

《编译原理实验》
实验报告
| 题 目 | : | 第⼀次实验 词法分析 |
| 姓 名 | : | 高星杰 |
| 学 号 | : | 2021307220712 |
| 专 业 | : | 计算机科学与技术 |
| 上课时间 | : | 2024春 |
| 授课教师 | : | 刘善梅 |
2024 年 3月 28 日
[TOC]
编译原理 第一次实验 词法分析
实验目的
- 设计、编制并调试一个简单的词法分析程序。
- 加深对词法分析原理的理解
实验要求
根据PL/0语言的文法规范,编写PL/0语言的词法分析程序。要求:
- 把词法分析器设计成一个独立一遍的过程。
- 词法分析器的输出形式采用二元式序列,即:(单词种类, 单词的值)
[!important]
【PL语言简介】
PL0语言功能简单、结构清晰、可读性强,而又具备了一般高级程序设计语言的必须部分,因而PL0语言的编译程序能充分体现一个高级语言编译程序实现的基本方法和技术。
1.PL/0语言文法的EBNF
1.1 符号说明:
‘<>’用左右尖括号括起来的中文字表示语法构造成分,或称语法单位,为非终结符。
‘::=’该符号的左部由右部定义,可读作“定义为”。
‘ ’表示“或”,为左部可由多个右部定义. ‘{}’表示花括号内的语法成分可以重复。在不加上下界时可重复0到任意次数,有上下界时为可重复次数的限制。
‘[]’表示方括号内的成分为任选项。
‘()’表示圆括号内的成分优先。上述符号称“元符号”,定义文法用到上述符号作为文法符号时需要引号‘’括起。
1.2 PL/0 语言文法的EBNF:
<程序>::=<分程序>. <分程序> ::=[<常量说明>\]\[<变量说明>][<过程说明>]<语句> <常量说明> ::=CONST<常量定义>{,<常量定义>}; <常量定义> ::=<标识符>=<无符号整数> <无符号整数> ::= <数字>{<数字>} <变量说明> ::=VAR <标识符>{, <标识符>}; <标识符> ::=<字母>{<字母>|<数字>} <过程说明> ::=<过程首部><分程序>{; <过程说明> }; <过程首部> ::=PROCEDURE <标识符>; <语句> ::=<赋值语句>|<条件语句>|<当循环语句>|<过程调用语句> |<复合语句>|<读语句><写语句>|<空> <赋值语句> ::=<标识符>:=<表达式> <复合语句> ::=BEGIN <语句> {;<语句> }END <条件语句> ::= <表达式> <关系运算符> <表达式> |ODD<表达式> <表达式> ::= [+|-]<项>{<加法运算符> <项>} <项> ::= <因子>{<乘法运算符> <因子>} <因子> ::= <标识符>|<无符号整数>| ‘(’<表达式>‘)’ <加法运算符> ::= +|- <乘法运算符> ::= *|/ <关系运算符> ::= =|#|<|<=|>|>= <条件语句> ::= IF <条件> THEN <语句> <过程调用语句> ::= CALL 标识符 <当循环语句> ::= WHILE <条件> DO <语句> <读语句> ::= READ‘(’<标识符>{,<标识符>}‘)’ <写语句> ::= WRITE‘(’<表达式>{,<表达式>}‘)’ <字母> ::= a|b|…|X|Y|Z <数字> ::= 0|1|…|8|9 **2.PL/0语言的词汇表** | **序号** | **类别** | **单词** | **编码** | | -------- | ---------- | ------------------------------------------------------------ | ------------------------------------------------------------ | | **1** | **基本字** | begin, call, const, do, end if, odd, procedure, read then, var, while, write | **beginsym, callsym, constsym** **dosym, endsym, ifsym, oddsym** **,** **proceduresym, readsym, thensym** **,** **varsym, whilesym, writesym** | | **2** | **标识符** | | **ident** | | **3** | **常数** | | **number** | | **4** | **运算符** | +, -, \*, /, odd =, <>, <, <=, >, >=, := | **plus, minus, times, slash, oddsym** **,** **eql, neq, lss, leq, gtr, geq, becomes** | | **5** | **界符** | ( ) , ; . | **lparen, rparen, comma, semicolon** **,** **period** |
设计思想
要想手工设计词法分析器,实现PL/0语言子集的识别,就要明白什么是词法分析器,它的功能是什么。词法分析是编译程序进行编译时第一个要进行的任务,主要是对源程序进行编译预处理(去除注释、无用的回车换行找到包含的文件等)之后,对整个源程序进行分解,分解成一个个单词,这些单词有且只有五类,分别是标识符、保留字、常数、运算符、界符。以便为下面的语法分析和语义分析做准备。可以说词法分析面向的对象是单个的字符,目的是把它们组成有效的单词(字符串);而语法的分析则是利用词法分析的结果作为输入来分析是否符合语法规则并且进行语法制导下的语义分析,最后产生四元组(中间代码),进行优化(可有可无)之后最终生成目标代码。可见词法分析是所有后续工作的基础,如果这一步出错,比如明明是‘<=’却被拆分成‘<’和‘=’就会对下文造成不可挽回的影响。因此,在进行词法分析的时候一定要定义好这五种符号的集合。
首先我们可以从需求入手,然后再尝试设计出一个词法分析器。
1 预计成果
词法分析的成果就是由一系列单词符号构成的单词流。单词符号其实就是 token,一般有以下五大类:
- 关键字:例如
while,if,int等 - 标识符:变量名、常量名、函数名等
- 常数:例如,
100,'text',TRUE等 - 运算符:例如
+,*,/等 - 界符:逗号,分号,括号,点等
具体来说,一个单词符号在形式上是这样的一个二元式:(单词种别,单词符号的属性值)
[!tip]
为了更好的解释,这里解释一下两个概念:
单词种别:
单词种别通常用整数编码。一个语言的单词符号如何分种,分成几种,怎样编码是一个技术问题。它取决于处理上的方便。
- 标识符一般统归为一种。比如说变量
a和b,可能我们都只用1作为它们的单词种别。- 常数则宜按类型(整、实、布尔等)分种,比如说整数可能用
2表示,布尔值可能用3表示。- 关键字可以把全体视为一种,也可以一字一种。
- 运算符可以把具有一定共性的运算符视为一种,也可以一符一种。
- 界符一般是一符一种。
单词符号的属性值
由上面的单词种别可以知道,关键字、运算符、界符基本都是一字(或者一符)对应一个种别,所以只依靠单词种别即可确切地判断出具体是哪一种单词符号了。但是标识符和常数却不是这样,一个种别可能对应好几个单词符号。所以我们需要借助单词符号的属性值做进一步的区分。
对于标识符类型的单词符号,它的属性值通常是一个指针,这个指针指向符号表的某个表项,这个表项包含了该单词符号的相关信息;对于常数类型的单词符号,它的属性值也是一个指针,这个指针指向常数表的某个表项,这个表项包含了该单词符号的相关信息。
而我们要生成的单词种别是PL/0的单词种别,实验的要求中已经全部给出了单词种别,我们要做的就是要识别每个单词是属于哪个单词种别的。 然后我们最终的输出结构就用token这种数据结构给出。
2 设计要点
2.1 是否作为一趟?
