 设置MOD位,切换处理器模式至IRQ模式
-
强制PC从相关的异常向量处取指。
注:
ARM7TDMI内核在中断异常时置位中断禁止标志(CPSR 第I位赋值=0x1),这样可以防止不受控制的异常嵌套。
异常总是在ARM状态中进行处理。当处理器处于Thumb状态时发生了异常,在异常向量地址装入PC时,会自动切换到ARM状态。
退出异常
除了复位异常外,其余的异常都需要返回。
当异常结束时,异常处理程序必须:
- 将SPSR(如SPSR_irq)的值复制回CPSR;
-
若在进入异常处理时设置了中断禁止标志(I/F位)则清零该标志。
- 将LR(如R14_irq)中的值减去偏移量后存入PC,偏移量根据异常的类型而有所不同;
假如指令A 是“BL”指令,则当执行该指令时,会把PC(=0x8008)保存到LR 寄存器里面,但是接下去处理器会马上对LR 进行一个自动的调整动作:LR=LR-0x4=PC-0x4
无论发生什么异常(除复位),内核总是会首先将 PC-4 放到LR寄存器中。
异常的类型
-
软件中断 SWI
-
使用软件中断(SWI)指令可以进入管理模式,通常用于请求一个特定的管理函数。
-
SWI处理程序通过执行下面的指令返回:
MOVS PC,R14_svc 这个动作恢复了PC和CPSR并返回到SWI之后的指令。
-
SWI处理程序读取操作码以提取SWI函数编号。
SWI 12 ;产生软中断,中断号为12 -
异常是由当前执行的指令本身(SWI 12)引起的, 当产生中断时,程序计数器PC的值还未更新(未更新的意思就是PC还没有加4,仍然为0x8008)
;LR_svc=PC-4=0x8004 MOVS PC,R14_svc;异常返回
-
-
未定义指令异常 UND
-
当ARM7TDMI处理器遇到一条自己和系统内任何协处理器都无法处理的指令时,ARM7TDMI内核执行未定义指令异常程序。
-
软件可使用这一机制通过模拟未定义的协处理器指令来扩展ARM指令集。
-
在模拟处理了失败的指令后,陷阱程序执行下面的指令:
MOVS PC,R14_und这个动作恢复了PC和CPSR并返回到未定义指令之后的指令。-
异常是由当前执行的指令自身(指令未定义)产生的,当产生中断时,程序计数器PC的值还未更新(未更新的意思就是PC还没有加4,PC=0x8008)
;LR_und=PC-4=0x8004 MOVS PC,R14_und返回指令计算与SWI一致
-
-
快速中断请求(FIQ)
快速中断请求(FIQ)适用于对一个突发事件的快速响应,这得益于在ARM状态中,快中断模式有8个专用的寄存器(R8-R15)可用来满足寄存器保护的需要(这可以加速上下文切换的速度)。
不管异常入口是来自ARM状态还是Thumb状态,FIQ处理程序都会通过执行下面的指令从中断返回:
SUBS PC,R14_fiq,#4在一个特权模式中,可以通过置位CPSR中的F位来禁止FIQ异常。
注意还要再减4 后面有提到
- 中断请求(IRQ)
中断请求(IRQ)异常是一个由nIRQ输入端的低电平所产生的正常中断(在具体的芯片中,nIRQ由片内外设拉低,nIRQ是内核的一个信号,对用户不可见)。
IRQ的优先级低于FIQ。进入FIQ处理时FIQ和IRQ都被禁。在一个特权模式下,可通过置位CPSR中的I 位来禁止IRQ。
不管异常入口是来自ARM状态还是Thumb状态,FIQ处理程序都会通过执行下面的指令从中断返回:
SUBS PC,R14_irq,#4IRQ或FIQ中断时的返回地址
指令不会被中断打断,A指令执行完以后才能响应中断,此时PC已更新,PC指向指令D的地址(地址0x800C),LR =PC-4保存的地址值是C 的地址0x8008。中断返回后应该执行B指令,所以返回操作是:
;快速中断的返回指令 SUBS PC,R14_fiq,#4 ;中断请求的返回指令 SUBS PC,R14_irq,#4FIQ为什么比IRQ快呢?
- FIQ比IRQ有更高优先级,如果FIQ和IRQ同时产生,那么FIQ先处理
- ARM的FIQ模式提供了更多的banked寄存器,R8,R9,R10,R11,R12,模式切换时CPU自动保存这些值到banked寄存器,退出FIQ模式时自动恢复
- FIQ的中断向量地址在0x0000001C,而IRQ的在0x00000018。这样可以直接在1C处放FIQ的中断处理程序,不需要跳转,所以响应速度快。
- IRQ和FIQ的中断响应延迟有区别,IRQ的响应并不及时,从Verilog仿真来看,IRQ会延迟几个指令周期才跳转到中断向量处

- 中止(ABT)
中止发生在对存储器的访问不能完成时,当出现异常后,要重新再执行一次这条指令,中止包含两种类型:
- 预取中止: 发生在指令预取过程中
- 数据中止: 发生在对数据访问时
预取中止
当发生预取中止时,ARM7TDMI内核将预取的指令标记为无效,但在指令到达流水线的执行阶段时才进入异常。
如果指令在流水线中因为发生分支而没有被执行,中止将不会发生。
在处理中止的原因之后,不管处于哪种处理器操作状态,处理程序都会执行下面的指令恢复PC和CPSR并重试被中止的指令:
SUBS PC,R14_abt,#4减4的原因。
预取异常是由于指令自身引起的,所以当产生中止时,程序计数器PC的值还未更新;
PC指向指令C的地址(地址0x8008),LR =PC-4保存的地址值是B 的地址0x8004。中断返回后应该执行A指令,所以返回操作是:
SUBS PC,R14_abt,#4要返回产生异常的指令,重新执行该指令
数据中止
在修复产生中止的原因后,不管处于哪种处理器操作状态,处理程序都必须执行下面的返回指令,这个动作恢复了PC和CPSR并重试被中止的指令:
SUBS PC,R14_abt,#8
返回减8的原因
数据访问异常中断由当前执行的指令在ALU里执行时产生,当数据访问异常中断发生时,程序计数器pc的值已经更新。 PC指向指令D的地址(地址0x800C),LR =PC-4保存的地址值是B 的地址0x8008。中断返回后应该执行A指令,所以返回操作是:
SUBS PC,R14_abt,#8
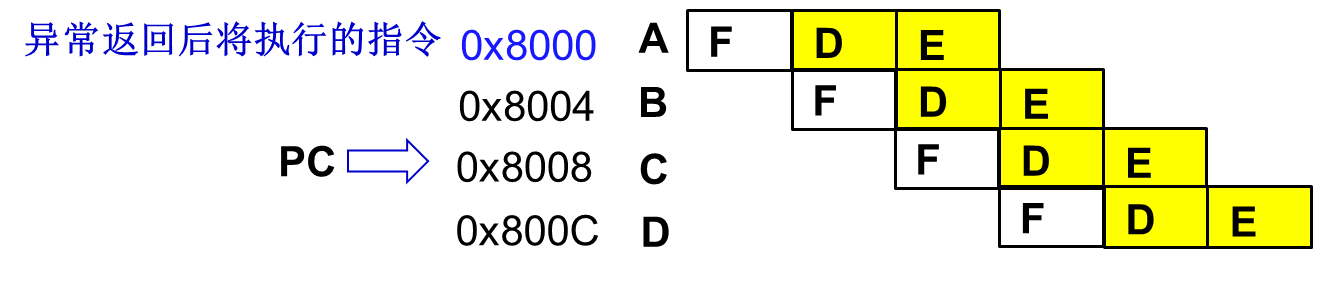
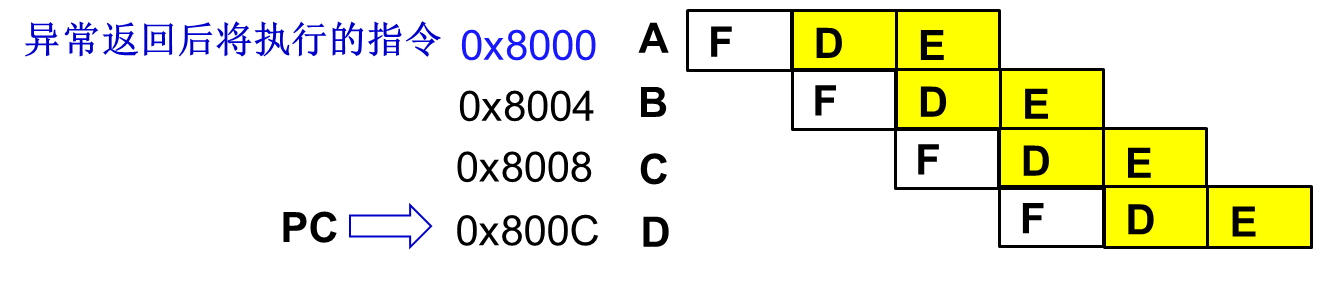
异常类型和返回的指令
第三章 ARM 指令集
arm指令概述
-
ARM微处理器是基于精简指令计算机(RISC)的原理设计的,指令集和相关译码机制比较简单。
-
ARM7系列微处理器具有32位的ARM指令集和16位的Thumb指令集:
-
ARM指令集效率高,但是代码密度低,占用较大的内存空间;
-
Thumb指令集属于ARM指令集的子集,具有较好的代码密度,功能简单。
-
-
所有的ARM指令都是可以有条件执行
-
而Thumb指令集只有一条指令(B)具有条件执行的功能。
-
ARM指令和Thumb指令可以相互调用,两者之间的状态切换所用的开销几乎为0。
1. 寻址方式的概念,及 9 种寻址方式(选择题,那种寻址方式)
寻址方式:处理器根据指令中给出的地址信息来寻找被操作对象的物理地址的方式。
ARM处理器具有9种基本寻址方式。
-
寄存器寻址
操作数的值在寄存器中,指令中的地址码字段指出的是寄存器编号,指令执行时直接取出寄存器值来操作。 寄存器寻址指令举例如下:
MOV R1,R2 ;将R2的值存入R1 SUB R0,R1,R2 ;将R1的值减去R2的值,结果保存到R0 -
立即寻址
立即寻址指令中的操作码字段后面的地址码部分即是操作数本身,也就是说,数据就包含在指令当中,取出指令也就取出了可以立即使用的操作数(这样的数称为立即数)。
立即寻址指令举例如下:
SUBS R0,R0,#1 ;R0减1,结果放入R0,并且影响标志位 MOV R0,#0xFF000 ;将立即数0xFF000装入R0寄存器 -
寄存器移位寻址
以寄存器寻址为本,将寄存器中的数移位后作为操作数。
寄存器移位寻址是ARM指令集特有的寻址方式。当第2个操作数是寄存器移位方式时,第2个寄存器操作数在与第1个操作数结合之前,选择进行移位操作。
寄存器移位寻址指令举例如下:
MOV R0,R2,LSL #3 ;R2的值左移3位,结果放入R0, ;即是R0=R2×8 ANDS R1,R1,R2,LSL R3 ;R2的值左移R3位,然后和R1相 ;“与”操作,结果放入R1LSL:逻辑左移(Logical Shift Left),寄存器中字的低端空出的位补0。
LSR:逻辑右移(Logical Shift Right),寄存器中字的高端空出的位补0。
ASL:算术左移(Arithmetic Shift Left),和逻辑左移LSL相同。
ASR:算术右移(Arithmetic Shift Right),移位过程中符号位不变,即如果源操作数是正数,则字的高端空出的位补0,否则补1。
ROR:循环右移(Rotate Right),由字的低端移出的位填入字的高端空出的位。
RRX:带扩展的循环右移(Rotate Right eXtended),操作数右移一位,高端空出的位用进位标志C的值来填充,低端移出的位填入进位标志位。
-
寄存器间接寻址
寄存器间接寻址指令中的地址码给出的是一个通用寄存器的编号,所需的操作数保存在寄存器指定地址的存储单元中,即寄存器为操作数的地址指针。
寄存器间接寻址指令举例如下:
LDR R1,[R2] ;将R2指向的存储单元的数据读出 ;保存在R1中 STR R1,[R0] -
基址寻址
基址寻址就是将基址寄存器的内容与指令中给出的偏移量相加,形成操作数的有效地址。
- LDR:加载指定位置32位数据到目标寄存器;(从固定地址处进行取值)
- STR:保存指定位置32位数据到目标位置;(给固定位置进行赋值)
- 与mov的区别 mov只能在寄存器之间或立即数与寄存器之间传输数据
基址寻址指令举例如下:
LDR R2,[R3,#0x0C] ;读取R3+0x0C地址上的存储单元的内容,放入R2 STR R1,[R0,#-4]! ;先R0-4,然后把R1的值保存到R0-4指定的存储单元 -
多寄存器寻址
多寄存器寻址一次可传送几个寄存器值,允许一条指令传送16个寄存器的任何子集或所有寄存器。 多寄存器寻址指令举例如下:
LDMIA R1!,{R2-R7,R12} ;将R1指向的单元中的数据读出到 ;R2~R7、R12中(R1自动加4) STMIA R0!,{R2-R7,R12} ;将寄存器R2~R7、R12的值保 ;存到R0指向的存储; 单元中 ;(R0自动加4)使用多寄存器寻址指令时,寄存器子集的顺序是按由小到大的顺序排列,连续的寄存器可用“-”连接;否则用“,”分隔书写。
-
堆栈寻址
堆栈即Stack,因为CPU的寄存器总是及其有限的,很多时候我们不得不使用内存来存储数据,比如进行多级跳转的时候,这时候堆栈就是一个很好的工具,每次跳转就将当前函数的返回地址存储到内存,最底层被调用的子函数会最先返回,就先将压入栈的现场返回,以此类推…,ARM使用SP(R13)作为栈指针,ARM设计的内存栈模型有2×2=4种
按照栈在内存增长的方向分为递增栈和递减栈 :
-
递增(Increase) 堆栈:向堆栈写入数据时,堆栈由低地址向高地址生长。
-
递减(Descend) 堆栈:向堆栈写入数据时,堆栈由高地址向低地址生长。
根据堆栈指针SP指向的位置,又可以把堆栈分为满堆栈和空堆栈两种。
-
满堆栈(Full Stack):SP始终指向栈顶元素,压栈的时候先移动SP,再将数据放入SP指向的地址。
-
空堆栈(Empty Stack):SP始终指向下一个将要放入元素的位置,压栈时先将数据放入SP指向的地址,再移动SP
-
F: full
- E:empty
- A:Ascending
- D:Descending
- LDM:(load much)多数据加载,将地址上的值加载到寄存器上
- STM:(store much)多数据存储,将寄存器的值存到地址上
最后,可以得到4种基本的堆栈类型:
- 满递增:堆栈向上增长,堆栈指针指向含有效数据项的最高地址。指令如LDMFA、STMFA等;
- 空递增:堆栈向上增长,堆栈指针指向堆栈上的第一个空位置。指令如LDMEA、STMEA等;
- 满递减:堆栈向下增长,堆栈指针指向内含有效数据项的最低地址。指令如LDMFD、STMFD等;
- 空递减:堆栈向下增长,堆栈指针向堆栈下的第一个空位置。指令如LDMED、STMED等。
stmfd sp!, {r1-r7, lr} ;将r1到r7和lr的数据压入fd栈 -
-
块拷贝寻址
-
IB:Increment Before Operating
-
IA:Increment After Operating
-
DB:Decrement Before Operating
-
DA:Decrement After Operating
块拷贝寻址方式使用多寄存器传送指令将数据块从存储器的某一位置拷贝到另一位置。 如:
STMIA R0!,{R1-R7} ;将R1~R7的数据保存到存储器中。 ;存储指针在保存第一个值之后增加, ;增长方向为向上增长。 STMIB R0!,{R1-R7} ;将R1~R7的数据保存到存储器中。 ;存储指针在保存第一个值之前增加, ;增长方向为向上增长。 -
-
相对寻址
[!tip]
相对寻址是基址寻址的一种变通。
- 由程序计数器PC提供基准地址,
- 指令中的地址码字段作为偏移量,
- 两者相加后得到的地址即为操作数的有效地址
;例子 BL SUBRl ;调用到SUBRl子程序 . . . SUBR1: . . . MOV PC,R14 ;返回
2. ARM 指令集,掌握常用的指令、指令格式、第 2 个操作数(立即数、寄存器、寄存器移位)
指令格式
<opcode> {<cond>} {S} <Rd> ,<Rn>{,<operand2>}
其中<>号内的项是必须的,{ }号内的项是可选的。各项的说明如下:
-
opcode:指令助记符;
-
cond:执行条件;
[!IMPORTANT]
使用条件码“cond”可以实现高效的逻辑操作,提高代码效率。
-
所有的ARM指令都可以条件执行,
-
而Thumb指令只有B(跳转)指令具有条件执行 功能。如果指令不标明条件代码,将默认为无条件(AL)执行。
-
指令条件码表
-
操作码 条件助记符 标志 含义 0000 EQ Z=1 相等 0001 NE Z=0 不相等 0010 CS/HS C=1 无符号数大于或等于 0011 CC/LO C=0 无符号数小于 0100 MI N=1 负数 0101 PL N=0 正数或零 0110 VS V=1 溢出 0111 VC V=0 没有溢出 1000 HI C=1,Z=0 无符号数大于 1001 LS C=0,Z=1 无符号数小于或等于 1010 GE N=V 有符号数大于或等于 1011 LT N!=V 有符号数小于 1100 GT Z=0,N=V 有符号数大于 1101 LE Z=1,N!=V 有符号数小于或等于 1110 AL 任何 无条件执行 (指令默认条件) 1111 NV 任何 从不执行(不要使用)
-
-
S:是否影响CPSR寄存器的值;
-
Rd:目标寄存器;
-
Rn:第1个操作数的寄存器;
-
operand2:第2个操作数;
[!tip]
灵活地使用第2个操作数“operand2”能够提高代码效率。 operand2”有如下的形式:
-
#immed_8r ——常数表达式;
;【例】 MOV R0,#1 ;R0 ←1 AND R1,R2,#0x0F ;R2与0x0F,结果保存在R1 LDR R0,[R1],#-4 ;读取R1地址上的存储器单元内容, ;赋值给R0, ;传送完成后 R1← R1-4,后变址 -
Rm ——寄存器方式;
;【例】 在寄存器方式下,操作数即为寄存器的数值。 SUB R1,R1,R2 ; R1-R2→R1 LDR R0,[R1],-R2 ;先将R1指向内存中的数存入R0 ; 之后,R1 ← R1- R2 ; 后变址的方式 -
Rm, shift ——寄存器移位方式;
将寄存器的移位结果作为操作数,但Rm值保持不变,移位方法如下:
操作码 说明 操作码 说明 ASR #n 算术右移n位 ROR #n 循环右移n位 LSL #n 逻辑左移n位 RRX 带扩展的循环右移1位 LSR #n 逻辑右移n位 - 算术左移与逻辑左移是一样的!