按照我们常规的想法,应该是词法分析器扫描整个源程序,产生单词流,之后再由语法分析器分析生成的单词。如果是这样,那么就说词法分析器独立负责了一趟的扫描。但其实,更多的时候我们认为词法分析器并不负责独立的一趟,而是作为语法分析器的子程序被调用。也就是说,一上来就准备对源程序进行语法分析,但是语法分析无法处理字符流,所以它又回过头调用了词法分析器,将字符流转化成单词流,再去分析它的语法。以此类推,后面每次遇到字符串流,都是这样的一个过程。
但是由于我们仅仅要实现词法分析,不涉及语法分析,所以我们这里实现的是作为一趟。
2.2 输入和预处理
字符流输入后首先到达输入缓冲区,在词法分析器正式对它进行扫描之前,还得先做一些预处理的工作。预处理子程序会对一定长度的字符流进行处理,包括去除注释、合并多个空白符、处理回车符和换行符等。处理完之后再把这部分字符流送到扫描缓冲区。此时,词法分析器才正式开始拆分字符流的工作。
这里我们可以直接使用input来模拟字符流的输入,然后使用一些方法进行预处理
2.3 超前扫描
像 FORTRAN 这样的语言,关键字不加保护(只要不引起矛盾,用户可以用它们作为普通标识符),关键字和用户自定义的标识符或标号之间没有特殊的界符作间隔。这使得关键字的识别变得很麻烦。比如 DO99K=1,10 和 DO99K=1.10。前者的意思是,K 从 1 变到 10 之后,跳转到第 99 行执行;后者的意思是,为变量 DO99K 赋值 1.10。问题在于,我们并不能在扫描到 DO 的时候就肯定这是一个关键字,事实上,它既有可能是关键字,也有可能作为标识符的一部分。而具体是哪一种,只有在我们扫描到 =1 后面才能确定 —— 如果后面是逗号,则这是关键字,如果是点号,则是标识符的一部分。
但是我们这里使用PL/0,对关键词是有保护的,所以我们无需进行超前扫描
3 设计词法分析的模型
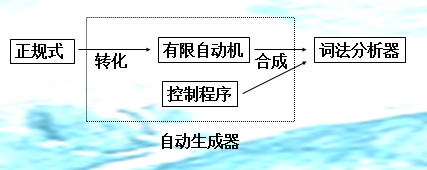
3.1 单词种类及其正规式
- 基本字
| 单词的值 | 单词类型 | 正规式 |
|---|---|---|
| begin | beginsym | begin |
| call | callsym | call |
| const | constsym | const |
| do | dosym | do |
| end | endsym | end |