;寄存器偏移方式应用举例: ADD R1,R1,R1,LSL #3 ;R1=R1×8 SUB R1,R1,R2,LSR #2 ;R1=R1-R2÷4
-
;例子
LDR R0,[R1] ;读取R1地址上的存储器单元内容,执行条件AL (无条件)
BEQ D1 ;分支指令,执行条件EQ,即相等则跳转到D1标号
ADDS R1,R1,#1 ;加法指令,R1+1 → R1,影响CPSR
SUBNES R1,R1,#0x10 ;条件执行减法运算(NE),R1 – 0x10 → R1,影响CPSR
条件码(常用的条件码的助记符,如等于,不等于,大于,小于等)
使用条件码“cond”可以实现高效的逻辑操作,提高代码效率。
-
所有的ARM指令都可以条件执行,
-
而Thumb指令只有B(跳转)指令具有条件执行 功能。如果指令不标明条件代码,将默认为无条件(AL)执行。
-
指令条件码表
| 操作码 | 条件助记符 | 标志 | 含义 | |
|---|---|---|---|---|
| 0000 | EQ | Z=1 | 相等 | |
| 0001 | NE | Z=0 | 不相等 | |
| 0010 | CS/HS | C=1 | 无符号数大于或等于 | |
| 0011 | CC/LO | C=0 | 无符号数小于 | |
| 0100 | MI | N=1 | 负数 | |
| 0101 | PL | N=0 | 正数或零 | |
| 0110 | VS | V=1 | 溢出 | |
| 0111 | VC | V=0 | 没有溢出 | |
| 1000 | HI | C=1,Z=0 | 无符号数大于 | |
| 1001 | LS | C=0,Z=1 | 无符号数小于或等于 | |
| 1010 | GE | N=V | 有符号数大于或等于 | |
| 1011 | LT | N!=V | 有符号数小于 | |
| 1100 | GT | Z=0,N=V | 有符号数大于 | |
| 1101 | LE | Z=1,N!=V | 有符号数小于或等于 | |
| 1110 | AL | 任何 | 无条件执行 (指令默认条件) | |
| 1111 | NV | 任何 | 从不执行(不要使用) |
单寄存器存取指令(LDR,STR)
-
ARM处理器是典型的RISC处理器,对存储器的访问只能使用加载和存储指令实现。
- 冯•诺依曼存储结构,程序空间、RAM空间及I/O映射空间统一编址,除对RAM操作以外,对外围IO、程序数据的访问均要通过加载/存储指令进行。
- 存储器访问指令分为单寄存器操作指令和多寄存器操作指令。
单寄存器操作指令
| 助记符 | 说明 | 操作 | 条件码位置 |
|---|---|---|---|
| LDR Rd,addressing | 加载字数据 | Rd←[addressing],addressing索引 | LDR{cond} |
| LDRB Rd,addressing | 加载无符号字节数据 | Rd←[addressing],addressing索引 | LDR{cond}B |
| LDRT Rd,addressing | 以用户模式加载字数据 | Rd←[addressing],addressing索引 | LDR{cond}T |
| LDRBT Rd, addressing | 以用户模式加载无符号字节数据 | Rd←[addressing],addressing索引 | LDR{cond}BT |
| LDRH Rd, addressing | 加载无符号半字数据 | Rd←[addressing],addressing索引 | LDR{cond}H |
| LDRSB Rd, addressing | 加载有符号字节数据 | Rd←[addressing],addressing索引 | LDR{cond}SB |
| LDRSH Rd, addressing | 加载有符号半字数据 | Rd←[addressing],addressing索引 | LDR{cond}SH |
[!NOTE]
LDRSB, LDRSH加载后高位需要填充符号位!
| 助记符 | 说明 | 操作 | 条件码位置 |
|---|---|---|---|
| STR Rd, addressing | 存储字数据 | [addressing]←Rd, addressing索引 | STR{cond} |
| STRB Rd,addressing | 存储字节数据 | [addressing]←Rd, addressing索引 | STR{cond}B |
| STRT Rd,addressing | 以用户模式存储字数据 | [addressing]←Rd, addressing索引 | STR{cond}T |
| STRBT Rd,addressing | 以用户模式存储字节数据 | [addressing]←Rd, addressing索引 | STR{cond}BT |
| STRH Rd,addressing | 存储半字数据 | [addressing] ←Rd, addressing索引 | STR{cond}H |
LDR/STR指令用于对内存变量的访问、内存缓冲区数据的访问、外围部件的控制操作等。若使用LDR指令加载数据到PC寄存器,则实现程序跳转功能,这样也就实现了程序跳转。
[!NOTE]
说明:
所有单寄存器加载/存储指令可分为“字和无符号字节加载存储指令”
“半字和有符号字节加载存储指令。
LDR和STR——(1)字和无符号字节加载/存储指令
LDR/STR指令寻址非常灵活,它由两部分组成,其中一部分为一个基址寄存器,可以为任一个通用寄存器;另一部分为一个地址偏移量。地址偏移量有以下3种格式:
立即数:立即数可以是一个无符号的数值。这个数据可以加到基址寄存器,也可以从基址寄存器中减去这个数值。
;【例】 LDR R1,[R0,#0x12] ;将R0+0x12地址处的数据读出,保存到Rl中(R0的值不变) LDR R1,[R0,# -0x12] ;将R0-0x12地址处的数据读出,保存到R1中(R0的值不变)寄存器:寄存器中的数值可以加到基址寄存器,也可以从基址寄存器中减去这个数值。
【;例】 LDR R1,[R0,R2] ;将R0+R2地址处的数据读出,保存到R1中 LDR R1,[R0,-R2] ;将R0-R2地址处的数据读出,保存到R1中寄存器及移位常数:寄存器移位后的值可以加到基址寄存器,也可以从基址寄存器中减去这个数值。
;【例】 LDR R1,[R0,R2,LSL #2] ;将R0+R2×4地址处的数据读出,保存到R1中(R0、R2的值不变) LDR R1,[R0,-R2,LSL #2];将R0-R2×4地址处的数据读出,保存到R1中(R0、R2的值不变)
单寄存器存取指令:前变址 vs 后变址
从寻址方式的地址计算方法分,加载/存储指令有以下3种格式:
- 零偏移: 如:LDR Rd,[Rn]
- 前索引偏移(前变址):如:LDR Rd,[Rn,#0x04]!
- 后索引偏移(后变址):如:LDR Rd,[Rn],#0x04
根据数据传输传输的时机以及在指令执行后基址寄存器是否被更新,寄存器变址有前变址、回写前变址和后变址暗中方式。
前变址:
执行指令的时候,如果先进行变址运算,后传递数据,那么这种方式就是前变址方式。如图1所示
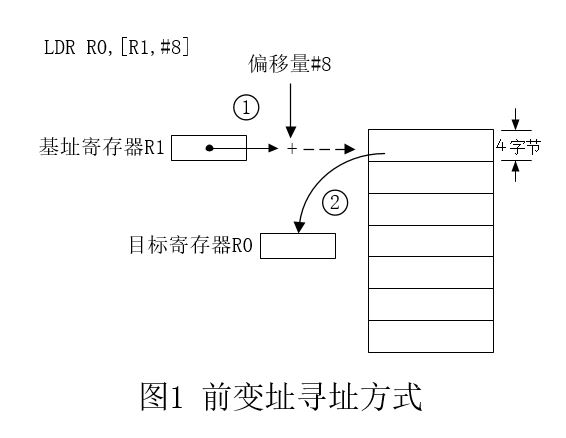
例子:
LDR R0,[R1,R2] ;R0<-((R1)+(R2))
LDR R0,[R1,#8] ;R0<-((R1)+8)
后变址
与上面相反,先传输数据,后进行变址的运算的方式叫做后变址方式,从指令格式上来看,后变址指令的格式如下:
LDR R0,[R1],#8 ;R0<-((R1)) R1<-((R1)+#8)
即将偏移量写在了方括号外边。后变址指令的执行过程如图2。
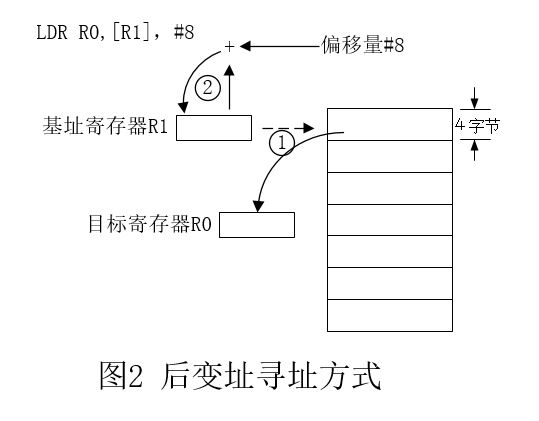
单寄存器存取指令:半字和有符号字节
这类LDR/STR指令可加载有符号半字或字节,可加载/存储无符号半字。偏移量格式、寻址方式与加载/存储字和无符号字节指令相同。
LDR{cond}SB Rd,<地址> ;将指定地址上的有符号字节读入Rd
LDR{cond}SH Rd,<地址> ;将指定地址上的有符号半字读入Rd
LDR{cond}H Rd,<地址> ;将指定地址上的半字数据读入Rd
STR{cond}H Rd,<地址> ;将Rd中的半字数据存入指定地址
[!NOTE]
注意: 1.有符号位半字/字节加载是指用符号位加载扩展到32位, 无符号半字加载是指用零扩展到32位; 2.地址对齐——半字读写的指定地址必须为偶数,否则将产生不可靠的结果。
例子
;【例】
LDRSB R1,[R0,R3] ;将R0+R3地址上的字节数据读到R1,高24位用符号位扩展
LDRSH R1,[R9] ;将R9地址上的半字数据读出到R1,高16位用符号位扩展
LDRH R6,[R2],#2;将R2地址上的半字数据读出到R6,高16位用零扩展,R2=R2+2,后变址方式
STRH R1,[R0,#2]! ;将R1的数据保存到R0+2地址中,只存储低2字节数据,R0=R0+2,前变址方式
多寄存器加载指令(LDM,STM)
LDM和STM指令可以实现在一组寄存器和一块连续的内存单元之间传输数据。
LDM为加载多个寄存器;
STM为存储多个寄存器。
允许一条指令传送16个寄存器的任何子集或所有寄存器。
;指令格式如下:
LDM{cond}<模式> Rn{!},reglist{^}
STM{cond}<模式> Rn{!},reglist{^}
[!tip]
LDM和STM的主要用途是现场保护、数据复制、常数传递等
注意Rn此处没有[ ],但仍然指向内存
指令格式中,寄存器Rn为基址寄存器,装有传送数据的初始地址,Rn不允许为R15。
后缀“!”表示最后的地址写回到Rn中。
寄存器列表reglist可包含多于一个寄存器或包含寄存器范围,使用“,”分开,如{R1,R2,R6-R9},寄存器按由小到大排列。
后缀“^”不允许在用户模式或系统模式下使用。
若在LDM指令且寄存器列表中包含有PC时使用”^”,那么除了正常的多寄存器传送外,将SPSR也拷贝到CPSR中,这可用于异常处理返回。
使用后缀“^”进行数据传送且寄存器列表不包含PC时,加载/存储的是用户模式的寄存器,而不是当前异常模式的寄存器。
| 模式 | 说明 | 模式 | 说明 |
|---|---|---|---|
| IA | 每次传送后地址加4 | FD | 满递减堆栈 |
| IB | 每次传送前地址加4 | ED | 空递减堆栈 |
| DA | 每次传送后地址减4 | FA | 满递增堆栈 |
| DB | 每次传送前地址减4 | EA | 空递增堆栈 |
| 数据块传送操作 | 堆栈操作 |
[!important]
进行数据复制时,先设置好源数据指针和目标指针,然后使用块拷贝寻址指令LDMIA/STMIA、LDMIB/STMIB、LDMDA/STMDA、LDMDB/STMDB进行读取和存储 。
进行堆栈操作操作时,要先设置堆栈指针(SP),然后使用堆栈寻址指令STMFD/LDMFD 、STMED/LDMED、STMFA/LDMFA和STMEA/LDMEA实现堆栈操作。
例子:
;【例】
LDMIA R0!,{R3 - R9};加载R0指向地址上的多字数据,保存到R3~R9中,R0值更新,增量后
STMIA R1!,{R3 - R9};将R3~R9的数据存储到R1指向的地址上,R1值更新,增量后
STMFD SP!,{R0 - R7,LR} ;现场保存,将R0~R7、LR入栈 从右往左压,先压LR,满递减
LDMFD SP!,{R0 - R7,PC} ;恢复现场,异常处理返回 弹出从左往右,先弹出R0,满递减
寄存器和存储器交换指令
SWP指令用于将一个内存单元(该单元地址放在寄存器Rn中)的内容读取到一个寄存器Rd中,同时将另一个寄存器Rm的内容写入到该内存单元中。 指令格式如下:

SWP{cond}{B} Rd,Rm,[Rn]
[!tip]
B为可选后缀,若有B,则交换字节,否则交换32位字;
- Rd用于保存从存储器中读入的数据;
- Rm的数据用于存储到存储器中,
- 若Rm与Rd相同,则为寄存器与存储器内容进行交换;
- Rn为要进行数据交换的存储器地址,Rn不能与Rd和Rm相同。
例子:
;【例】
SWP R1,R1,[R0] ;将R1的内容与R0指向的存储单元的内容进行交换
SWPB R1,R2,[R0] ;将R0指向的存储单元内的容读取一字节数据到R1中
;(高24位清零),并将R2的内容写入到该内存单元中
;(最低字节有效) ,只写R2的最低8位给内存
数据处理指令(数据传送指令 MOV, MVN,算术逻辑运算指令 ADD, SUB 等,比较指令 CMP, CMN,TST 等)
数据处理指令大致可分为3类:
- 数据传送指令;
- 算术逻辑运算指令;
- 比较指令。
[!warning]
- 数据处理指令只能对寄存器的内容进行操作,而不能对内存中的数据进行操作。
- 所有ARM数据处理指令均可选择使用S后缀,并影响状态标志。
- 比较指令CMP、CMN、TST和TEQ不需要后缀S,它们会直接影响状态标志。
数据传送指令
| 助记符 | 说明 | 操作 | 条件码位置 |
|---|---|---|---|
| MOV Rd,operand2 | 数据传送 | Rd←operand2 | MOV{cond}{S} |
| MVN Rd,operand2 | 数据非传送 | Rd←(~operand2) | MVN{cond}{S} |
MOV指令将立即数或寄存器传送到目标寄存器(Rd),可用于移位运算等操作。指令格式如下:
MOV{cond}{S} Rd,operand2
例子:
;MOV指令举例如下:
MOVS R3,R1,LSL #2 ;R3=R1<<2,并影响NZC标志位
MOV PC,LR ;PC=LR,子程序返回
MOV R4,#0x80 ;R4 0x80
MVN指令将立即数或寄存器(operand2)按位取反后传送到目标寄存器(Rd),因为其具有取反功能,所以可以装载范围更广的立即数。指令格式如下:
MVN{cond}{S} Rd,operand2
;MVN指令举例如下:
MVN R1,#0xFF ;R1← 0xFFFFFF00
MVN R1,R2 ;将R2取反,结果存到R1
MVNS R3,R1,LSL #2 ;R3←(R1<<2)取反并影响NZC标志位
算术运算
| 助记符 | 说明 | 操作 | 条件码位置 |
|---|---|---|---|
| ADD Rd,Rn,operand2 | 加法运算指令 | Rd←Rn+operand2 | ADD{cond}{S} |
| SUB Rd, Rn,operand2 | 减法运算指令 | Rd←Rn-operand2 | SUB{cond}{S} |
| RSB Rd, Rn, operand2 | 逆向减法指令 | Rd←operand2-Rn | RSB{cond}{S} |
| ADC Rd, Rn,operand2 | 带进位加法 | Rd←Rn+operand2+Carry | ADC{cond}{S} |
| SBC Rd, Rn,operand2 | 带进位减法指令 | Rd←Rn-operand2-(NOT)Carry | SBC{cond}{S} |
| RSC Rd, Rn,operand2 | 带进位逆向减法指令 | Rd←operand2-Rn-(NOT)Carry | RSC{cond}{S} |
应用示例:
ADDS R1,R1,#1 ;R1←R1+1,并影响标志位
ADDS R3,R1,R2,LSL #2 ; R3←R1+R2<<2
ADDS R3,R1,R2 ; R3←R1+R2
SUBS R0,R0,#1 ;R0←R0-1
SUB R6,R7,#0x10 ; R6←R7-0x10
RSB R3,R1,#0xFF00 ;R3=0xFF00-R1
RSBS R1,R2,R2,LSL #2 ;R1=(R2<<2)-R2=R2×3
ADDS R0,R0,R2 ;使用ADC实现64位加法
ADC R1,R1,R3 ;(R1、R0)=(R1、R0)+(R3、R2)
SUBS R0,R0,R2 ;使用SBC实现64位减法
SBC R1,R1,R3 ; (R1、R0)=(R1、R0)-(R3、R2)
RSBS R2,R0,#0
RSC R3,R1,#0 ;使用RSC指令实现求64位数值的负数
逻辑运算指令
| 助记符 | 说明 | 操作 | 条件码位置 |
|---|---|---|---|
| AND Rd, Rn, operand2 | 逻辑与操作指令 | Rd←Rn & operand2 | AND{cond}{S} |
| ORR Rd, Rn, operand2 | 逻辑或操作指令 | Rd←Rn | operand2 | ORR{cond}{S} |
| EOR Rd, Rn, operand2 | 逻辑异或操作指令 | Rd←Rn ^ operand2 | EOR{cond}{S} |
| BIC Rd, Rn, operand2 | 位清除指令 | Rd←Rn & (~operand2) | BIC{cond}{S} |
例子:
ANDS R0,R0,#0x01 ;R0←R0&0x01,取出最低位数据
AND R2,R1,R3 ;R2←R1&R3
ORR R0,R0,#0x0F ;将R0的低4位置1,其它4位不变
EOR R1,R1,#0x0F ;将R1的低4位取反,其它位不变
EORS R0,R5,#0x01 ; 将R5和0x01进行逻辑异或,
;结果保存到R0,并影响标志位
BIC R1,R1,#0x0F ;将R1的低4位清零,其它28位不变
比较指令
| 助记符 | 说明 | 操作 | 条件码位置 |
|---|---|---|---|
| CMP Rn, operand2 | 比较指令 | 标志N、Z、C、V ←Rn-operand2 | CMP{cond} |
| CMN Rn, operand2 | 负数比较指令 | 标志N、Z、C、V←Rn+operand2 | CMN{cond} |
| TST Rn, operand2 | 位测试指令 | 标志N、Z、C、V←Rn & operand2 | TST{cond} |
| TEQ Rn, operand2 | 相等测试指令 | 标志N、Z、C、V←Rn ^ operand2 | TEQ{cond} |
[!tip]
没有目的操作数,只用作更新条件标志位,不保存运算结果,指令后缀无需加S
Z:指令结果为0时Z=1,表示比较结果相等;否则Z=0;
C:指令有借位C=0 否则C=1,有仅为C=1,否则C=1
注意:
- CMP指令与SUBS指令的区别在于CMP指令不保存运算结果。
- CMN指令与ADDS指令的区别在于CMN指令不保存运算结果。
- TST指令与ANDS指令的区别在于TST指令不保存运算结果。
- TST指令通常与EQ、NE条件码配合使用,当所有测试位均为0时,EQ有效,而只要有一个测试位不为0,则NE有效。