| if | ifsym | if |
| odd | oddsym | odd |
| procedure | proceduresym | procedure |
| read | readsym | read |
| then | thensym | then |
| var | varsym | var |
| while | whilesym | while |
| write | writesym | write |
- 标识符
| 单词的值 | 单词类型 | 正规式 |
|---|---|---|
| 标识符 | ident | (字母)(字母|数字)* |
- 常数
| 单词的值 | 单词类型 | 正规式 |
|---|---|---|
| 常数 | number | (数字)(数字)* |
- 运算符
| 单词的值 | 单词类型 | 正规式r |
|---|---|---|
| + | plus | + |
| - | minus | - |
| * | times | * |
| / | slash | / |
| = | eql | = |
| <> | neq | <> |
| < | lss | < |
| <= | leq | <= |
| > | gtr | > |
| >= | geq | >= |
| := | becomes | := |
- 界符
| 单词的值 | 单词类型 | 正规式 |
|---|---|---|
| ( | lparen | ( |
| ) | rparen | ) |
| , | comma | , |
| ; | semicolon | ; |
| . | period |
3.2 根据正规式构造NFA
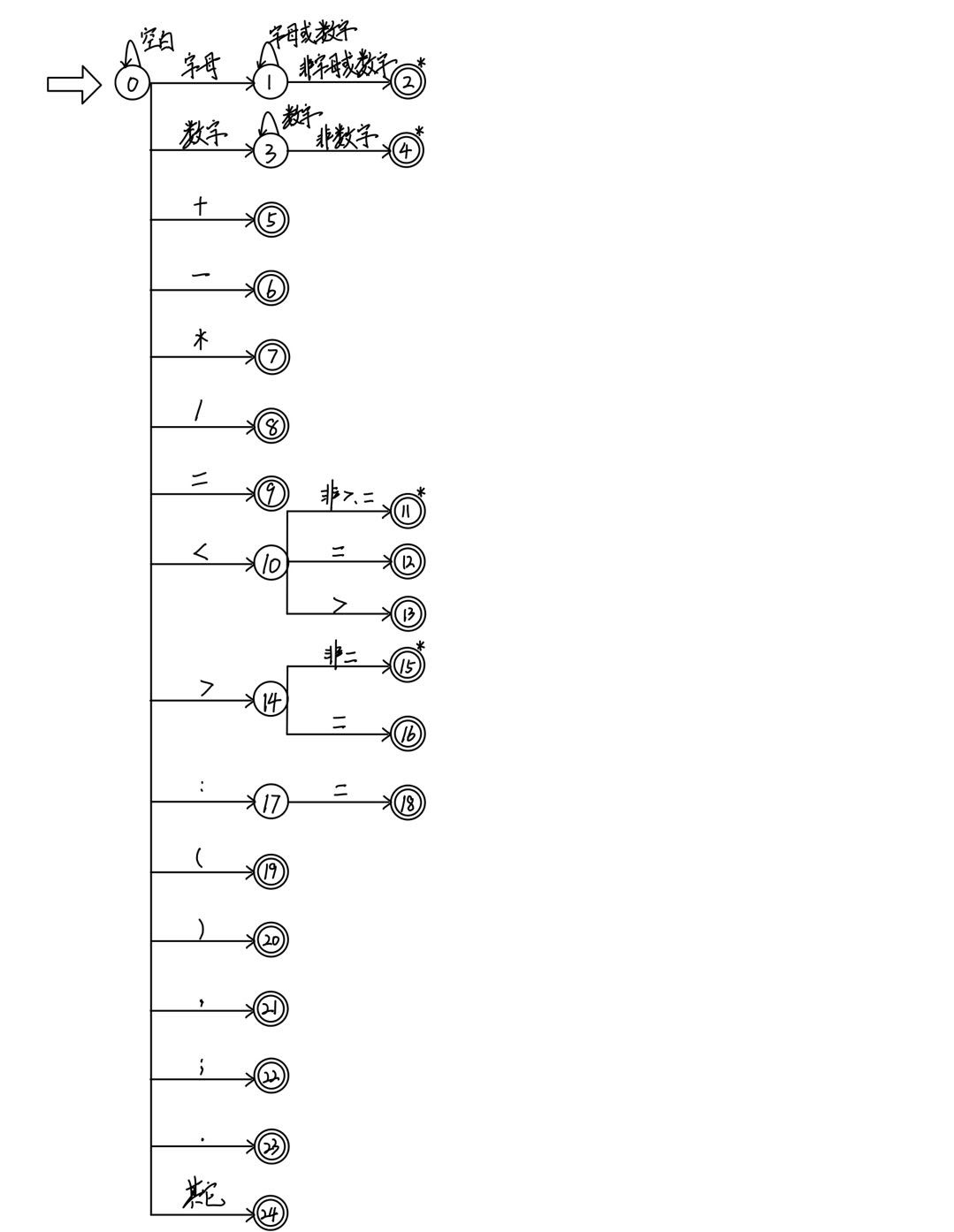
3.3 将NFA转换为DFA
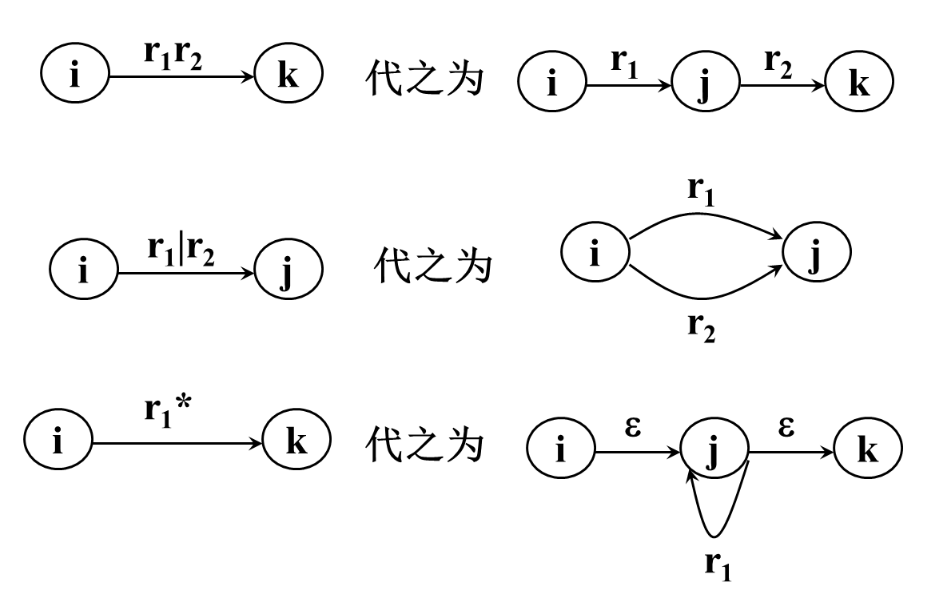
使用这三个规则实现转换
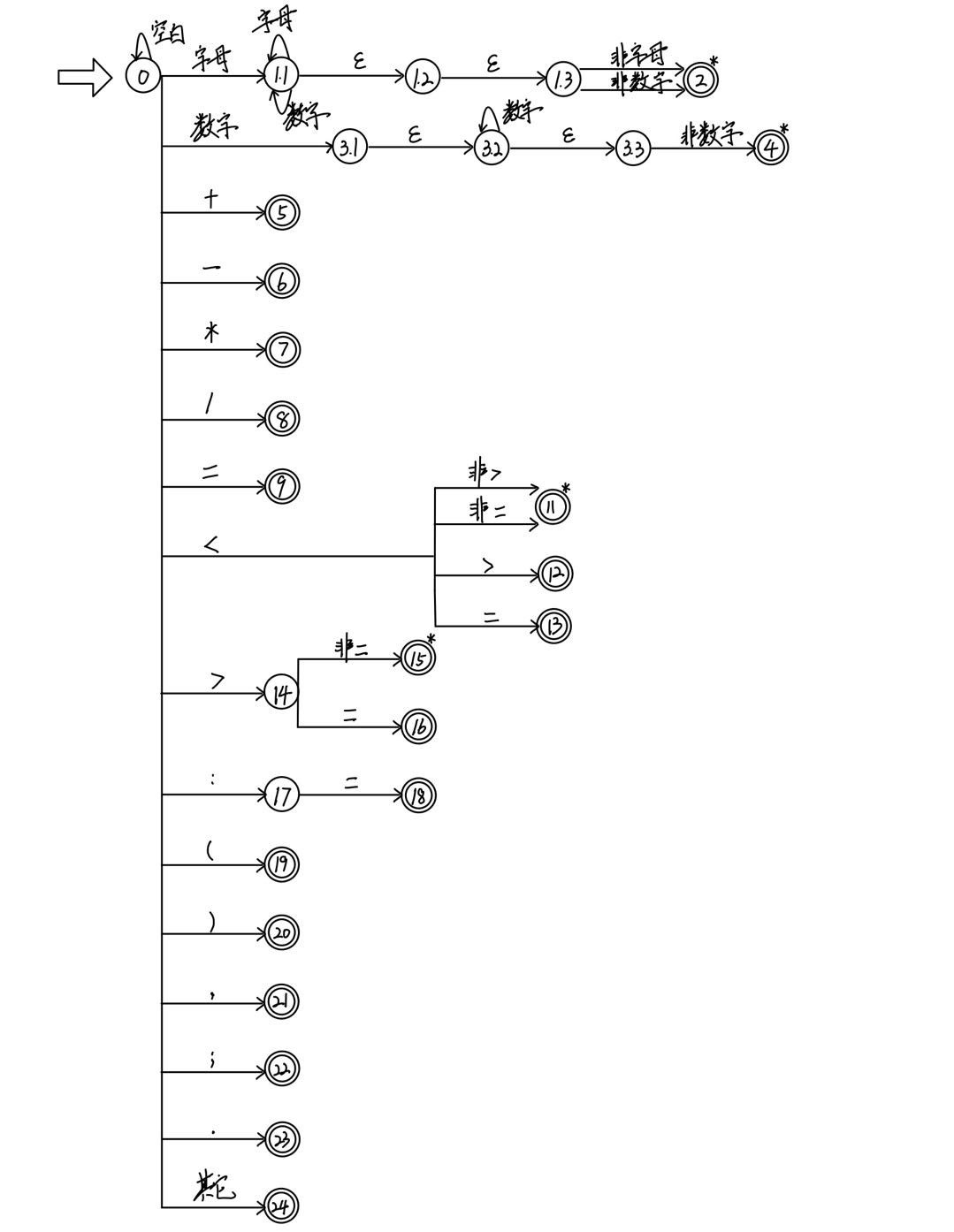
3.3 最小化DFA
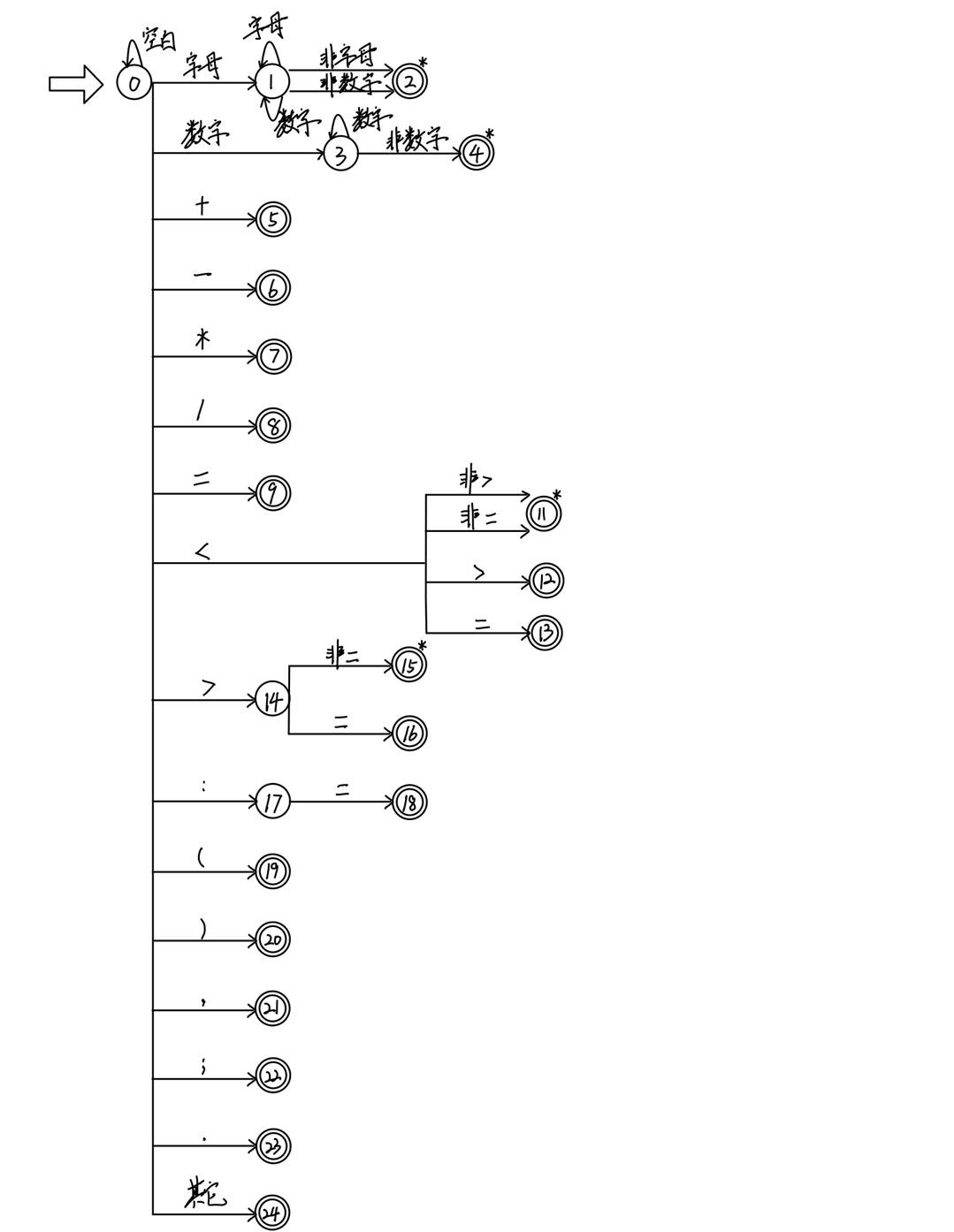
算法流程
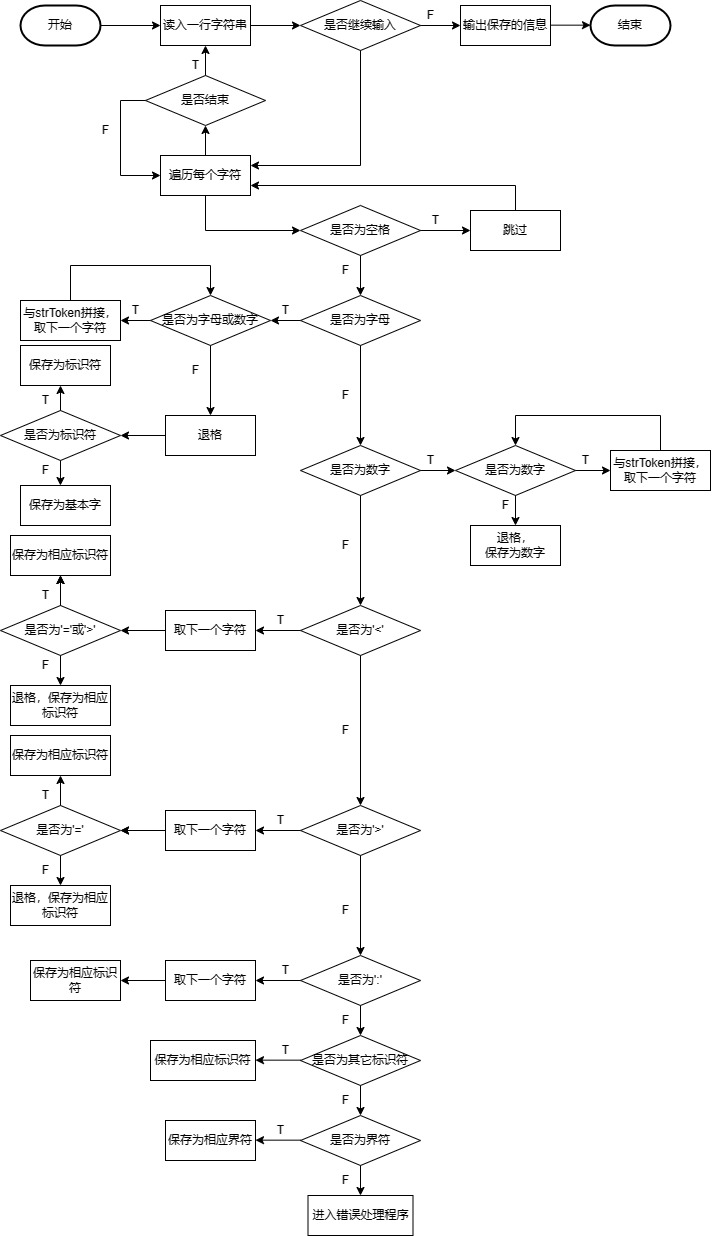
下面说一下整个程序的流程:
- 词法分析程序打开源文件,读取文件内容,直至遇上’$’文件结束符,然后读取结束。
- 对读取的文件进行预处理,从头到尾进行扫描,去除//和/* */的内容,以及一些无用的、影响程序执行的符号如换行符、回车符、制表符等。但是千万注意不要在这个时候去除空格,因为空格在词法分析中有用,比如说int i=3;这个语句,如果去除空格就变成了“inti=3”,这样就失去了程序的本意,因此不能在这个时候去除空格。
- 选下面就要对源文件从头到尾进行扫描了,从头开始扫描,这个时候扫描程序首先要询问当前的字符是不是空格,若是空格,则继续扫描下一个字符,直至不是空格,然后询问这个字符是不是字母,若是则进行标识符和保留字的识别;若这个字符为数字,则进行数字的判断。否则,依次对这个字符可能的情况进行判断,若是将所有可能都走了一遍还是没有知道它是谁,则认定为错误符号,输出该错误符号,然后结束。每次成功识别了一个单词后,单词都会存在token[ ]中。然后确定这个单词的种别码,最后进行下一个单词的识别。这就是扫描程序进行的工作,可以说这个程序彻底实现了确定有限自动机的某些功能,比如说识别标识符,识别数字等。为了简单起见,这里的数字只是整数。
- 主控程序主要负责对每次识别的种别码syn进行判断,对于不同的单词种别做出不同的反应,如对于标识符则将其插入标识符表中。对于保留字则输出该保留字的种别码和助记符,等等吧。直至遇到syn=0;程序结束。
源程序
from enum import Enum, auto
# 定义一个名为TokenType的枚举类型,表示所有可能的标记类型。
class TokenType(Enum):
# 下面的每一行都是定义一个标记类型,例如BEGINSYM、CALLSYM等。
BEGINSYM = auto()
CALLSYM = auto()
CONSTSYM = auto()
DOSYM = auto()
ENDSYM = auto()
IFSYM = auto()
ODDSYM = auto()
PROCEDURESYM = auto()
READSYM = auto()
THENSYM = auto()
VARSYM = auto()
WHILESYM = auto()
WRITESYM = auto()
IDENT = auto() # 标识符
NUMBER = auto() # 数字