- TEQ指令与EORS指令的区别在于TEQ指令不保存运算结果。使用TEQ进行相等测试时,常与EQ、NE条件码配合使用。当两个数据相等时,EQ有效;否则NE有效。
例子
CMP R1,#10 ; R1与10比较,设置相关标志位
CMN R0,#1 ;R0+1,判断相加结果时候为0,若是, 则Z位置1。
TST R0,#0x01 ; 判断R0的最低位是否为0
TST R1,#0x0F ; 判断R1的低4位是否为0
TEQ R0,R1 ; 比较R0与R1是否相等 (不影响V位和C位)
乘法指令(MUL,MLA 等)
ARM7TDMI具有三种乘法指令,分别为:
- 32×32位乘法指令;
- 32× 32位乘加指令;
- 32× 32位结果为64位的乘/乘加指令。
| 助记符 | 说明 | 操作 | 条件码位置 |
|---|---|---|---|
| MUL Rd,Rm,Rs | 32位乘法指令 | Rd←Rm*Rs (Rd≠Rm) | MUL{cond}{S} |
| MLA Rd,Rm,Rs,Rn | 32位乘加指令 | Rd←Rm*Rs+Rn (Rd≠Rm) | MLA{cond}{S} |
| UMULL RdLo,RdHi,Rm,Rs | 64位无符号乘法指令 | (RdHi,RdLo) ←Rm*Rs | UMULL{cond}{S} |
| UMLAL RdLo,RdHi,Rm,Rs | 64位无符号乘加指令 | (RdHi,RdLo) ←Rm*Rs+(RdHi,RdLo) | UMLAL{cond}{S} |
| SMULL RdLo,RdHi,Rm,Rs | 64位有符号乘法指令 | (RdHi,RdLo) ←Rm*Rs | SMULL{cond}{S} |
| SMLAL RdLo,RdHi,Rm,Rs | 64位有符号乘加指令 | (RdHi,RdLo) ←Rm*Rs+(RdHi,RdLo) | SMLAL{cond}{S} |
[!tip]
- 32位乘法指令,乘法操作的结果为32位
- 64位乘法指令,乘法操作的结果为64位
- S决定指令的操作是否影响CPSR的N和Z位的值
应用示例
MUL R1,R2,R3 ;R1=R2×R3
MULS R0,R3,R7 ;R0=R3×R7,同时影响CPSR中的N位和Z位
MLA R1,R2,R3,R0 ; R1=R2×R3+R0
UMULL R0,R1,R5,R8 ; (R1、R0)=R5×R8
UMLAL R0,R1,R5,R8 ;(R1、R0)=R5×R8+(R1、R0)
SMULL R2,R3,R7,R6 ; (R3、R2)=R7×R6
SMLAL R2,R3,R7,R6 ; (R3、R2)=R7×R6+(R3、R2)
分支指令(B,BL,BX)
[!tip]
在ARM中有两种方式可以实现程序的跳转:
一种是使用分支指令直接跳转,向前或向后32MB
另一种则是直接向PC寄存器赋值实现跳转,4GB
分支指令有以下三种:
- 分支指令B;
- 带链接的分支指令BL;
- 带状态切换的分支指令BX。
| 助记符 | 说明 | 操作 | 条件码位置 |
|---|---|---|---|
| B label | 分支指令 | PC←label | B{cond} |
| BL label | 带链接的分支指令 | LR←PC-4,PC←label | BL{cond} |
| BX Rm | 带状态切换的分支指令 | PC←label,切换处理器状态 | BX{cond} |
[!important]
带链接的分支指令——BL指令适用于子程序调用,使用该指令后,下一条指令的地址被拷贝到R14(即LR) 中,然后跳转到指定地址运行程序。跳转范围限制在当前指令的±32M字节地址内。指令格式如下:
BL{cond} Label 带状态切换的分支指令——BX指令,该指令可以根据跳转地址(Rm)的最低位来切换处理器状态,bit[0]=0为ARM状态,否则为Thumb状态。其跳转范围限制在当前指令的±32M字节地址内(ARM指令为字对齐,最低2位地址固定为0)。指令格式如下:
BX{cond} Rm
跳转地址Rm[0] 跳转后 CPSR标志T位 处理器状态 0 0 ARM 1 1 Thumb
应用示例
B WAITA ; 跳转到WAITA标号处
ADRL R0,ThumbFun+1 ;将Thumb程序的入口地址加1 ;存入R0(ADRL地址读取伪指令)
BX R0 ;跳转到R0指定的地址,并根据R0的最低位来切换处理器状态
杂项指令(MRS,MSR)
ARM指令集中有三条指令作为杂项指令,实际上这三条指令非常重要。
| 助记符 | 说明 | 操作 | 条件码位置 |
|---|---|---|---|
| SWI immed_24 | 软中断指令 | 产生软中断,处理器进入管理模式 | SWI{cond} |
| MRS Rd,psr | 读状态寄存器指令 | Rd←psr,psr为CPSR或SPSR | MRS{cond} |
| MSR psr_fields, Rd/#immed_8r | 写状态寄存器指令 | psr_fields←Rd/#immed_8r,psr为 CPSR或SPSR | MSR{cond} |
[!important]
SWI指令用于产生软中断,从而实现从用户模式变换到管理模式,并且将CPSR保存到管理模式的SPSR中,然后程序跳转到SWI异常入口。 在其它模式下也可使用SWI指令,处理器同样地切换到管理模式。
在SWI异常中断处理程序中,取出SWI指令的中断立即数的步骤为:
- 首先确定引起软中断的SWI指令是ARM指令还是Thumb指令,这可通过对SPSR访问得到;
- 然后取得该SWI指令的地址,这可通过访问LR寄存器得到;
- 接着读出该SWI指令,分解出立即数。
在ARM处理器中,只有MRS指令可以对状态寄存器CPSR和SPSR进行读操作。通过读CPSR可以了解当前处理器的工作状态。读SPSR寄存器可以了解到进入异常前的处理器状态。该指令不影响条件码
MRS{cond} Rd,psr注意:
- 在ARM处理器中,只有MRS指令可以将状态寄存器CPSR或SPSR读出到通用寄存器中
- MRS与MSR配合使用,实现CPSR或SPSR寄存器的读-修改-写操作,可用来进行处理器模式切换、允许/禁止IRQ/FIQ中断等设置。
- 另外,当进程切换或允许异常中断嵌套时,也需要使用MRS指令来读取SPSR状态值,并保存起来。
在ARM处理器中,只有MSR指令可以对状态寄存器CPSR和SPSR进行写操作。与MRS配合使用,可以实现对CPSR或SPSR寄存器的读-修改-写操作,可以切换处理器模式、或者允许/禁止IRQ/FIQ中断等。
指定传送的区域(fields),可以为以下字母(必须小写)的一个或者组合:
- c 控制域屏蔽字节(psr[7..0])
- x 扩展域屏蔽字节(psr[15..8])
- s 状态域屏蔽字节(psr[23..16])
- f 标志域屏蔽字节(psr[31..24])
应用举例
SWI 0 ;软中断,中断立即数为0
SWI 0xl23456 ;软中断,中断立即数为0xl23456
MRS R1,CPSR ;将CPSR状态寄存器读取,保存到R1中
MRS R2,SPSR ;将SPSR状态寄存器读取,保存到R2中
;子程序:使能IRQ中断
ENABLE_IRQ
MRS R0, CPSR
BIC R0, R0,#0x80
MSR CPSR_c,R0
MOV PC,LR
;1.将CPSR寄存器内容读出到R0;
;2.修改对应于CPSR中的I控制位;
;子程序:禁能IRQ中断
DISABLE_IRQ
MRS R0, CPSR
ORR R0, R0,#0x80
MSR CPSR_c,R0
MOV PC,LR
;3.将修改后的值写回 CPSR寄存器的对应控制域;
;4.返回上一层函数;
[!CAUTION]
说明:
只有在特权模式下才能修改状态寄存器。
- 程序中不能通过MSR指令直接修改CPSR中的T控制位来实现ARM状态/Thumb状态的切换,必须使用BX指令完成处理器状态的切换(因为BX指令属分支指令,它会打断流水线状态,实现处理器状态切换)。
- MRS与MSR配合使用,实现CPSR或SPSR寄存器的读—修改—写操作,可用来进行处理器模式切换、允许/禁止IRQ/FIQ中断等设置。
伪指令(仅需掌握 LDR 伪指令)
LDR伪指令用于加载32位的立即数或一个地址值到指定寄存器。在汇编编译源程序时,LDR伪指令被编译器替换成一条合适的指令。若加载的常数未超出MOV或MVN的范围,则使用MOV或MVN指令代替该LDR伪指令,否则汇编器将常量放入文字池,并使用一条程序相对偏移的LDR指令从文字池读出常量。
LDR{cond} register,=[expr | label_expr
[!caution]
label_expr:基于PC的地址表达式或外部表达式
register:加载的目标寄存器
注意: 1.从指令位置到文字池的偏移量必须小于4KB; 2.与ARM指令的LDR相比,伪指令的LDR的参数有“=”号。 文字池(Literal pools)其实就是一个存储常量数据的地方,汇编器会使用文字池来在代码段中存储常量数据
MOV/MVN 可以直接装载一些特定范围的32位值到寄存器中,这些值包括: (1) 8位常量,即0–255 (2) 8位常量右移偶数位 (3) MVN可以处理(1)(2)中值的按位取反值
LDR伪指令用于加载32位的立即数或一个地址值到指定寄存器。在汇编编译源程序时,LDR伪指令被编译器替换成一条合适的指令。若加载的常数未超出MOV或MVN的范围,则使用MOV或MVN指令代替该LDR伪指令,否则汇编器将常量放入文字池,并使用一条程序相对偏移的LDR指令从文字池读出常量。
应用实例
LDR R2, =0xFF0 ;MOV R2, #0xFF0
LDR R0, =0xFF000000 ;MOV R0, #0xFF000000
LDR R1, =0xFFFFFFFE ;MVN R1, #0x1
;使用伪指令将程序标号InitStack的地址存入R1
...
LDR R1,=InitStack
...
InitStack
MOV R0, LR
...
协处理器指令(不考)
3. Thumb 指令(不考)
第四章 汇编程序设计
1. 伪操作的含义,了解几个常用的:GBLA、GBLL 和 GBLS,LCLA、LCLL 和 LCLS,SETA、SETL、SETS,数据定义伪操作:DCB、DCW、DCD,其他常用 伪操作(AREA,END,ALIGN,EXTERN, GET,MACRO,MEND)
与单片机汇编程序设计一样,在ARM汇编语言程序里,有一些特殊指令助记符,这些助记符与指令系统的真正的指令不同,没有相对应的操作码,通常称这些特殊指令助记符为伪指令,他们所完成的操作称为伪操作。
伪操作在源程序中的作用是为完成汇编程序作各种准备工作的,这些伪操作仅在汇编过程中起作用,一旦汇编结束,伪操作的使命就完成。
在ARM的汇编程序中,有如下几种伪指令:符号定义伪指令、数据定义伪指令、汇编控制伪指令、宏指令以及其他伪指令。
符号定义伪指令
符号定义伪指令用于定义ARM汇编语言程序中的变量、对变量赋值以及定义寄存器的别名等操作。常见的符号定义伪指令有如下几种:
- 用于定义全局变量的GBLA、GBLL和GBLS。
- 用于定义局部变量的LCLA、LCLL和LCLS。
- 用于对变量赋值的SETA、SETL、SETS。
- 为通用寄存器列表定义名称的RLIST。
为一个协处理器的寄存器定义名称的伪指令:CN, 0-15为一个协处理器定义名称的伪指令:CP,0-15为一个单精度的向量浮点数运算(VFP)寄存器定义名称的伪指令:SN,寄存器名S0-S31为一个双精度的向量浮点数运算VFP寄存器定义名称的伪指令:DN,D0-D15为一个FPA浮点寄存器定义名称的伪指令:FN,F0-F7
- GBLA GBLL GBLS
GBLA伪指令用于定义一个全局的数字变量,并初始化为0; GBLL伪指令用于定义一个全局的逻辑变量,并初始化为F(假); GBLS伪指令用于定义一个全局的字符串变量,并初始化为空;
- 以上三条伪指令用于定义全局变量,因此在整个程序范围内变量名必须唯一。
语法格式:GBLA ( GBLL 或 GBLS ) 全局变量名
例子:
GBLA Number1;定义一个全局的数字变量,变量名为Number1
Number1 SETA 0xaa ;将Number1变量赋值为0xaa
GBLL True1;定义一个全局的逻辑变量,变量名为True1
- LCLA LCLL LCSL
LCLA伪指令用于定义一个局部的数字变量,并初始化为0; LCLL伪指令用于定义一个局部的逻辑变量,并初始化为F(假); LCLS伪指令用于定义一个局部的字符串变量,并初始化为空;
- 以上三条伪指令用于声明局部变量,在其作用范围内变量名必须唯一。
语法格式: LCLA ( LCLL 或 LCLS ) 局部变量名
【例】
LCLA Number2 ;声明一个局部的数字变量,变量名为Number2
Number2 SETA 0xaa ;将Number2变量赋值为0xaa
LCLL Logic2 ;声明一个局部的逻辑变量,变量名为Logic2
Logic2 SETL {TRUE} ;将Logic2变量赋值为真
LCLS String2 ;定义一个局部的字符串变量,变量名为String2
String2 SETS “Testing” ;将String2变量赋值为“Testing”
- SETA SETL SETS
SETA伪指令用于给一个数学变量赋值; SETL伪指令用于给一个逻辑变量赋值; SETS伪指令用于给一个字符串变量赋值;
-
其中,变量名为已经定义过的全局变量或局部变量,表达式为将要赋给变量的值。
语法格式: 变量名 SETA ( SETL 或 SETS ) 表达式
【例】
LCLA Number3 ;声明一个局部的数字变量,变量名为Number3
Number3 SETA 0xaa ;将Number3变量赋值为0xaa
LCLL Logic3;声明一个局部的逻辑变量,变量名为Logic3
Logic3 SETL {TRUE};将Logic3变量赋值为真
- RLIST
RLIST伪指令可用于对一个通用寄存器列表定义名称,使用该伪指令定义的名称可在ARM指令LDM/STM中使用。
在LDM/STM指令中,列表中的寄存器访问次序为根据寄存器的编号由低到高,而与列表中的寄存器排列次序无关。
语法格式: 名称 RLIST { 寄存器列表 }
【例】
RegList RLIST {R0-R5,R8,R10} ;将寄存器列表名称定义为RegList,可在ARM指令LDM/STM中通过该名称访问寄存器列表。
……
STMFD SP!,RegList ;保存寄存器列表RegList到堆栈
数据定义伪指令
数据定义伪操作一般用于为特定的数据分配存储单元,同时可完成已分配存储单元的初始化。常见的数据定义伪操作有如下几种:
- DCB 用于分配一片连续的字节存储单元并用指定的数据初始化。
- DCW(DCWU)用于分配一片连续的半字存储单元并用指定的数据初始化。
- DCD(DCDU) 用于分配一片连续的字存储单元并用指定的数据初始化。
- DCFD(DCFDU)用于为双精度的浮点数分配一片连续的字存储单元并用指定的数据初始化。
- DCFS(DCFSU) 用于为单精度的浮点数分配一片连续的字存储单元并用指定的数据初始化。
- DCQ(DCQU) 用于分配一片以8字节为单位的连续的存储单元并用指定的数据初始化。
- DCDO 用于分配一段字的内存单元,将每个单元的内容初始化为该单元相对于基址寄存器的偏移量
- DCI 用于分配一段字的内存单元,并用单精度的浮点数据初始化,指定内存单元存放的是代码,而不是数据
- SPACE 用于分配一片连续的字节存储单元,并初始化为0
- MAP 用于定义一个结构化的内存表首地址
- FIELD 用于定义一个结构化的内存表的数据域
- LTORG 用于声明一个文字池(缓冲池)
- DCB
DCB伪操作用于分配一片连续的字节存储单元并用伪指令中指定的表达式初始化。其中,表达式可以为0~255的数字或字符串。DCB也可用“=“代替。
语法格式
{label} DCB expr{,expr}…
label可选的程序标号
【例】
String DCB “This is a test!” ;分配一片连续的字节存储单元并初始化。
Parameter DCB 0x33,0x44,0x55
;分配一片连续的字节存储单元并初始化。
2.DCW
DCW(或DCWU)伪操作用于分配一片连续的半字存储单元并用指定的表达式初始化。 其中,表达式可以是程序标号或数字表达式。 用DCW分配的存储单元是半字对齐的,而用DCWU分配的存储单元并不严格半字对齐。
语法格式:{label} DCW/DCWU expr{,expr}…
label可选的程序标号
【例】
Data DCW 0,1,2,3 ;分配一片连续的半字存储
单元并初始化。
- DCD 或DCDU
DCD(或DCDU)伪操作用于分配一片连续的字存储单元并用指定的表达式初始化。 其中,表达式可以为程序标号或数字表达式。DCD也可用“&”代替。 用DCD分配的字存储单元是字对齐的,而用DCDU分配的字存储单元并不严格字对齐。
语法格式:{label} DCD/DCDU expr{,expr}…
【例】
Data DCD 3,4,5,6 ;分配一片连续的字存储单元并初始化。
- DCFD或DCFDU
DCFD(或DCFDU)伪操作用于为双精度的浮点数分配一片连续的字存储单元并用指定的表达式初始化。每个双精度的浮点数占据两个字单元。 用DCFD分配的字存储单元是字对齐的,而用DCFDU分配的字存储单元并不严格字对齐。
语法格式:标号 DCFD(或DCFDU) 表达式
【例】
FData DCFD 2E115,-5E7 ;分配一片连续的字存储单元并初始化为指定的双精度数。
- DCFS 或 DCFSU
DCFS(或DCFSU)伪操作用于为单精度的浮点数分配一片连续的字存储单元并用伪操作中指定的表达式初始化。每个单精度的浮点数占据一个字单元。 用DCFS分配的字存储单元是字对齐的,而用DCFSU分配的字存储单元并不严格字对齐。
语法格式:标号 DCFS(或DCFSU) 表达式
【例】
Sdata DCFS 1,2E5,-5E-7 ;分配一片连续的字存储单元并初始化为指定的单精度数。
- DCQ(或DCQU)
DCQ(或DCQU)伪操作用于分配一片以8个字节为单位的连续存储区域并用伪操作中指定的表达式初始化。 分配的字数等于expr个数的2倍。 用DCQ分配的存储单元是字对齐的,而用DCQU分配的存储单元并不严格字对齐。
语法格式:标号 DCQ(或DCQU) 表达式
【例】
Data DCQ 100,1000 ;分配一片连续的存储单元并初始化为指定的值。
- DCDO
DCDO用于分配一段字内存单元,并将每个字单元的内容初始化为expr基于静态基址寄存器R9内容的偏移量。
DCDO伪操作为静态基址寄存器R9的偏移量分配内存单元,该指令需要内存字对齐。
语法格式:{label} DCDO expr{,expr}….