PLUS = auto() # 加号
MINUS = auto() # 减号
TIMES = auto() # 乘号
SLASH = auto() # 斜杠
ODD = auto() # 奇数
EQL = auto() # 等号
NEQ = auto() # 不等号
LSS = auto() # 小于号
LEQ = auto() # 小于等于号
GTR = auto() # 大于号
GEQ = auto() # 大于等于号
BECOMES = auto() # 赋值号
LPAREN = auto() # 左括号
RPAREN = auto() # 右括号
COMMA = auto() # 逗号
SEMICOLON = auto() # 分号
PERIOD = auto() # 句号
UNKNOWN = auto() # 未知标记
# 定义一个名为Token的类,用于表示一个标记。每个标记都有一个类型和一个值。
class Token:
def __init__(self, type, value):
self.type = type # 标记的类型
self.value = value # 标记的值
# 定义一个名为Lexer的类,用于执行词法分析。这个类有一个输入字符串和一个位置指针。
class Lexer:
def __init__(self, input_str):
self.input = input_str # 将输入字符串保存到self.input中
self.position = 0 # 初始化位置指针为0
def get_next_token(self):
self.skip_whitespace() # 跳过空白字符
if self.position >= len(self.input): # 如果当前位置超过输入字符串的长度
return Token(TokenType.PERIOD, ".") # 返回一个句号标记
current_char = self.input[self.position] # 获取当前位置的字符
if current_char.isalpha(): # 如果是字母
return self.get_identifier_or_keyword() # 获取标识符或关键字
if current_char.isdigit(): # 如果是数字
return self.get_number() # 获取数字
# 处理单字符标记
if current_char == '+':
self.advance()
return Token(TokenType.PLUS, "+")
elif current_char == '-':
self.advance()
return Token(TokenType.MINUS, "-")
elif current_char == '*':
self.advance()
return Token(TokenType.TIMES, "*")
elif current_char == '/':
self.advance()
return Token(TokenType.SLASH, "/")
elif current_char == '(':
self.advance()
return Token(TokenType.LPAREN, "(")
elif current_char == ')':
self.advance()
return Token(TokenType.RPAREN, ")")
elif current_char == ',':
self.advance()
return Token(TokenType.COMMA, ",")
elif current_char == ';':
self.advance()
return Token(TokenType.SEMICOLON, ";")
elif current_char == ':':
self.advance()
if self.position < len(self.input) and self.input[self.position] == '=': # 检查是否是赋值符号 :=
self.advance()
return Token(TokenType.BECOMES, ":=")
else:
return Token(TokenType.UNKNOWN, ":")
elif current_char == '=':
self.advance()
return Token(TokenType.EQL, "=")
elif current_char == '.':
self.advance()
return Token(TokenType.PERIOD, ".")