【例】
IMPORT externsys
Data DCDO externsys;分配32位的字单元,其值为标号externsys相对于R9的偏移量
汇编控制(Assembly Control)伪操作
汇编控制伪操作用于控制汇编程序的执行流程,常用的汇编控制伪操作包括以下几条:
- IF、ELSE、ENDIF 条件汇编代码文件内的一段源代码
- WHILE、WEND 根据条件重复汇编
- MACRO、MEND 标识宏定义的开始和结束
- MEXIT 中途跳转出宏
- IF ELSE ENDIF
IF、ELSE、ENDIF伪操作能根据条件的成立与否决定是否执行某个指令序列。当IF后面的逻辑表达式为真,则执行指令序列1,否则执行指令序列2。其中,ELSE及指令序列2可以没有,此时,当IF后面的逻辑表达式为真,则执行指令序列1,否则继续执行后面的指令。
IF、ELSE、ENDIF伪操作可以嵌套使用。
语法格式:
IF 逻辑表达式
指令序列 1
{ ELSE
指令序列 2
}
ENDIF
【例】
GBLS Version ;定义一个全局的字符串变量,
;变量名为Version
……
IF Version =“V1”
指令序列1
ELSE
指令序列2
ENDIF
- WHILE WEND
WHILE、WEND伪操作能根据条件的成立与否决定是否循环执行某个指令序列。当WHILE后面的逻辑表达式为真,则执行指令序列,该指令序列执行完毕后,再判断逻辑表达式的值,若为真则继续执行,一直到逻辑表达式的值为假。WHILE、WEND伪操作可以嵌套使用。
语法格式:
WHILE 逻辑表达式
指令序列
WEND
【例】
GBLA Counter ;声明一个全局的数字变量,变量名为
Counter,作为循环计数器
……
WHILE Counter < 10
指令序列
WEND
- MACRO MEND
MACRO、MEND伪操作可以将一段代码定义为一个整体,称为宏指令,然后就可以在程序中通过宏指令多次调用该段代码。
MACRO ;标志宏定义的开始
{$label} macroname {$parameter, {$parameter}…}
指令序列
MEND
【例】
MACRO
CODE_1 ; 宏名为CODE_1,无参数
LDR R0,=rPDATG ; 读取PG0口的值
LDR R1,[R0]
ORR R1,R1,#0X01 ; CSI置位
STR R1,[R0]
MEND
宏定义中,宏指令可以使用一个或多个参数,当宏指令被展开时,这些参数被相应的值替换。
MACRO ;宏定义
CALLSubfunction $Function,$dat1,$dat2
;宏名为CALLSubfunction,带3个参数
IMPORT $Function ;声明外部子程序名
MOV R0,$dat1 ;设置子程序参数R0=$dat1
MOV R1,$dat2
BL Function ;调用子程序
MEND ;宏定义结束
- MEXIT
MEXIT用于从宏定义中跳转出去。
语法格式:
MEXIT
如果要提前从宏体中退出,例如从一个宏内的循环体中退出,可采用MEXIT伪操作提前跳出宏体。
其他常用的伪操作
其他的一些使用较频繁的伪操作:
- AREA
- ALIGN
- CODE16 CODE32
- ENTRY
- END
- EQU
- EXPORT(或GLOBAL)
- IMPORT
- EXTERN
- GET(或INCLUDE)
- INCBIN
- AREA
AREA伪操作用于定义一个代码段或数据段。ARM汇编程序设计采用分段式设计,一个ARM汇编源程序至少需要一个代码段,大的程序可以包含多个代码段和数据段。当程序太长时,也可以将程序分为多个代码段和数据段。
使用AREA伪指令将程序分为多个ELF(Executable and Linkable Format)格式的段。
【例】
AREA Init,CODE,READONLY 。。。。。。。。。。。。 指令序列 ;该伪指令定义了一个代码段,段名为Init,属性为只读 - ALIGN ALIGN伪操作可通过添加填充字节的方式,使当前位置满足一定的对齐方式。其中,表达式的值用于指定对齐方式,可能的取值为2的幂,如1、2、4、8、16等。默认4个字节对齐。
若未指定表达式,则将当前位置对齐到下一个字的位置。偏移量也为一个数字表达式,若使用该字段,则当前位置的对齐方式为:2的表达式次幂+偏移量。
【例】
AREA Init,CODE,READONLY,ALIGN=3 ;指定后面的指令为8字节对齐。
指令序列
END
- CODE16 CODE32
- CODE16伪操作通知汇编器,其后的指令序列为16位的Thumb指令。
- CODE32伪操作通知汇编器,其后的指令序列为32位的ARM指令。
- CODE16和CODE32伪操作只告诉编译器后面的指令是16位或32位的类型,指令本身不能进行程序状态的切换, 如果要进行状态的切换,可以使用BX指令进行操作。 【例】
AREA Init,CODE,READONLY ;Init代码段名
……
CODE32 ;通知编译器其后的指令为32位的ARM指令
LDR R0,=NEXT+1 ;将跳转地址放入寄存器R0
BX R0 ;程序跳转到新的位置执行,并将处理器切换到Thumb工作状态
……
CODE16 ;通知编译器其后的指令为16位的Thumb指令
NEXT
LDR R3,=0x3FF
……
END ;程序结束
- ENTRY
- ENTRY伪操作用于指定程序的入口点。
- 在一个完整的汇编语言程序中至少要有一个ENTRY
- (也可以有多个,当有多个ENTRY时,程序的真正入口点由链接器指定),
- 但在一个源文件里最多只能有一个ENTRY(可以没有)。 【例】 ```
AREA Init,CODE,READONLY
ENTRY ;指定应用程序的入口点
……
5. **END**
- END伪操作用于通知汇编器已经到了源程序的**结尾**。
- 每一个汇编源文件都需要使用一个END伪操作,指示本源程序结束。
【例】
``` assembly
AREA Init,CODE,READONLY
……
END ;指定应用程序的结尾
- EQU
- EQU伪操作用于为程序中的常量、标号等定义一个等效的字符名称,类似于C语言中的#define。其中EQU可用“*”代替。
- 名称为EQU伪操作定义的字符名称,当表达式为32位的常量时,可以指定表达式的数据类型,可以有以下三种类型:CODE16、CODE32和DATA。
语法格式:
名称 EQU 表达式 { ,类型 }
【例】
ABCE EQU label+8 ;定义地址标号ABCD为label+8
Test EQU 50 ;定义标号Test的值为50
Addr EQU 0x55,CODE32 ;定义Addr的值为0x55,且该处为32位的ARM指令。
- EXPORT或GLOBAL
- EXPORT伪操作用于在程序中声明一个全局的标号,该标号可在其他的文件中引用。
- EXPORT可用GLOBAL代替。
- 标号在程序中区分大小写。
【例】
AREA Init,CODE,READONLY
EXPORT main ;声明一个可全局引用的标号main
……
END
- IMPORT
- IMPORT伪操作用于通知编译器要使用的标号在其他的源文件中定义,但要在当前源文件中引用
- 而且无论当前源文件是否引用该标号,该标号均会被加入到当前源文件的符号表中。
【例】
AREA Init,CODE,READONLY
IMPORT main ;通知编译器当前文件要引用标号main,但main在其他源文件中定义
……
END
- EXTERN
- EXTERN伪操作用于通知编译器要使用的标号在其他的源文件中定义,但要在当前源文件中引用,
- 如果当前源文件实际并未引用该标号,该标号就不会被加入到当前源文件的符号表中。
- 注意: 该伪操作与IMPORT的区别是,IMPORT伪操作无论当前源文件是否引用该标号,该标号均会被加入到当前源文件的符号表中。
【例】
AREA Init,CODE,READONLY
EXTERN main ;通知编译器当前文件要引用标号main,main在其他源文件中定义,如果本文件中没有使用main,则main就不会被加入到当前源文件的符号表中。
……
END
- GET INCLUDE
- GET伪操作用于将一个源文件包含到当前的源文件中,并将被包含的源文件在当前位置进行汇编处理。
- 可以使用INCLUDE代替GET。使用方法与C语言中的“include”相似。
- GET伪指令只能用于包含源文件, 如果需要包含经过编译后的二进制目标文件,需要使用INCBIN伪指令。
语法格式: GET 文件名
【例】
AREA Init,CODE,READONLY
GET a1.s ;通知编译器当前源文件包含源文件a1.s
GET C:\a2.s;通知编译器当前源文件包含源文件C:\ a2.s
……
END
- INCBIN
- INCBIN伪操作用于将一个二进制目标代码文件或任意格式的数据文件包含到当前的源文件中,
- 被包含的文件不作任何变动地存放在当前文件中,编译器从其后开始继续处理。
【例】
AREA Init,CODE,READONLY
INCBIN a1.dat ;通知编译器当前源文件包含文件a1.dat
INCBIN C:\a2.txt ;通知编译器当前源文件包含文件C:\a2.txt
INCBIN a3.bin ;通知编译器当前源文件包含文件a3.bin
……
END
- RN
RN 伪指令用于给一个寄存器定义一个别名。采用这种方式可以方便程序员记忆该寄存器的功能。其中,名称为给寄存器定义的别名,表达式为寄存器的编码。 语法格式: 名称 RN 表达式 使用示例:
Temp RN R0 ;将R0 定义一个别名Temp
2. 汇编程序设计:常用程序段(子程序调研、数据比较跳转、分支选择、循 环)、ppt 中的例子能看懂、能自己写。
汇编语法: 在一个项目设计中:
- 至少需要有一个汇编源文件或C程序文件,
- 可以有多个汇编文件或多个C程序文件,
- 或者C语言和汇编语言混合编程的文件。
- 汇编程序源文件的扩展名必须是“.s”。
| 源程序 | 文件名 |
| 汇编源程序 | .s |
| C文件 | .c |
| 头文件 | .h |
1 汇编语句格式
ARM(Thumb)汇编语言的语句格式为: {标号} {指令或伪指令} {;注释}
正确的例子:
……
String1 SETS “My string1”
Count RN R0 ;给R0寄存器定义别名
START
LDR R0,=0x12345
MOV R1,#0
LOOP
MOV R2,#3
……
错误的例子:
START MOV R0,#1 ;标号START没有顶头写
ABC: MOV R1,#2 ;标号后不能带:
MOV R2,#3 ;指令不允许顶头写
Loop Mov R2,#3 ;指令中大小写混合
B loop ;无法跳转到Loop去,标号大小写敏感
在ARM 汇编中,符号可以代表地址、变量、数字常量。当符号代表地址时又称为标号,符号就是变量的变量名、数字常量的名称、标号,符号的命名规则如下:
- 符号由大、小写字母、数字以及下划线组成。
- 符号区分大小写,同名的大、小写符号会被编译器认为是两个不同的符号。
- 符号在其作用范围内必须唯一。
- 自定义的符号名不能与系统的保留字相同。
- 符号名不能与指令或伪指令同名。
汇编语言程序设计
在ARM(Thumb)汇编语言程序中,以程序段为单位组织代码。段是相对独立的指令或数据序列,具有特定的名称。段可以分为代码段和数据段,代码段的内容为执行代码,数据段存放代码运行时需要用到的数据。一个汇编程序至少应该有一个代码段,当程序较长时,可以分割为多个代码段和数据段,多个段在程序编译链接时最终形成一个可执行的映象文件。
可执行映象文件通常由以下几部分构成
- 一个或多个代码段,代码段的属性为只读。
- 零个或多个包含初始化数据的数据段,数据段的属性为可读写。
- 个或多个不包含初始化数据的数据段,数据段的属性为可读写。
链接器根据系统默认或用户设定的规则,将各个段安排在存储器中的相应位置。因此源程序中段之间的相对位置与可执行的映象文件中段的相对位置一般不会相同。 以下是一个汇编语言源程序的基本结构:
AREA Init,CODE,READONLY
ENTRY ;程序入口点
Start ;标号,指向LDR伪指令
LDR R0,=0x3FF5000
MOV R1,#0xFF
STR R1,[R0]
LDR R0,=0x3FF5008
MOV R1,#0x01
STR R1,[R0]
……
END
在汇编语言程序中,用AREA伪指令定义一个段,并说明所定义段的相关属性,本例定义一个名为Init的代码段,属性为只读。ENTRY伪指令标识程序的入口点,接下来为指令序列,程序的末尾为END伪指令,该伪指令告诉编译器源文件的结束, 每一个汇编语言程序段都必须有一条END伪指令,指示代码段的结束。
子程序调用
在ARM汇编语言程序中,子程序的调用一般是通过BL指令来实现的。在程序中,使用指令“BL 子程序名”即可完成子程序的调用。
AREA Init,CODE,READONLY
ENTRY
Start
LDR R0,=0x3FF5000
MOV R1,#0xFF
STR R1,[R0]
LDR R0,=0x3FF5004
MOV R1,#0x01
STR R1,[R0]
BL PRINT_TEXT
……
PRINT_TEXT
……
MOV PC,LR
……
END
宏定义及其作用
- 使用宏定义可以提高程序的可读性,简化程序代码和同步修改。
- ARM宏定义与标准C语言的#define相似,只在源程序中进行字符的简单替代。
- 宏定义从MACRO伪指令开始,到MEND结束,并可以使用参数。
MACRO ;宏定义 CALLSubfunction $Function,$dat1,$dat2 ;宏名为 ;CALLSubfunction,带3个参数 IMPORT $Function ;声明外部子程序名 MOV R0,$dat1 ;设置子程序参数R0=$dat1 MOV R1,$dat2 BL Function ;调用子程序 MEND ;宏定义结束 …… CALLSubfunction FADD1,#3,#2 ;宏调用,参数没有$ …… 汇编处理后,宏调用将被展开,程序如下: …… IMPORT FADD1 MOV R0,#3 MOV R1,#2 BL FADD1 ……
数据比较跳转
汇编程序可以使用CMP指令进行两个数的比较,然后根据比较结果实现程序的跳转,代码如下:
CMP R5,#10 ;做减法
BEQ BRANCH1 ;如果R5为10,则跳转到BRANCH1
……
CMP R1,R2
ADDHI R1,R1,#1 ;如果R1>R2,则R1=R1+1
ADDLS R1,R1,#2 ;如果R1<=R2,则R1=R1+2
……
ANDS R1,R1,#0x80 ;R1=R1&0x80,并设置相应的标志位
BNE WAIT ;如果R1的第7位0,则跳转到WAIT
循环
下面的程序代码为汇编循环程序的例子,指定了循环的次数,每循环一次进行减1操作,并判断结果是否为0,如果为0则退出循环。
MOV R0,#10
LOOP
……
SUBS R0,R0,#1 ;R0自减1
BNE LOOP ;10次执行完 R0=0 NE条件不满足
;BNE不执行,执行下一条语句,退出循环
……
堆栈操作
可以使用存储器访问指令LDM/STM实现堆栈操作,用于子程序的寄存器保护。在使用堆栈前,首先需要分配好堆栈空间,设置好寄存器R13(即堆栈指针SP),否则操作失败。
OUTDAT
STMFD SP!,{R0-R7,LR} ;寄存器入栈, 从右向左
…… ;先压LR,R7…R0
BL DELAY
……
LDMFD SP!,{R0-R7,PC} ;寄存器出栈
;出栈从从左到右
;先弹R0,最后弹出PC,PC=LR,完成子程序的返回
查表操作
查表操作是汇编程序经常使用的一种功能,代码如下:
……
LDR R3,=DISP_TAB ;字模表的首地址
LDR R2,[R3,R5,LSL #2] ;根据R5的值查表, 取出相应的值。
……
下面的表为0-F的字模
DISP_TAB DCD 0xC0,0xF9,0xA4,0x99,0x92