else:
self.advance()
return Token(TokenType.UNKNOWN, current_char) # 未知标记
def advance(self):
self.position += 1 # 前进一个字符
def skip_whitespace(self):
# 跳过空白字符
while self.position < len(self.input) and self.input[self.position].isspace():
self.advance()
def get_identifier_or_keyword(self):
identifier = ""
while self.position < len(self.input) and (
self.input[self.position].isalnum() or self.input[self.position] == '_'): # 继续读取字母、数字或下划线
identifier += self.input[self.position]
self.advance()
return Token(self.get_keyword_type(identifier), identifier) # 返回标识符或关键字
def get_number(self):
number = ""
while self.position < len(self.input) and self.input[self.position].isdigit(): # 读取数字
number += self.input[self.position]
self.advance()
return Token(TokenType.NUMBER, number) # 返回数字标记
def get_keyword_type(self, keyword):
# 将字符串转换为关键字类型
if keyword == "begin":
return TokenType.BEGINSYM
elif keyword == "call":
return TokenType.CALLSYM
elif keyword == "const":
return TokenType.CONSTSYM
elif keyword == "do":
return TokenType.DOSYM
elif keyword == "end":
return TokenType.ENDSYM
elif keyword == "if":
return TokenType.IFSYM
elif keyword == "odd":
return TokenType.ODDSYM
elif keyword == "procedure":
return TokenType.PROCEDURESYM
elif keyword == "read":
return TokenType.READSYM
elif keyword == "then":
return TokenType.THENSYM
elif keyword == "var":
return TokenType.VARSYM
elif keyword == "while":
return TokenType.WHILESYM
elif keyword == "write":
return TokenType.WRITESYM
else:
return TokenType.IDENT # 返回标识符类型
# 主程序入口
if __name__ == "__main__":
try:
line = input() # 读取第一行输入
if line == "end.": # 检查是否是结束符
pass
input_str = line + "\n" # 将输入字符串初始化为第一行
while True:
try:
line = input() # 继续读取输入
if line == "end.": # 检查是否是结束符
input_str += line
break
input_str += line + "\n"
except EOFError: # 处理EOF错误
break
except EOFError:
pass
lexer = Lexer(input_str) # 创建Lexer对象
tokens = [] # 初始化tokens列表
token = lexer.get_next_token() # 获取第一个标记
while token.type != TokenType.PERIOD: # 直到遇到句号标记
tokens.append(token)
token = lexer.get_next_token() # 获取下一个标记
tokens.append(token) # 添加最后一个句号标记
for token in tokens: # 输出所有标记
print(f"({token.type.name.lower()},{token.value})")
调试数据
测试样例一
[样例输入]
const a=10; var b,c; begin read(b); c:=a+b; write(c) end.【样例输出】
(constsym,const) (ident,a) (eql,=) (number,10) (semicolon,;) (varsym,var) (ident,b) (comma,,) (ident,c) (semicolon,;) (beginsym,begin) (readsym,read) (lparen,() (ident,b) (rparen,)) (semicolon,;) (ident,c) (becomes,:=) (ident,a) (plus,+) (ident,b) (semicolon,;) (writesym,write) (lparen,() (ident,c) (rparen,)) (endsym,end) (period,.)输出结果

测试样例二
[样例输入]
const a=10; var b,c,d; begin read(b); read(c); d:=a+b+c; write(d) end.【样例输出】
(constsym,const) (ident,a) (eql,=) (number,10) (semicolon,;) (varsym,var) (ident,b) (comma,,) (ident,c) (comma,,) (ident,d) (semicolon,;) (beginsym,begin) (readsym,read) (lparen,() (ident,b) (rparen,)) (semicolon,;) (readsym,read) (lparen,() (ident,c) (rparen,)) (semicolon,;) (ident,d) (becomes,:=) (ident,a) (plus,+) (ident,b) (plus,+) (ident,c) (semicolon,;) (writesym,write) (lparen,() (ident,d) (rparen,)) (endsym,end) (period,.)输出结果
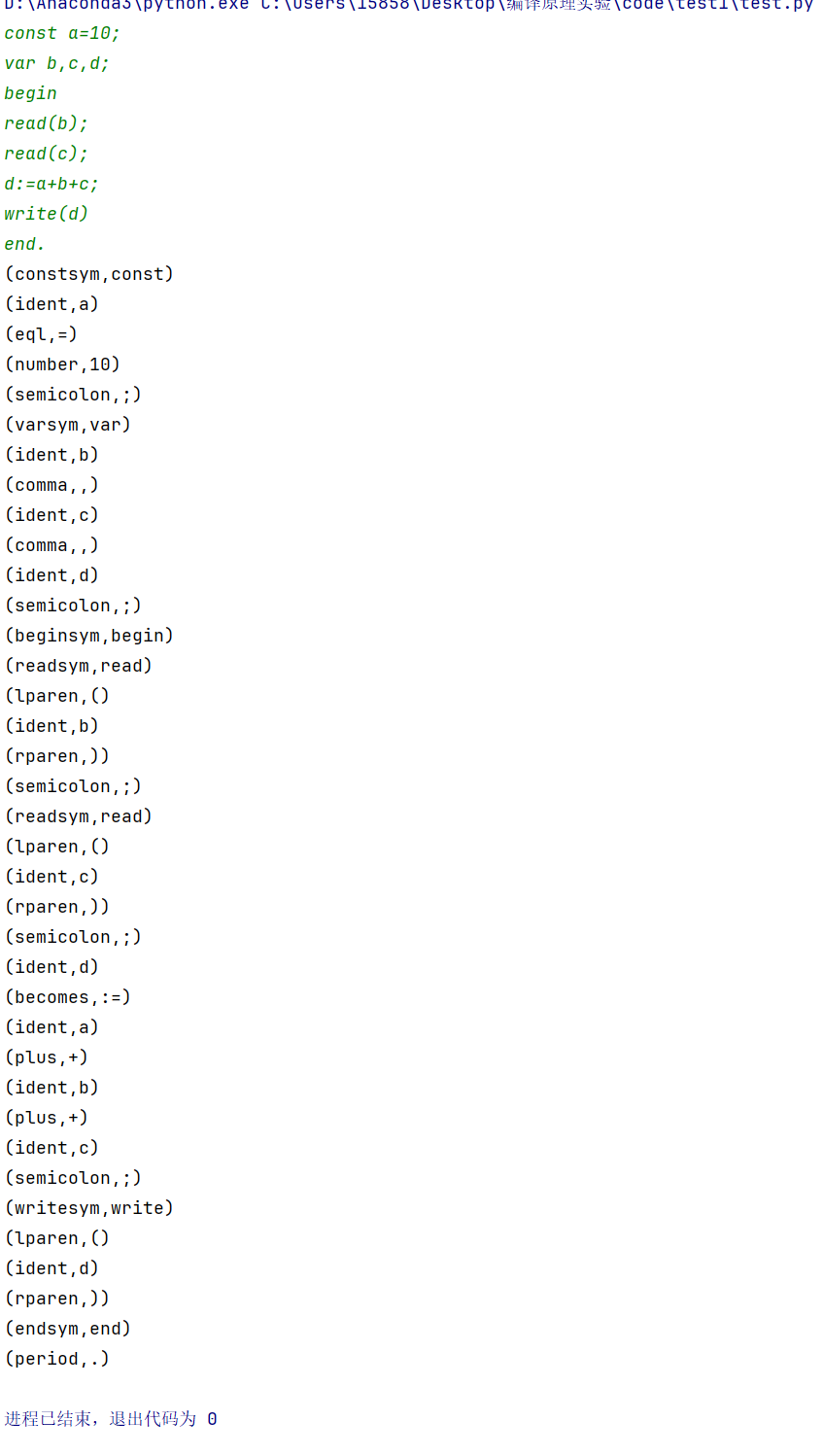
测试样例三
[样例输入]
const a=10; const b=10; var c; begin c:=a+b; write(c) end.【样例输出】
(constsym,const) (ident,a) (eql,=) (number,10) (semicolon,;) (constsym,const) (ident,b) (eql,=) (number,10) (semicolon,;) (varsym,var) (ident,c) (semicolon,;) (beginsym,begin) (ident,c) (becomes,:=) (ident,a) (plus,+) (ident,b) (semicolon,;) (writesym,write) (lparen,() (ident,c) (rparen,)) (endsym,end) (period,.)输出结果
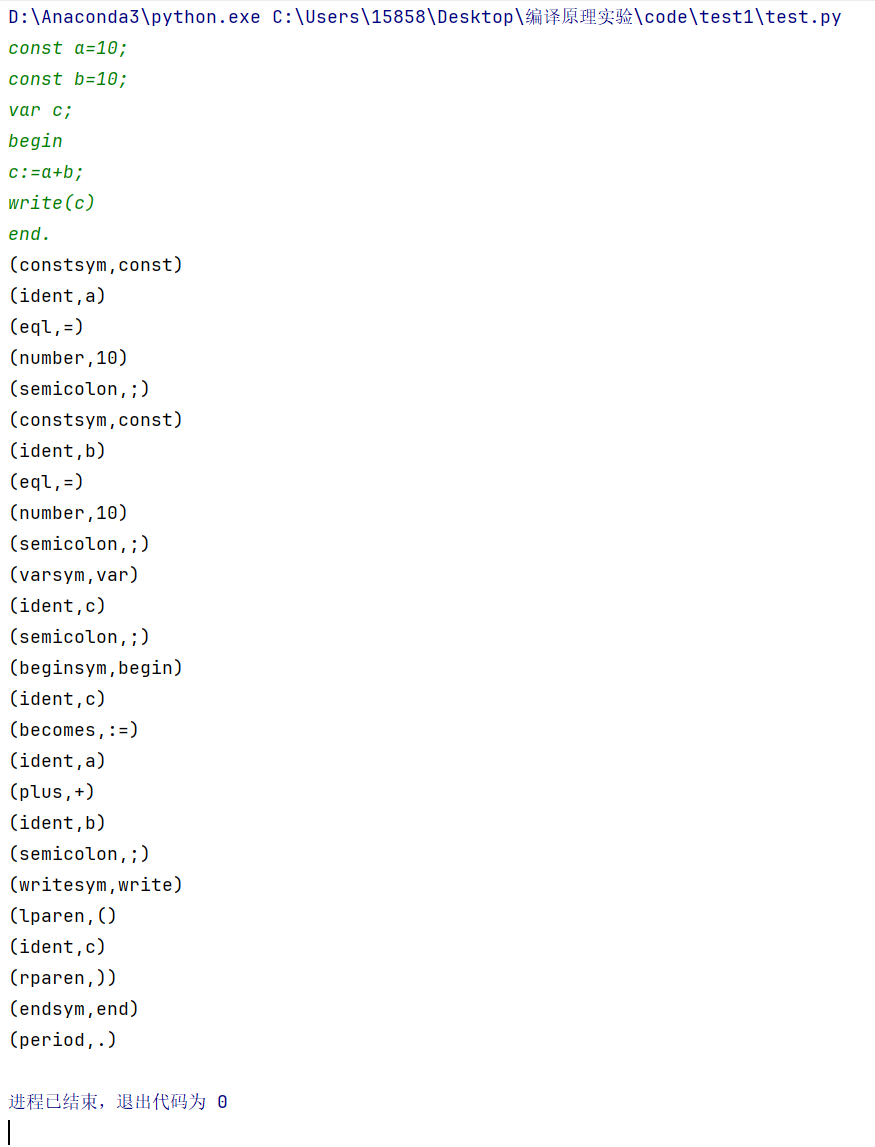
实验调试情况及体会
每做一次比较大的实验,都应该写一下实验体会,来加深自己对知识的认识。其实这次的实验,算法部分并不难,只要知道了DFA,这个模块很好写,比较麻烦的就是五种类型的字符个数越多程序就越长。但为了能识别大部分程序,我还是用了比较大的子集,结果花了一下午的功夫才写完,虽然很累吧,但看着这个词法分析器的处理能力,觉得还是值得的。同时也加深了对字符的认识。程序的可读性还算不错。程序没有实现的是对所有复合运算的分离,但原理是相同的,比如“+=“,只需在”+“的逻辑之后向前扫描就行了,因此就没有再加上了。感受最深的是学习编译原理必须要做实验,写程序,这样才会提高自己的动手能力,加深自己对难点的理解,对于以后的求first{},follow{},fisrtVT{},lastVT{}更是应该如此。