DCD 0x82,0xF8,0x80,0x90,0x88,0x83
DCD 0xC6,0xA1,0x86,0x8E,0xFF
长跳转
- ARM的B指令和BL指令无法进行整个内存空间范围内的跳转(仅±32MB),
- 但可以通过对PC寄存器的赋值实现32位地址的跳转和调用。
【例】
LDR PC,=JUMP_FUNC ;跳转到JUMP_FUNC处
……
JUMP_FUNC ……. ;跳转到这里
……
特殊寄存器定义及应用
对ARM芯片的外设寄存器进行访问时,可以使用下面的代码对其寄存器进行定义并应用:
WDTCNT EQU 0x01D30008 ;看门狗计数器寄存器定义
……
LDR R0,=WDTCNT ;寄存器地址传给R0
MOV R1,#12
STR R1,[R0] ;用十进制12设置看门狗计数器寄存器
片外部件控制
在ARM芯片的外围部件的控制器中,一般会设置“置位/复位”寄存器,这样方便地实现对控制位的操作,而不影响其他位,而其他I/O位的状态保持不变。另外,ARM存储/保存指令具有偏移功能,所以对外围部件的控制寄存器进行操作时可以使用此功能,避免了每次都加载寄存器地址的操作,代码如下:
LDR R0,=GPIO_BASE
MOV R1,#0x00
STR R1,[R0,#0x04] ;基地址+0x04=IOSET,将IOSET设置为0
MOV R1,#0x10
STR R1,[R0,#0x0C] ;基地址+0x0C=IOCLR,将IOCLR设置为0x10
嵌入式C语言
1.文件包含伪指令
文件包含伪指令可将头文件包含到程序中,头文件中定义的内容有符号常量,复合变量原型、用户定义的变量原型和函数的原型说明等。编译器编译预处理时,用文件包含的正文内容替换到实际程序中。
(1)文件包含伪指令的格式
include <头文件名.h> /*标准头文件*/
include "头文件名.h " /*自定义头文件*/
(2)包含文件伪指令的说明
[!TIP]
- 常在头文件名后用.h作为扩展名,可带或不带路径。
- 头文件可分为标准头文件和自定义头文件。
- 尖括号内的头文件为标准头文件,由开发环境或系统提供。
- 双引号内的头文件为用户自定义头文件。
- 搜索时,首先在当前目录中搜索,其次按环境变量include指定的目录顺序搜索。
- 搜索到头文件后,就将该伪指令直接用头文件内容替换。
2.宏定义伪指令
宏定义伪指令分为:简单宏、参数宏、条件宏、预定义宏及宏释放。
(1)简单宏
格式如下:
#define 宏标识符 宏体
- 宏体超长时,允许使用续行符“\”进行续行,续行符和其后的换行符 \n 都不会进入宏体。
- 在定义宏时,应尽量避免使用C语言的关键字和预处理器的预定义宏,以免引起灾难性的后果。
- 在源文件中,用预处理器伪指令定义过宏标识符之后,就可用宏标识编写程序。当源文件被预处理器处理时,每遇到该宏标识符,预处理器便将宏展为宏体。
(2)参数宏 格式如下:
# define 宏标识符(形式参数表) 宏体
形式参数表为逗号分割的形式参数。
- 宏体是由单词序列组成。宏体超长时,允许使用续行符“\”进行续行,续行符和其后的换行符 \n 都不会进入宏体。
- 使用参数宏时,形式参数表应换为同样个数的实参数表,这一点类似于函数的调用。参数宏与函数的区别在于参数宏的形参数表中没有类型说明符。
- 预处理器在处理参数宏时使用2遍宏展开。第1遍展开宏体,第2遍对展开后的宏体用实参数替换形式参数。
例5.4 在Linux下ARM S3C2410X芯片的A/D转换的驱动程序的头文件s3c2410-adc.h中定义了下面三个宏。
#define ADC_WRITE(ch, prescale) ((ch)<<16|(prescale))
/*ADC通道号与预标值合成一个字*/
#define ADC_WRITE_GETCH(data) (((data)>>16)&0x7)
/*获得低三位,ADC通道号*/
#define ADC_WRITE_GETPRE(data) ((data)&0xff)
/*获得低八位,ADC的预定标值*/
(3)条件宏定义 格式如下: 格式1:
# ifdef 宏标识符 //若标识符已定义
# undef 宏标识符
# define 宏标识符 宏体
# else //若标识符未定义
# define 宏标识符 宏体
# endif
格式2:
# ifndef 宏标识符 //若标识符未定义
# define 宏标识符 宏体
# else //若标识符已定义
# undef 宏标识符
# define 宏标识符 宏体
# endif
其中:
[!TIP]
- 格式1是测试存在,格式2是测试不存在。
- else可有,也可没有。
(4)宏释放 用于释放原先定义的宏标识符。经释放后的宏标识符可再次用于定义其他宏体。 格式如下:
# undef 宏标识符
例5.6
#define SIZE 512
…
buf=SIZE*blks /*宏扩展为buf=512*blks; */
…
#undef SIZE
#define SIZE 128
…
buf=SIZE*blks /*宏扩展为buf=128*blks; */
条件编译伪指令
格式如下:
# if(条件表达式1)
…
# elif (条件表达式2)
…
# elif (条件表达式3)
…
# elif (条件表达式n)
…
# else
…
# endif
例子:
# if _B0SIZE==B0SIZE_BYTE
typedef unsigned char PB0SIZE;
# elif _B0SIZE==B0SIZE_SHORT
typedef unsigned short PB0SIZE;
# elif _B0SIZE==B0SIZE_WORD
typedef unsigned long PB0SIZE;
# endif
3. ATPCS 规则:寄存器、数据栈、参数传递规则
ATPCS(ARM-Thumb Procedure Call Standard)规则
-
寄存器的使用规则
-
数据栈的使用规则
-
参数的传递规则
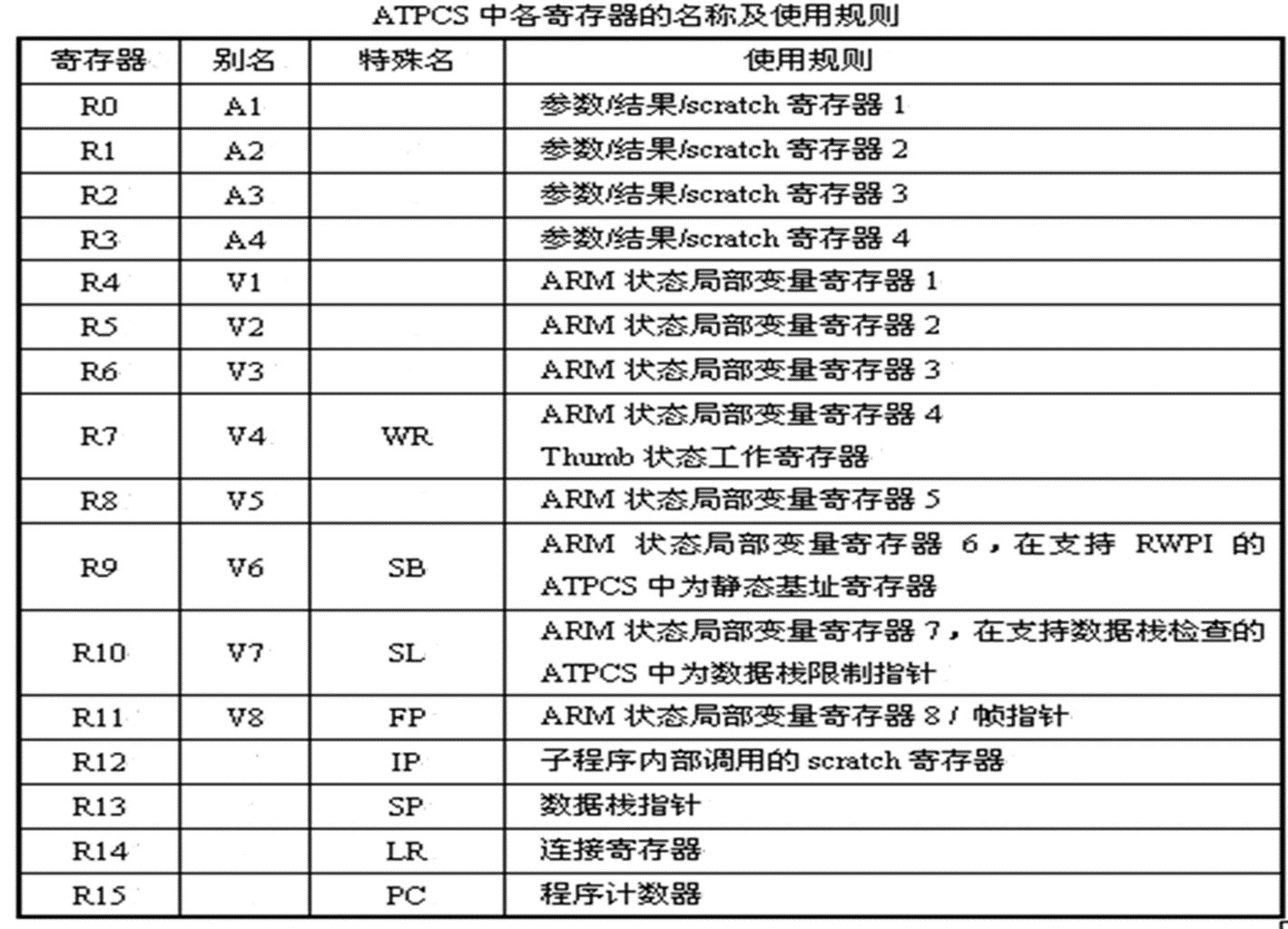
1.寄存器的使用规则
- 子程序间通过寄存器R0~R3来传递参数,记为A1~A4(别名)。
- 被调用的子程序在返回前无须恢复寄存器R0~R3的内容。
- 子程序中使用寄存器R4~R11来保存局部变量。记为V1~V8(别名)。
- 如果在子程序中使用到了寄存器V1~V8中的某些寄存器,则子程序进入时必须保存这些寄存器的值,在返回前必须恢复这些寄存器的值
- 对于子程序中没有用到的寄存器,则不必进行这些操作。在Thumb程序中,通常只能使用寄存器R4~R7来保存局部变量。
- 寄存器R13用做数据栈指针,记作SP。
- 在子程序中寄存器R13不能用做其他用途。
- 寄存器SP在进入子程序时的值和退出子程序时的值必须相等。
- 寄存器R14称为链接寄存器,记作LR。
- 它用于保存子程序的返回地址。
- 如果在子程序中保存了返回地址,则寄存器R14可作其他用途。
- R15是程序计数器,记作PC。不能作其他用途。
2.数据栈的使用规则
有下面4种数据栈:
- FD(Full Descending) 满递减
- ED(Empty Descending) 空递减
- FA(Full Ascending) 满递增
- EA(Empty Ascending) 空递增
ATPCS规定数据栈为FD(满递减) 类型, 并且对数据栈的操作是8字节对齐的。 异常中断处理程序可使用中断程序的数据栈。
- 数据栈指针(Stack Point):最后一个写入栈的数据的内存地址。
- 数据栈的基地址(Stack Base):数据栈的最高地址。ATPSC中的数据栈是FD型,最早入栈的数据所占的内存单元是基地址的下一个内存单元。
- 数据栈界限(Stack Limit):数据栈中可使用的最低的内存单元地址。
- 数据栈中的数据帧(Stack Frames):数据栈中为子程序分配用来保存寄存器和局部变量的区域。
3. 参数的传递规则
(1)参数个数固定的子程序参数传递规则
若系统含浮点运算硬件部件,浮点参数传递规则:
- 各个浮点参数按顺序处理。
- 为每个浮点参数分配FP寄存器。方法:满足该浮点参数需要的且编号最小的一组连续的FP寄存器。 第一个整数参数,通过寄存器R0~R3来传递。其他参数通过数据栈传递。
(2)参数个数可变的子程序参数传递规则
- 当参数不超过4个,用R0~R3传递参数,
当参数超过4个时,还可以使用数据栈来传递参数。
- 在参数传递时,所有参数看作是存放在连续的内存字单元中的字数据。然后,依次将各字数据传递到寄存器 R0~R3中。
如果参数多于4个,将剩余的字数据传送到数据栈中,入栈的顺序与参数顺序相反,即最后一个字数据先入栈。
(3)子程序结果返回规则
- 结果为一个32位整数,可通过寄存器R0返回;
- 结果为一个64位整数,可通过寄存器R0,R1返回,依次类推;
- 结果为一个浮点数时,可通过运算部件的寄存器F0、D0来返回;
- 结果为复合型的浮点数(如复数)时,可通过寄存器F0~Fn或者D0~Dn来返回。
- 对于位数更多的结果,需通过内存来传递,如通过数据栈来传递。
4. C 和汇编相互调用的程序能够看懂,及简单的程序编写。
C程序中嵌入汇编程序
2.内嵌汇编指令的特点 (1)操作数
- 作为操作数的寄存器和常量可以是C/C++表达式。是char、short、int类型,而且这些表达式都是作为无符号数进行操作。
- 编译器将会计算这些表达式的值,并为其分配寄存器。
- 不是真正意义的汇编
(2)物理寄存器
- 内嵌汇编指令中使用物理寄存器的限制:
- 不能直接向PC寄存器中赋值,程序的跳转只能通过B指令和BL指令实现。
- 在内嵌汇编指令中,不要使用过于复杂的C/C++表达式。
- 编译器可能会使用R12寄存器或R13寄存器存放编译的中间结果,在计算表达式值时可能会将寄存器R0到R3、R12以及R14用于子程序调用。
- 一般不要指定物理寄存器(会影响编译器分配寄存器)。
(3)常量
常量前的符号#可省略。若表达式前使用了符号#,则必须是一个常量。
(4)指令展开
如果包含常量操作数,该指令可能会被汇编器展开成几条指令。例如指令:
ADD R0,R0,#1023
可能会被展开成下面的指令序列:
ADD R0,R0,#1024
SUB R0,R0,#01
MUL指令会被展开成一系列加法和移位操作。
(5)标号
C/C++程序中的标号可被内嵌的汇编指令使用。但只有B指令可使用C/C++程序中的标号,指令BL不能使用C/C++程序中的标号。
指令B使用C/C++程序中的标号格式:
B{cond} label
(6)内存单元的分配
内嵌汇编器不支持汇编语言用于内存分配的伪操作,所用的内存单元的分配都是通过C/C++程序完成的,分配的内存单元通过变量供内嵌的汇编器使用。
(7)SWI和BL指令的使用
内嵌SWI和BL指令中3个可选寄存器列表:
- 第1个寄存器列表用于存放输入的参数。
- 第2个寄存器列表用于存放返回的参数。
- 第3个寄存器列表的内容供被调用的子程序作为工作寄存器。
3.内嵌的汇编器与armasm的区别
在功能和使用方法上主要有以下特点:
- 不能写PC (MOV PC, LR)
- 不支持伪指令LDR Rn,=expression,但可用指令: MOV Rn,expression来代替。
- 除NOP外,不支持ADR、ADRL等伪指令。
- 指令中的C变量不要与任何物理寄存器重名
- LDM/STM指令中的寄存器列表只能使用物理寄存器,不能使用C表达式
- 不支持指令BX/BLX
- 用户不用维护数据栈
- 不要轻易改变处理器模式。
- 不支持内存分配操作
C 语言调用汇编程序
汇编调用 C 语言
第五章 嵌入式 Linux 驱动开发
1) 设备驱动的概念、抽象层次、分类、特点、安装方法 2) 设备驱动开发过程 3) 字符设备驱动结构,file_operations 里常用的接口函数、驱动的结构 4) 所有的函数不需要背
1) 设备驱动的概念、抽象层次、分类、特点、安装方法
设备驱动程序介于操作系统和硬件之间,屏蔽了硬件设备的物理细节,并提供了访问各种硬件设备的统一接口。Linux内核源程序中占有60%以上。
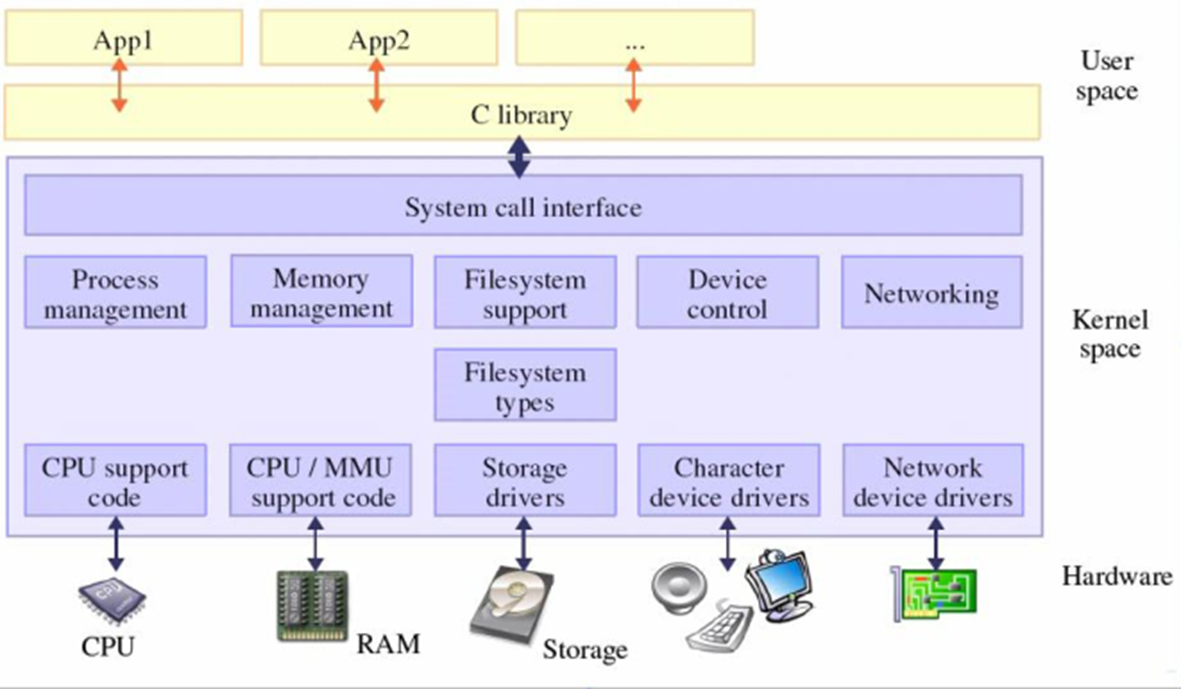
应用程序 库 内核 驱动程序之间的关系
什么是驱动程序:
- 作为操作系统的一部分(OS = Kernel + Device Driver) - 向上为Linux系统提供访问硬件统一调用接口 - 向下用于控制硬件:与Arm裸机程序一样,通过读写硬件寄存器达到控制硬件的目的
- 驱动程序的运行是被动的
- 驱动只是告诉内核”我在这里,我能做这些工作”:向内核注册
- 这些工作何时开始,取决于应用程序:应用触发驱动
设备驱动分类
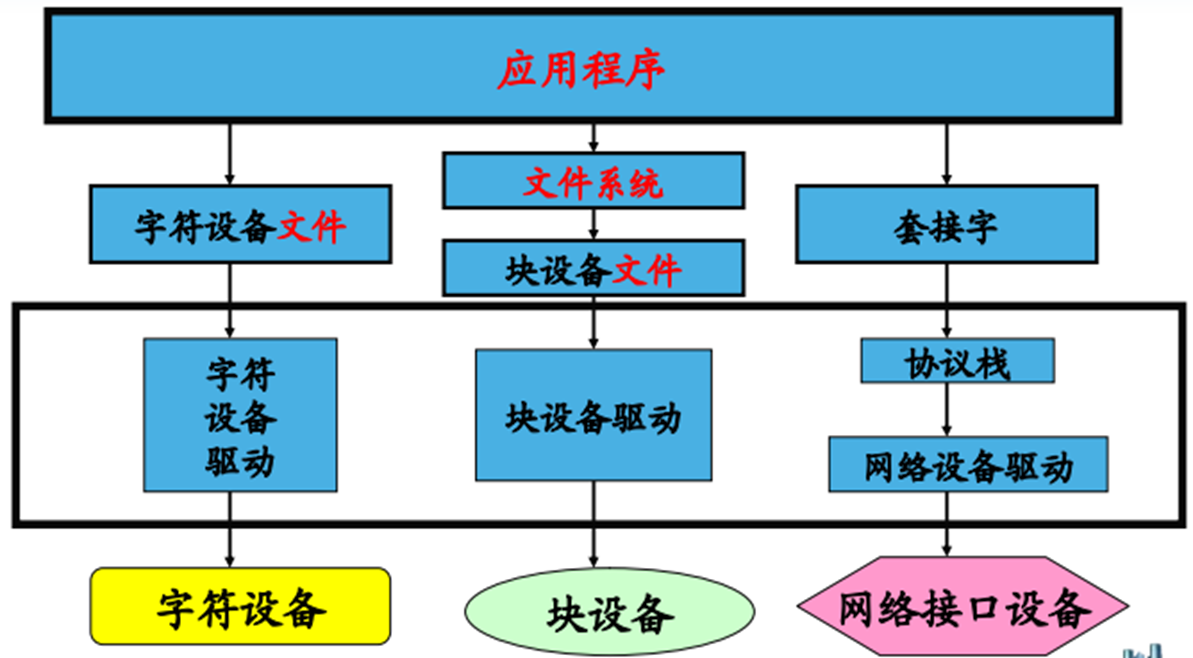
- 字符设备驱动 设备以字节流方式访问(以字节为单位读写) 字符设备驱动实现了open、close 、read、write等系统调用 应用程序通过设备文件(如/dev/ttySAC0)访问设备 字符设备文件的第一个标志是前面的“c”标志。
$ ls –l /dev
crw-rw---- 1 root uucp 4, 64 08-30 22:58 ttyS0 /*串口设备, c表示字符设备*/
crw-rw---- 1 root uucp 3, 4 08-30 22:58 ttyS0 /* 主设备号3,此设备号4 */
- 块设备驱动
设备上的数据以块的方式存放(如NAND Flash上的数据以页为单位) 块设备驱动程序也向用户层提供open、close 应用通过设备文件(如/dev/sda1)来访问设备 块设备驱动特别之处: (1)操作硬件的实现方式不一样:先将数据组织成块,再操作设备 (2)数据块上的数据按照一定的格式组织:存放文件系统,实现mount
例如,在系统中的块设备IDE硬盘的主设备号是3,而多个IDE硬盘及其各个分区分别赋予次设备号1、2、3……
$ ls –l /dev
brw-r----- 1 root floppy 2, 0 08-30 22:58 fd0/*软盘设备,b表示块设备*/
- 网络设备驱动 设备上的数据以不固定大小的帧输入与输出 没有/dev上对应的设备文件,不通过open、read、write操作 系统为网络设备访问分配唯一接口(如eth0) 为应用层提供一套数据包传输函数访问接口(SOCKET)
2) 设备驱动开发过程
- 查看原理图、数据手册,了解设备的操作方法
- 在内核中找到相近的驱动程序,以它为模板开发
- 实现驱动程序的初始化,并向内核注册
- 按照内核规定的驱动框架,实现相关操作函数(如open、read、write)
- 编译驱动程序到内核中,或者编译成模块并挂载(insmod)到内核
直接编译进内核
- 将驱动模块源码合入内核源码
- 设备驱动程序应包含在drivers子目录
- 首先确认是否存在于设备驱动程序特性相似的目录名
- 存在则插入相应目录,否则字符类型插入char目录,块类型插入block目录,网络类型插入net目录
- 修改内核编译选项文件
- Linux内核支持使用内核编译选项包含到内核中的功能
- make menuconfig读入这些内核编译选项文件来配置内核
- 2.6内核编译选项文件为KConfig
- 进入加入了驱动模块的目录,修改目录下的KConfig,使得加入的驱动能在配置项中显示
- 修改内核源码中的Makefile
- Makefile指定了驱动程序的编译规则,使得驱动程序能包含到内核image中
- Makefile根据make menuconfig配置设定的编译条件变量,决定是要把特定源代码编译成模块还是包含到内核中,或者是清除。
- 进入合入了驱动模块的目录,修改改目录下的Makefile,使得合入的驱动源码能编译进内核
- 确认合入内核的驱动在内核启动时自动运行
- 重新编译并启动新内核,dmesg=>确认“hello world”已打印出来
- 带__int标志的函数被放入初始化代码段,内核会依次调用初始化代码段的
- 函数,并在初始化完成后释放 init 区段.
编译成模块
-
模块加载函数(必需) 安装模块时被系统自动调用的函数,通过module_init宏来指定
-
模块卸载函数(必需) 卸载模块时被系统自动调用的函数,通过module_exit宏来指定
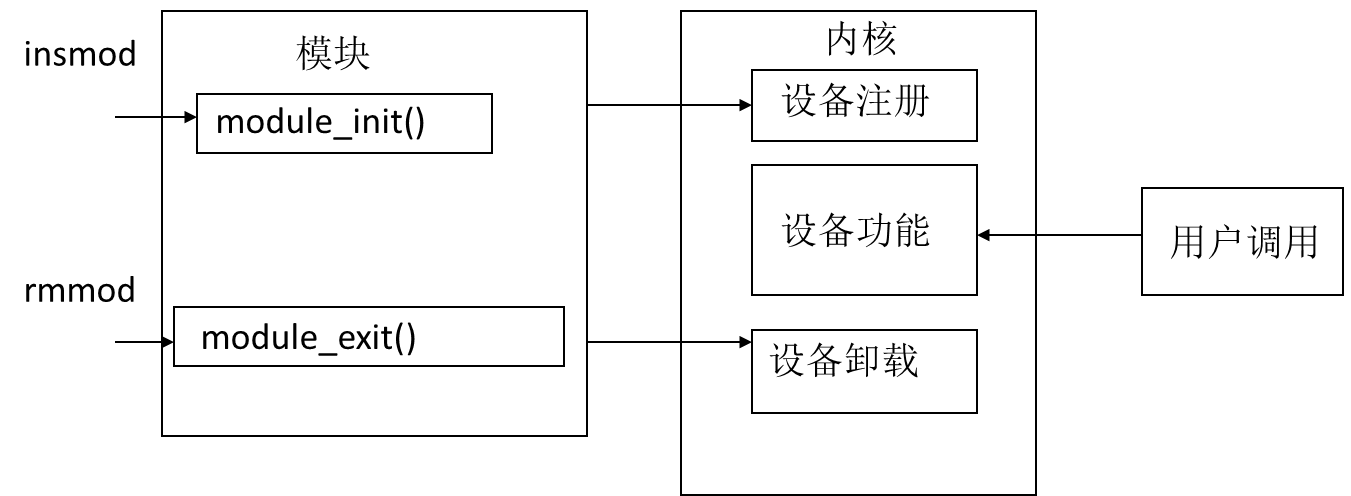 加载 insmod (insmod hello.ko)
卸载 rmmod (rmmod hello)
查看 lsmod
加载 modprobe (modprobe hello)
加载 insmod (insmod hello.ko)
卸载 rmmod (rmmod hello)
查看 lsmod
加载 modprobe (modprobe hello)
modprobe 如同 insmod, 也是加载一个模块到内核。它的不同 之处在于它会根据/lib/modules/<$version>/modules.dep 来查看要加载的模块, 看它是否还依赖于其他模块,如果是, modprobe 会首先找到这些模块, 把它们先加载到内核。
3) 字符设备驱动结构,file_operations 里常用的接口函数、驱动的结构
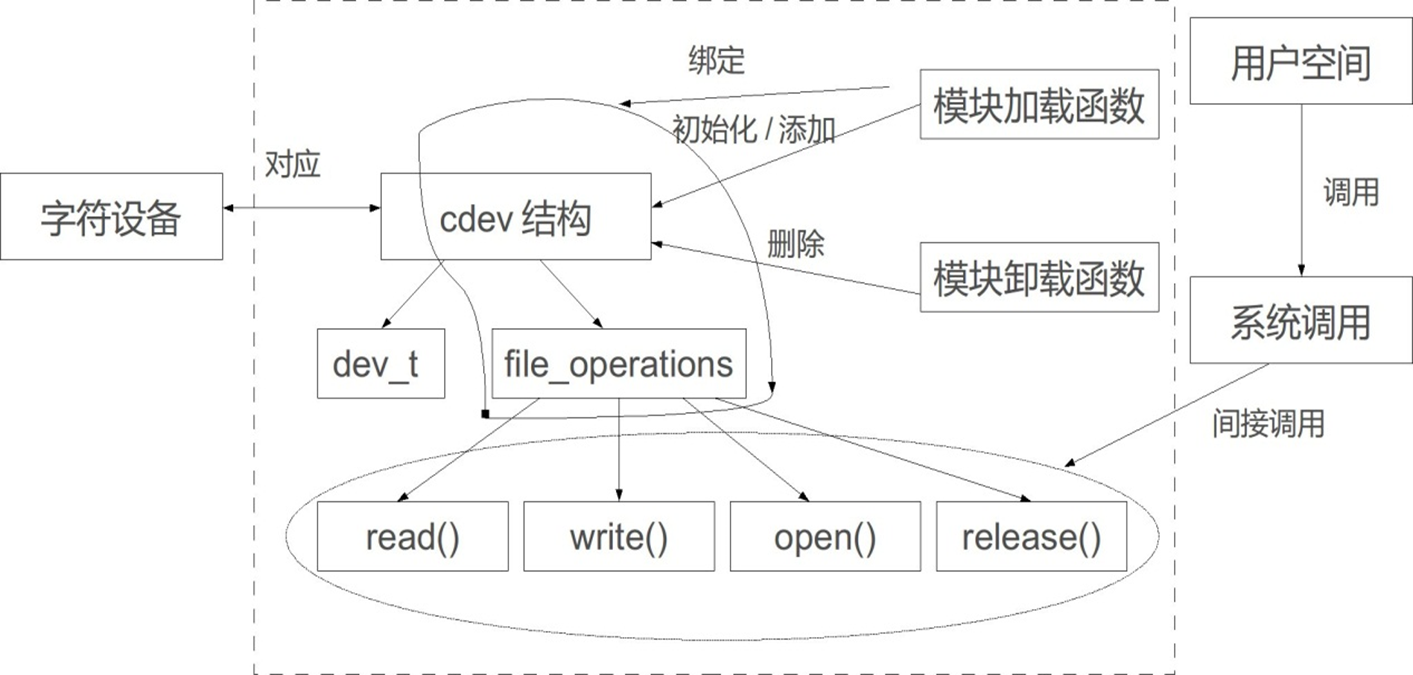
总体结构:
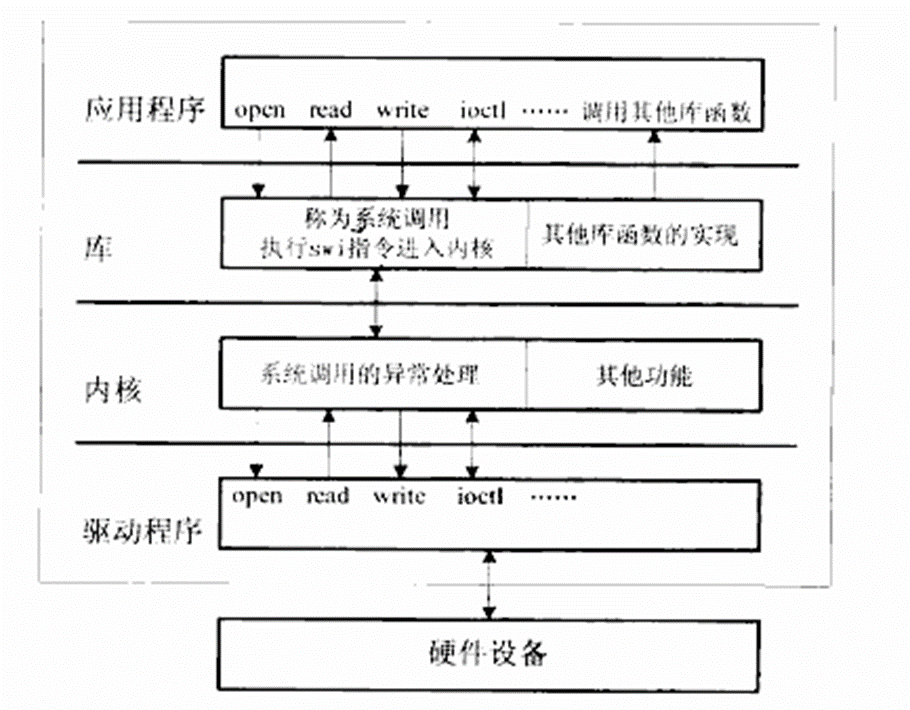
 3、调用关系
(1)当应用程序使用open打开某个设备(/dev的设备文件)
设备驱动程序file_operations结构中open成员函数被调用
3、调用关系
(1)当应用程序使用open打开某个设备(/dev的设备文件)
设备驱动程序file_operations结构中open成员函数被调用
(2)当应用程序使用使用read、write、ioctl等函数读写、控制设备 设备驱动程序file_operations结构中read、write、ioctl等成员函数被调用
4、字符设备驱动程序目的 为具体硬件设备file_operations结构实现操作设备所需的成员函数
5、设备文件与驱动程序file_operations结构的对应关系
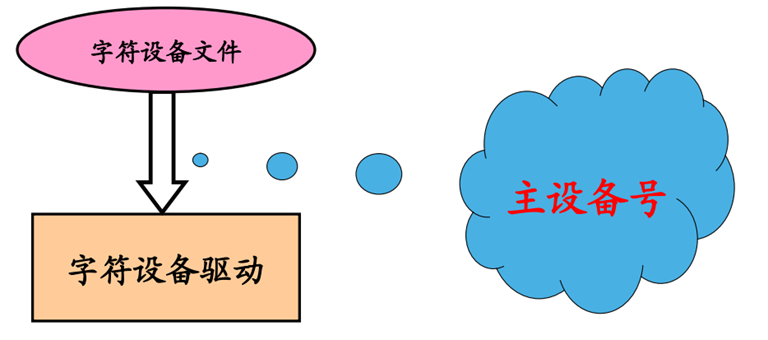 主设备号用来标识与设备文件相连的驱动程序,次编号背驱动程序来辨别操作的是那个设备
主设备号用来反映设备类型
次设备号用来区分同类型的设备
主设备号用来标识与设备文件相连的驱动程序,次编号背驱动程序来辨别操作的是那个设备
主设备号用来反映设备类型
次设备号用来区分同类型的设备
6、设备驱动注册 在驱动中init 函数中实现的。
//老注册接口
register_chrdev(DEV_MAJOR, DEV_NAME, &dev_ops);
//2.6内核使用cdev来描述一个字符设备
cdev_init(&s_cdev, &dev_ops); //初始化cdev
ret = cdev_add(&s_cdev, s_dev, DEV_COUNT); //注册cdev
注册完成后,应用程序操作设备文件时,系统就会根据 主设备号找到内核中注册file_operations结构
驱动程序举例:
字符驱动程序框架
- 包含头文件 编写字符驱动程序时需要的内核头文件
- 定义常量 定义模块的主设备号和名称,它们将在字符设备的初始化的注册函数中使用。
- 函数声明 声明需要使用的函数,将被注册到文件操作数据结构struct file_operations中。
- 文件操作数据结构的指针
static struct file_operations virtual_char_fops={ owner: THIS_MODULE, llseek: virtual_char_llseek, read: virtual_char_read, write: virtual_char_write, ioctl: virtual_char_ioctl, open: virtual_char_open, release: virtual_char_close, }这是驱动程序的核心部分,定义了一个静态文件操作数据结构,将数据结构中几个成员赋值为驱动程序中函数的指针
-
函数中的各种操作 - module_init()注册的函数执行设备文件的注册 - module_exit()注册的函数执行设备文件的卸载。 - open中增加引用计数;close中减少引用计数。 - write/read中执行定义的读写操作,内容传递主要通过缓冲区的指针buf。 - ioctl中执行驱动程序自定义的命令,根据cmd选择要执行的命令
- 应用程序 linux的应用程序与驱动程序调用关系
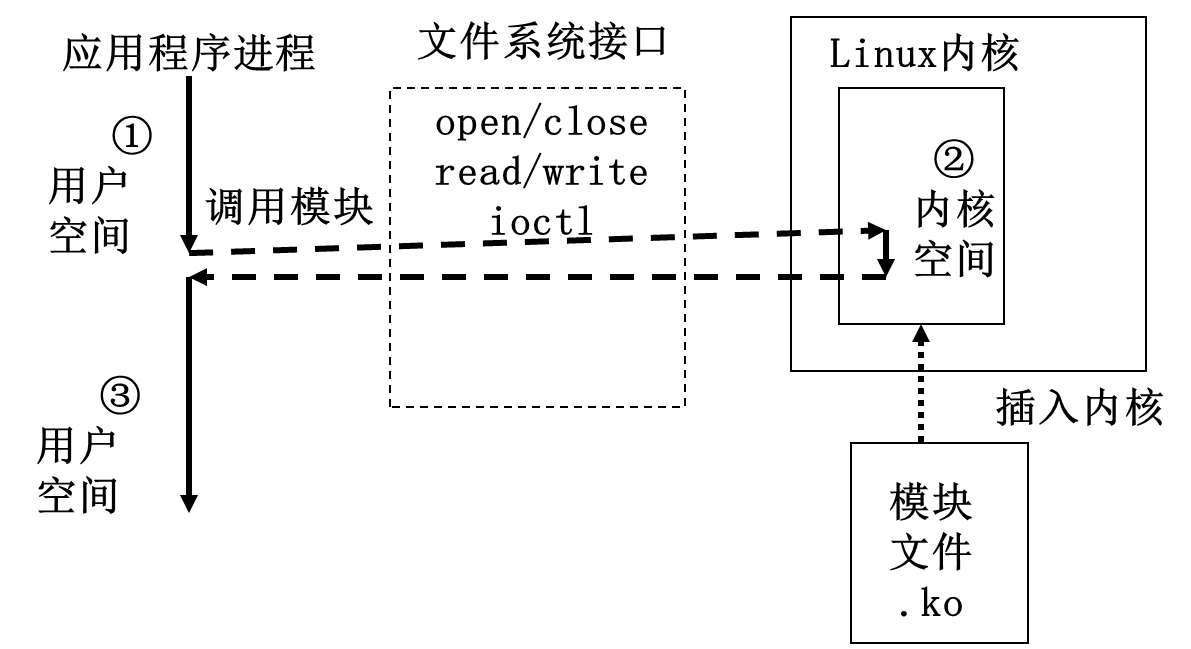 应用程序使用驱动程序主要有以下几个步骤:
应用程序使用驱动程序主要有以下几个步骤:
- 使用open打开设备文件
- 在使用驱动程序的时候,根据需要调用write/read/ioctl等操作
- 使用close关闭设备文件
4) 所有的函数不需要背
第六章 硬件系统设计
1) 典型嵌入式硬件系统组成,主要单元及特点,如 CPU,串口,网络,串口, 看门狗,RTC 时钟,Flash,SDRAM,中断控制器 2) 嵌入式系统硬件调试过程:从最小系统开始
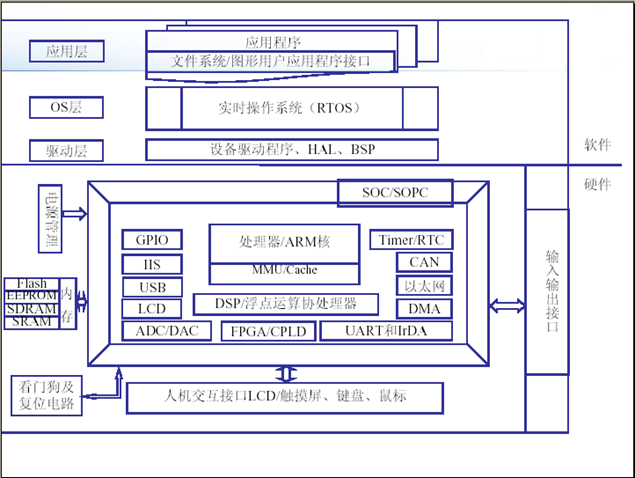
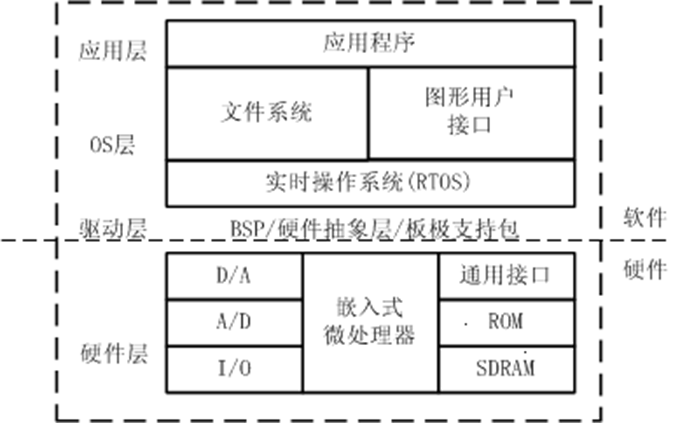
典型嵌入式硬件系统的组成
典型嵌入式系统的体系结构
典型嵌入式系统硬件组成
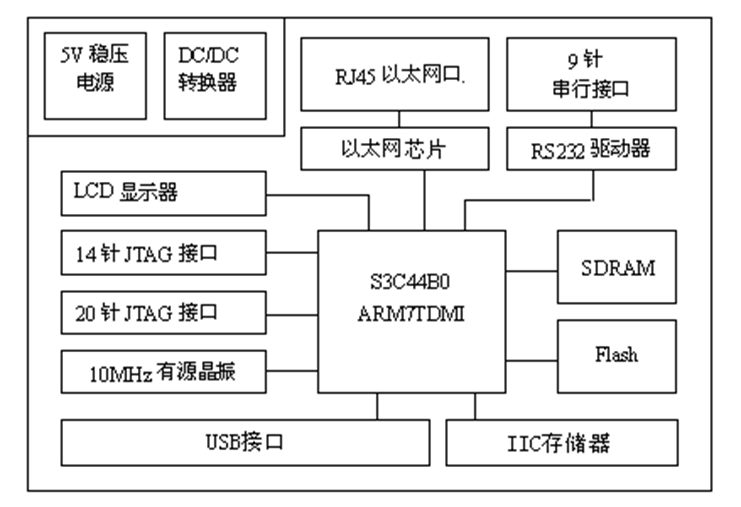
硬件的选择
操作系统
- 如果希望使用 WinCE 或 Linux 等操作系统,就需要选择 ARM 720 T 以上带有 MMU(Memory Management Unit:内存管理单元)功能的 ARM 芯片,如 ARM 720 T、Strong-ARM、ARM 920 T、ARM 922 T、ARM 946 T 都带有 MMU 功能,
- 而 ARM 7 TDMI 没有 MMU,不支持 Windows CE 和大部分的 Linux,但目前有 uClinux 等少数几种 Linux 不需要 MMU 的支持。
主要单元及特点
看门狗与复位电路
- 硬件看门狗 (WDT, WATCHDOG TIMER) 是利用了一个定时器,来监控主程序的运行
- 也就是说在主程序的运行过程中,CPU 要在定时时间到来之前对定时器进行复位 (喂狗)
- 如果出现死循环,或者说 PC 指针不能回来。那么定时时间到达后,如果 CPU 还没有产生喂狗信号给 WDT,WDT 就会输出信号使 CPU 复位。
嵌入式系统中两类看门狗:
- CPU 内部自带的看门狗:将一个芯片中的定时器来作为看门狗,通过程序的初始化,写入初值,设定溢出时间,并启动定时器。程序按时对定时器赋初值(或复位),以免其溢出。
优点:可以通过程序改变溢出时间;可以随时禁用 缺点:需要初始化;如果程序在初始化、启动完成前跑飞或在禁用后跑飞,看门狗就无法复位系统,这样看门狗的作用就没有了,系统恢复能力降低。
- 独立的看门狗芯片:这种看门狗主要有一个用于喂狗的引脚(一般与CPU的GPIO相连)和一个复位引脚(与系统的RESET引脚相连),如果没有在一定时间内改变喂狗脚的电平,复位引脚就会改变状态复位CPU。此类看门狗一上电就开始工作,无法禁用。
优点:无须配置,上电即用。无法禁用,系统必须按时喂狗,系统恢复能力高。 缺点:无法灵活配置溢出时间, 无法禁用,灵活性降低。
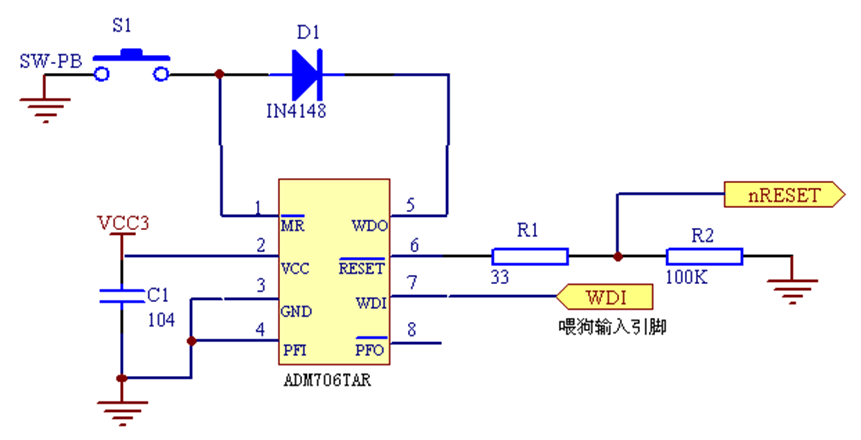 硬件看门狗与复位电路中,按键 S 1 是手动复位按键,ADM 706 TAR 芯片的第 7 脚周期性的按设定的时间间隔检查该引脚的输入信号,如果 CPU 在规定的时间内没有输入高电平(又称为喂狗),则说明程序跑飞了,ADM 706 TAR 的第 6 脚便产生一个复位信号,使 CPU 复位。
硬件看门狗与复位电路中,按键 S 1 是手动复位按键,ADM 706 TAR 芯片的第 7 脚周期性的按设定的时间间隔检查该引脚的输入信号,如果 CPU 在规定的时间内没有输入高电平(又称为喂狗),则说明程序跑飞了,ADM 706 TAR 的第 6 脚便产生一个复位信号,使 CPU 复位。
看门狗定时器
- 看门狗定时器控制寄存器 WTCON
- 看门狗定时器数据寄存器 WTDAT
- 看门狗定时器计数寄存器 WTCNT
看门狗定时器控制寄存器
——WTCON 0 x 01 D 30000 R/W 初始值 0 x 8021
BIT 描述 [15:8] 预分频 prescaler 值(0 to (2 ^8 -1) [7:6] 保留 [5] 看门狗定时器的允许(启动)位 0 = Disable watchdog timer 1 = Enable watchdog timer Clock select
[4:3] 时钟除因子 (分割) 00: 1/16 01: 1/32 10: 1/64 11: 1/128 [2] 看门狗中断允许位 0 = Disable interrupt generation 1 = Enable interrupt generation [1] 保留
[0] 看门狗输出复位信号的允许位—– 1: 允许 0: 不允许
看门狗定时器数据寄存器
——-WTDAT 0 x 01 D 30004 R/W 初始值 0 x 8000
- WTDAT 规定看门狗定时器超时周期。
- WTDAT 的内容在初始操作时,不能自动加载进定时器计数寄存器 WTCNT。
- 可是定时器计数寄存器在使用初始值 0 X 8000 第一次超时出现以后,WTDAT 的值将自 动加载进 WTCNT。
存储单元
嵌入式系统内存映射的示意图,显示不同的内存区域及其对应的地址范围
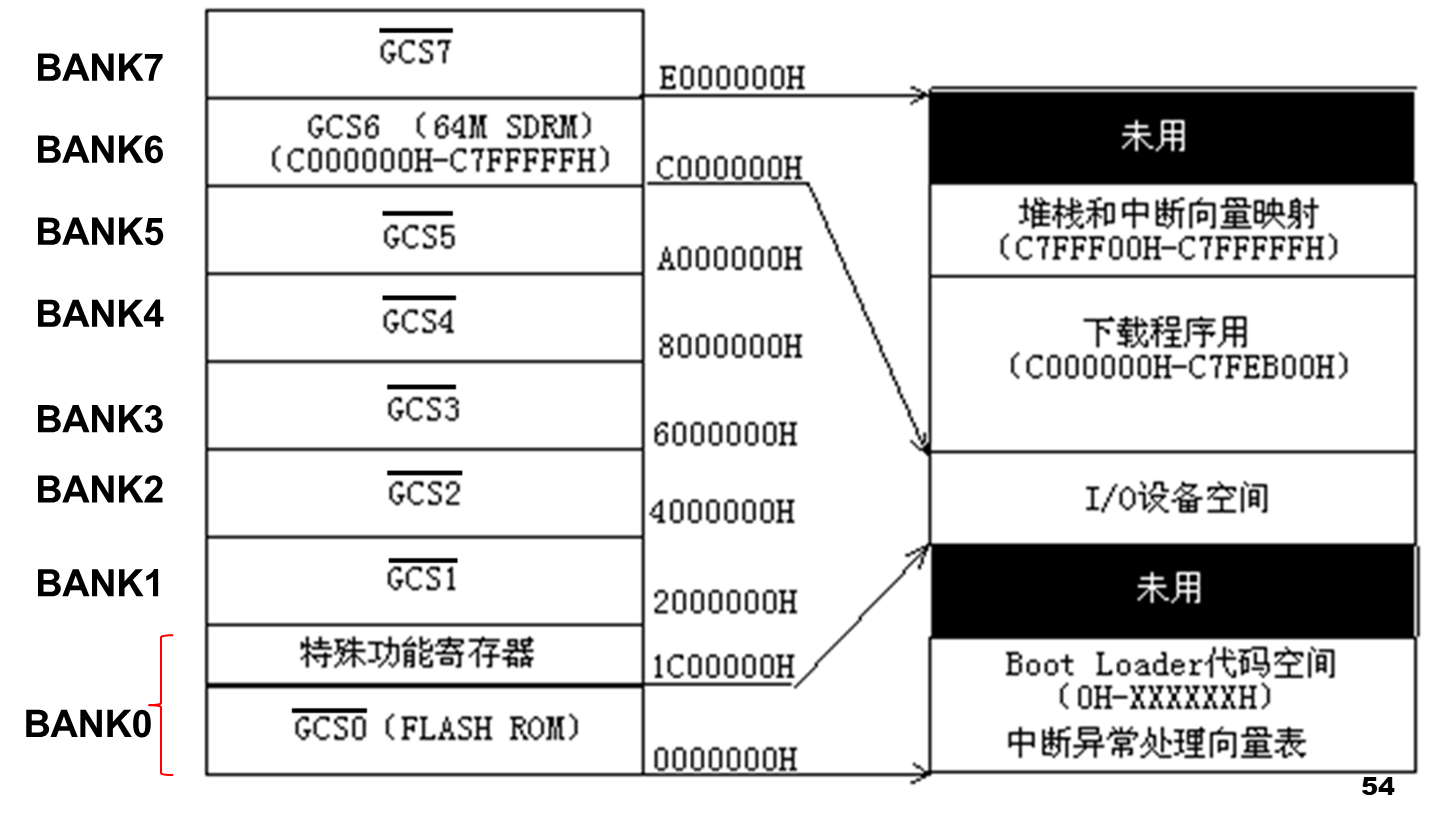 例子:
例子:
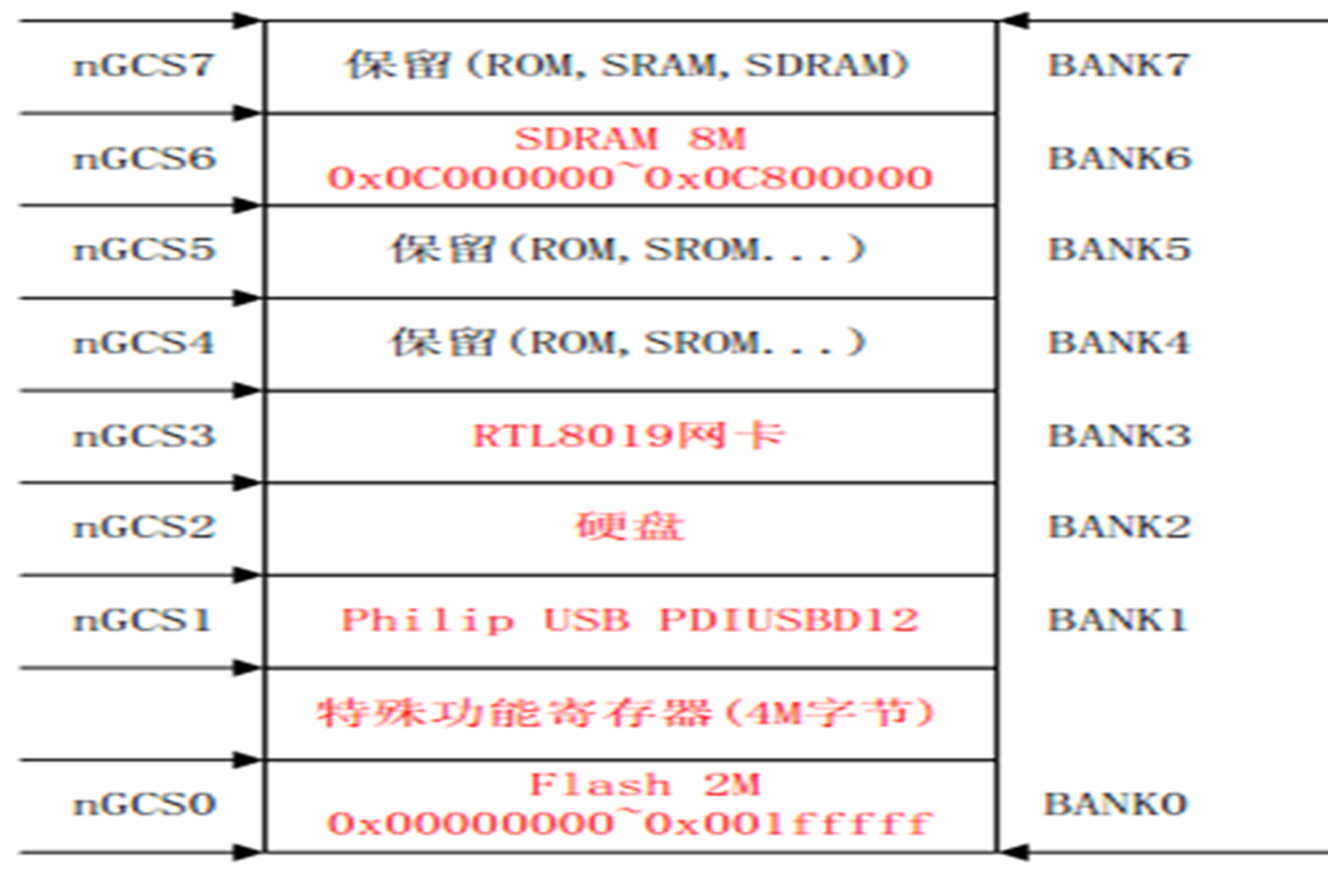

-
在程序空间 flash ROM 内(在主板上对应 2 M 字节大小的 HY 29 LV 160 器件)可以固化一段启动系统并对系统进行初始化的程序——Boot Loader 程序。
- 上图中 Flash ROM 存储器映射在了系统的 bank 0 上,也就是说,系统上电时处理器即从 Flash ROM 的 0 x 00000000 地址处取得指令开始运行。
- 这个地址上的 Boot Loader 程序完成了时钟设置初始化、中断矢量的定义、存储器的参数设置、堆栈地址定义等工作,这些设置对于系统正常启动是非常重要的。
- 由于 Flash ROM 是非易失性的存储器,因此程序就算掉电也不会丢失。
- 但是如果由于某个误操作覆盖了 Flash ROM 中启动程序的内容,系统就将无法正常启动,这时就需要重新将 Boot Loader 程序烧写到 Flash ROM 中

- 系统的 SDRAM 器件映射在 bank 6 上,也就是 0 x 0 C 000000 地址处。
- SDRAM 是易失性的可快速擦写的存储器,因此它通常作为系统的数据空间,同时也作为系统程序的运行空间,当系统上电后,程序将从 flash ROM 存储器被拷贝到 SDRAM 中运行,这样将大大提高程序的运行速度。
- 当然,系统掉电后,SDRAM 中的程序就消失了,下次上电时,程序将又从 flash ROM 存储器被拷贝到 SDRAM 中运行。
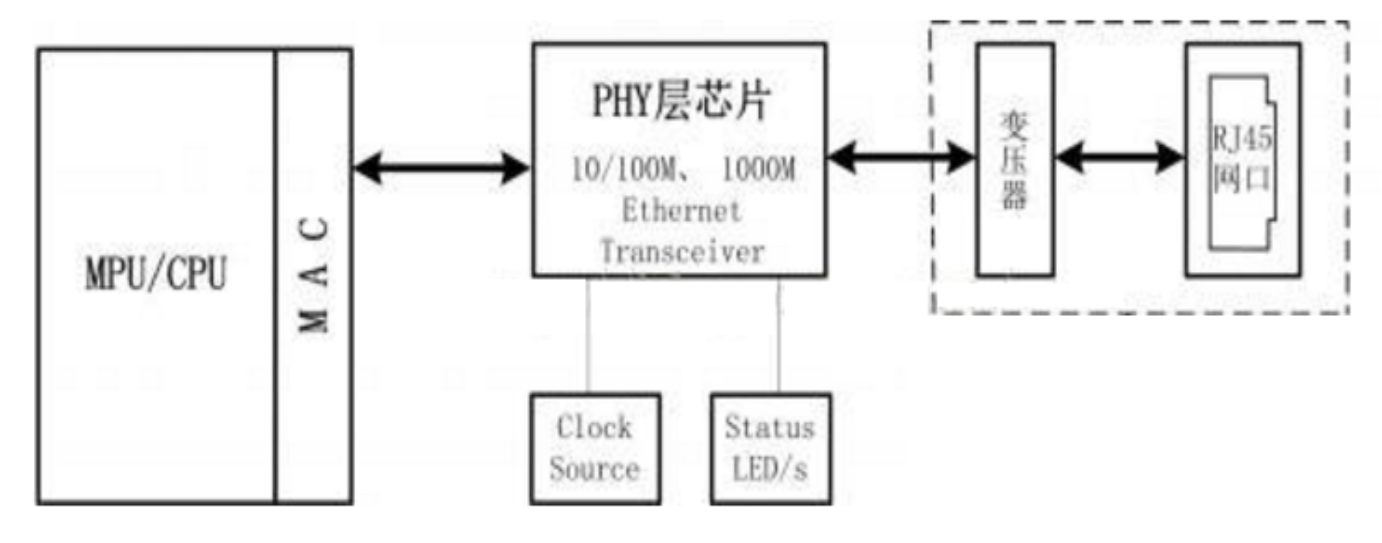
网络接口电路
从硬件的角度看,以太网接口电路两大部分:
- MAC(Medium Access Control)控制器
- 物理层接口(Physical Layer,PHY)
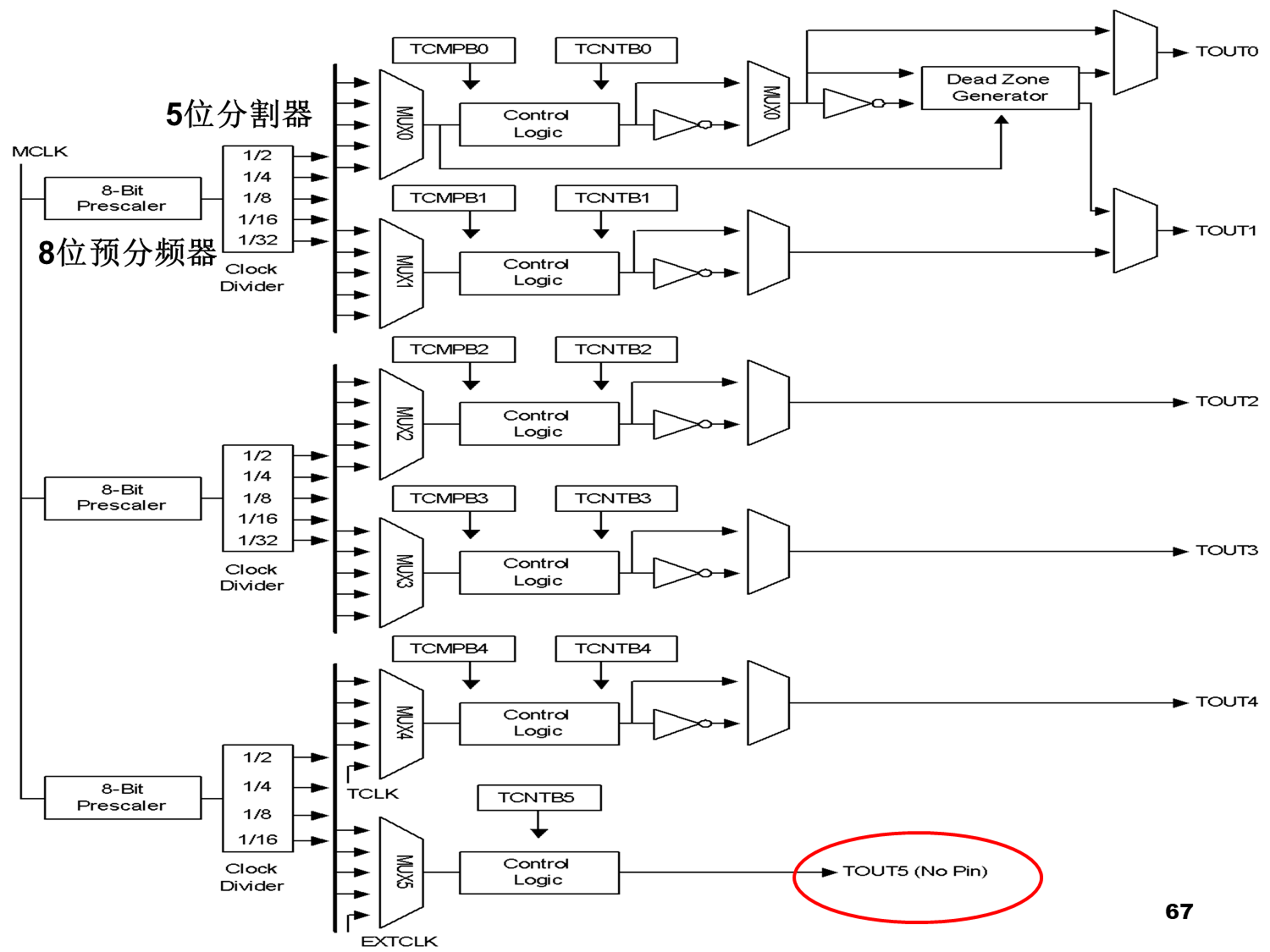
PWM 定时器
- 6个16 位定时器;
- 3个8 位预分频器
- 2个5位分割器
- 1个4位分割器;
- 输出波形的占空比可编程控制(PWM)
- 自动加载模式或单触发脉冲模式;
- 支持外部中断源;
- 看门狗定时器溢出产生复位信号。
PWM 定时操作
定时器0和1分享一个8位预分频器 + 一个5位分割器 定时器2和3分享一个8位预分频器 + 一个5位分割器 定时器4和5分享一个8位预分频器 + 一个4位分割器
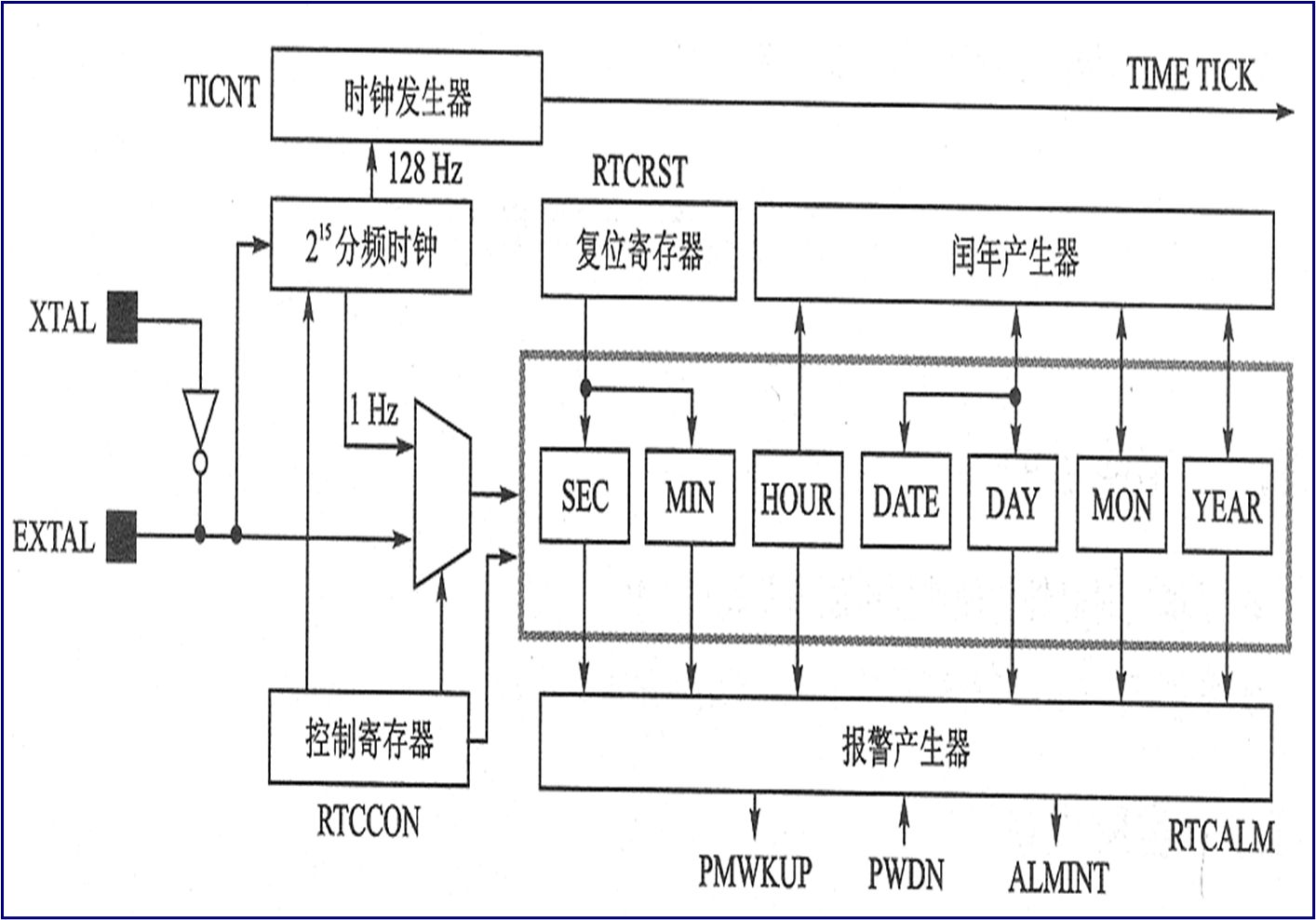
RTC
- RTC 单元能在系统断电时, 通过备份电池来供电
- RTC 能通过 ARM 的 STRB/LDRB 指令传输 8 位数据到 CPU
- RTC 使用一个外部 32.768 kHz 的晶体
- 报警功能。
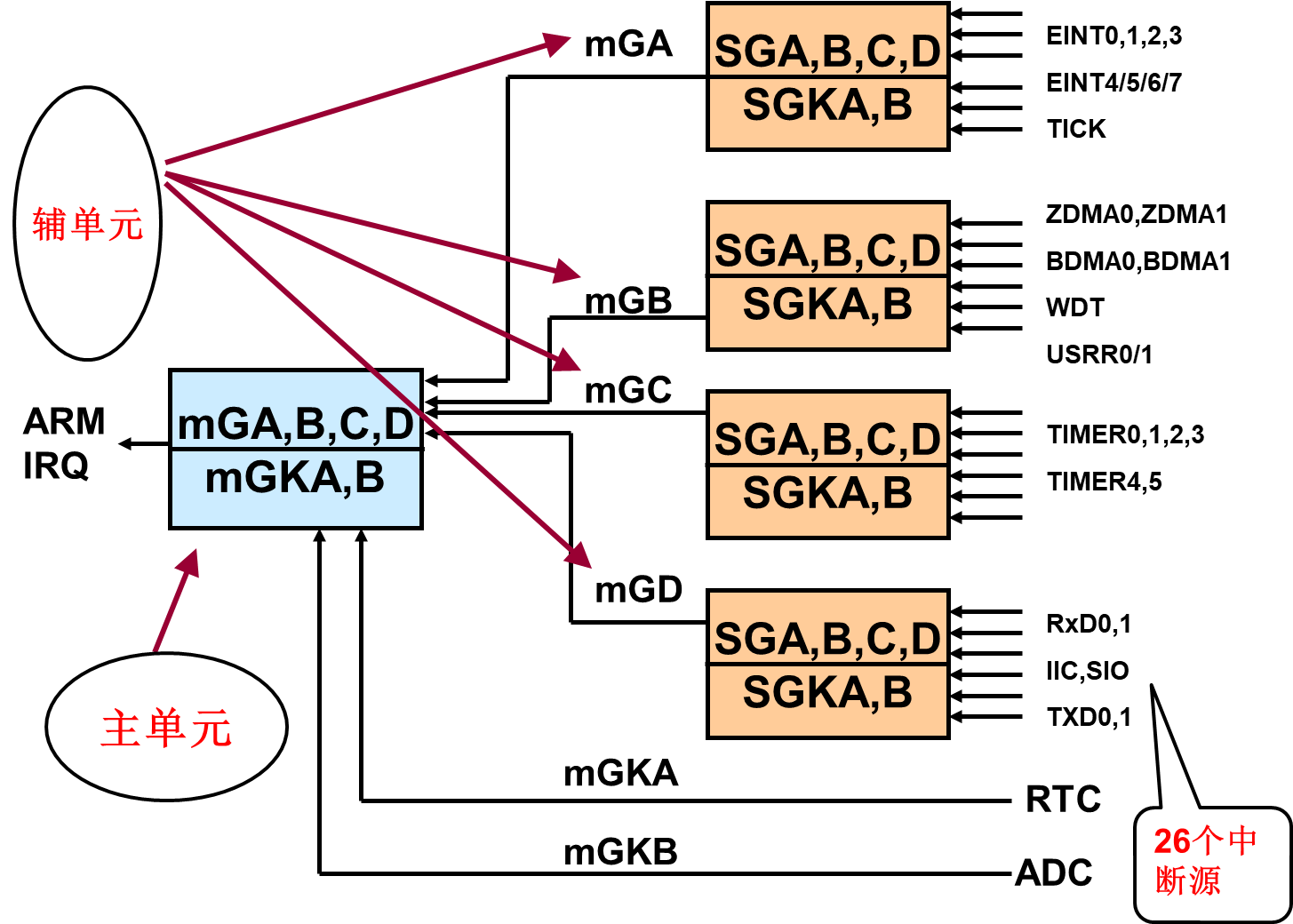
中断控制器
- S 3 C 44 B 0 X 的中断控制器可以接收来自 30 个中断源的请求。
- 中断控制器的作用,就是响应来自 FIQ 或 IRQ 的中断,并请求内核对中断进行处理。
- 当有多个中断同时发生的时候,中断控制器要决定首先处理哪一个中断。
ARM7TDMI 有 2 种类型的中断模式:
- FIQ(快速中断请求)
- IRQ(普通中断请求)
CPSR 指 ARM7TDMI 处理器的程序状态寄存器。
- 如果 CPSR 的 F 位被设置为 1,处理器将不接受来自中断控制器的 FIQ。
- 如果 CPSR 的 I 位被设置为 1,处理器将不接受来自中断控制器的 IRQ。
因此,为了使能中断响应机制:
- CPSR 的 F 位或 I 位必须被清 0,
- 同时 INTMASK( 中断屏蔽寄存器 )的相应位必须被清 0。
在 30 个中断源中 合并后以26 个中断源信号提供给中断控制器。
| 中断源 | 对应控制位 | 中断源 | 对应控制位 | | ————— | —— | ———- | —— | | 外部中断0 | [ 25 ] | 定时器1中断 | [ 12 ] | | 外部中断1 | [ 24 ] | 定时器2中断 | [ 11 ] | | 外部中断2 | [ 23 ] | 定时器3中断 | [ 10 ] | | 外部中断3 | [ 22 ] | 定时器4中断 | [ 9 ] | | 外部中断4/5/6/7 | [ 21 ] | 定时器5中断 | [ 8 ] | | RTC时间滴答中断 | [ 20 ] | UART0接收中断 | [ 7 ] | | ZDMA0中断 | [ 19 ] | UART1接收中断 | [ 6 ] | | ZDMA1中断 | [ 18 ] | IIC-中断 | [ 5 ] | | BDMA0中断 | [ 17 ] | SIO-中断 | [ 4 ] | | BDMA1中断 | [ 16 ] | UART0 发送中断 | [ 3 ] | | 看门狗中断 | [ 15 ] | UART1发送中断 | [ 2 ] | | UART0/1错误中断 | [ 14 ] | RTC报警中断 | [ 1 ] | | 定时器0中断 | [ 13 ] | ADC转换结束中断 | [ 0 ] | 中断优先级产生模块包含5个单元:
• 1个主单元–(主单元管理4个辅单元和2个中断源) • 4个辅单元–(每个辅单元管理6个中断源)
最小系统
- S 3 C 44 B 0 X 最小系统 + SDRAM + FLASH 电路可构成一个完全的嵌入式系统
- 可运行 SDRAM 中的程序,也可以运行 FLASH 中的程序
- 程序规模可以很大,如果将程序保存到 FLASH 中,掉电后不会丢失,因此,既可以通过 JTAG 接口调试程序,也可以将程序烧写到 FLASH,然后运行 FLASH 中的程序
- 在此基础上加入必要的接口及其他电路,就构成了具体的 S 3 C 44 B 0 X 应用系统
硬件调试
- 尽可能的从简单到复杂,一个单元一个单元地焊接调试,以便在调试过程中遇到困难时缩小故障范围,在调试过程中,应先确定电路没有短路,才能通电调试。
- 先从最小系统调试: S 3 C 44 B 0 X + 电源电路 + 晶振电路 + 复位电路 + JTAG 接口
- 然后加上 SDRAM,再加上 FLASH,然后再加上其它接口
-
芯片在工作时有一定的发热是正常的,但如果有芯片特别发烫,则一定有故障存在,需断电检查确认无误后方可继续通电调试。
- 调试电源电路之前,尽量少接器件,通电之前检查有无短路现象
- 用示波器观测,晶振的输出应为10MHz
- 复位电路的nRESET端在未按按钮时输出应为高电平(3.3V),按下按钮后变为低电平,按钮松开后应恢复到高电平