Retriever-and-Memory: Towards Adaptive Note-Enhanced Retrieval-Augmented Generation论文笔记
论文来源:师兄给的
问题:
不懂的知识
long-form QA / multi-hop QA / open QA
Multi-hop QA、Long-form QA 和 OpenQA 是问答系统中的三种不同类型,各自有不同的关注点和特点,但在实际应用中,它们可以彼此融合或互补。以下是它们之间的关系及对比:
-
OpenQA:
- 定义:OpenQA 是开放领域问答系统,旨在回答任何主题的自然语言问题,通常依赖于大型知识库或非结构化文本(如网页和维基百科)进行信息检索。
- 核心特点:在不限定领域的前提下,OpenQA系统能够从大量数据中搜索、抽取和生成答案。其主要挑战在于从庞大的数据源中找到准确、相关的信息。
- 任务目标:快速准确地回答广泛、开放的问题,通常是简短、事实性的回答,但也可以是较长的内容。
-
Multi-hop QA:
- 定义:Multi-hop QA 是一种专注于多步推理的问答任务,需要从多个信息片段中获取和连接线索来得到答案。
- 核心特点:在信息整合和推理链条构建方面具有挑战性,因为要在多个文本或逻辑链条之间进行连接。尽管信息可能在不同的文本片段中分散,但系统需要整合它们来形成最终答案。
- 任务目标:通过多个步骤的推理来回答问题,适用于需要多层逻辑或因果关系的问题,通常生成简短且确定的答案。
-
Long-form QA:
- 定义:Long-form QA 关注生成详细、解释性的回答,尤其适用于需要背景、分析或综合性回答的问题。
- 核心特点:强调生成连贯的长篇内容,回答需要深入的解释和背景信息,而不仅仅是单一的事实答案。系统需要具备较强的文本生成能力,以确保回答的内容丰富性和逻辑连贯性。
- 任务目标:提供深度的回答,回答内容类似一篇小文章,适合用户寻求综合性、解释性或教育性答案的场景。
三者的对比与关系
| 特点 | OpenQA | Multi-hop QA | Long-form QA |
|---|---|---|---|
| 目标 | 回答开放领域问题 | 通过多步推理找到准确答案 | 生成详细解释和背景的回答 |
| 关注点 | 信息检索与相关性 | 多步逻辑推理和信息整合 | 深度生成与连贯性 |
| 答案类型 | 简短或事实性答案 | 简短但需要多步推理的答案 | 连贯的长篇内容 |
| 关系 | 可结合 Multi-hop QA 或 Long-form QA 实现开放领域中的多步推理或长篇回答 | 可以在 OpenQA 系统中实现多步推理 | 可用于 OpenQA 系统中生成解释性答案 |
整合方式: 在复杂问答系统中,这三者可以结合使用。例如:
- OpenQA + Multi-hop QA:在开放领域中使用多步推理来找到答案,例如跨文档推理问题。
- OpenQA + Long-form QA:在开放领域中生成解释性或背景丰富的长篇回答,例如百科式回答。
总结:
- OpenQA 关注领域广泛的问题。
- Multi-hop QA 关注多步信息推理。
- Long-form QA 关注详细、解释性的回答。
LLM基本任务
| 任务 | 英文名称 | 简写 |
|---|---|---|
| 问答 | Question Answering | QA |
| 文本生成 | Text Generation | TG |
| 文本总结 | Text Summarization | TS |
| 语言翻译 | Machine Translation | MT |
| 文本分类 | Text Classification | TC |
| 实体识别 | Named Entity Recognition | NER |
| 文本改写与纠错 | Text Rewriting and Error Correction | TREC |
| 对话生成 | Dialogue Generation | DG |
| 代码生成和分析 | Code Generation and Analysis | CGA |
| 知识提取 | Knowledge Extraction | KE |
| 个性化推荐 | Personalized Recommendation | PR |
| 文本推理 | Textual Inference | TI |
摘要
除了QA任务还有哪些?
当前的RAG
RAG:检索增强生成(RAG)通过引入外部知识,缓解大型语言模型(LLMs)在开放域问答任务(OpenQA)中产生的事实错误和虚构输出问题。
现有的RAG方法使用LLMs来预测检索时机,所以RAG的现有问题:
- 直接使用检索到的信息进行生成而不考虑检索时机是否准确反映实际信息需求
- 也没有足够考虑先前检索到的知识
- 后果:这可能导致信息收集和交互不足,产生质量低下的答案。
解决办法
Adaptive Note-Enhance RAG(Adaptive-Note),用于复杂的QA任务
- 迭代信息收集器
- 自适应记忆审阅器
- 任务导向生成器
新的范式:Retriever-and-Memory
具体:
- 给出了一个总体的的方法观点来解决知识增长的问题
- 以note的形式迭代收集新信息
- 并将其更新到现有的最佳知识结构中,
- 目的:从而增强高质量的知识互动。
- 给出了一种基于注释的自适应停止探索策略,以决定“检索什么以及何时停止”,
- 目的:以鼓励充分的知识探索。
结果&实验
我们在五个复杂的QA数据集上进行了大量实验,结果表明我们的方法及其组件的优越性和有效性。
引言
RAG当前的问题
- LLM遇到幻觉和事实性错误,用RAG解决
- RAG:这是一种利用外部非参数化知识资源来帮助LLMs推动其固有参数知识边界的有前途的技术
- 当前的RAG范式:Retriever-and-Reader
- 当前RAG的缺点:无法收集足够的信息来完成long-form QA和 multi-hop QA 这些复杂的QA
- 原因:
- mutil-hop QA:通常涉及广泛或深入的信息检索需求,这些需求可能没有明确反映在初始查询中,或者在单次检索尝试中很容易实现。
- 例子:在多跳QA中,要回答“丹麦足球联盟所属组织的首字母缩写是什么?”,我们必须首先搜索首字母缩写“FIFA”,然后搜索“FIFA”代表什么。
- long-form QA :处理含糊查询需要探讨各个相关方面并深入细节,生成全面和长格式的答案。
当前的解决办法
ARAG:为了解决“何时检索以及检索什么内容”的问题,试图通过灵活的知识捕获机制来提升回答质量。
缺点:
- 逐步生成问题:每次检索都会立即生成一个输出,这会导致每个输出段仅反映当前检索到的有限知识,而忽略了跨不同检索步骤的信息整合和交互。
- 检索时机的预测偏差:ARAG利用LLM预测检索的时机,但由于LLM的内部认知与实际检索需求的差异,可能会错过关键的检索时机,导致知识收集不充分。
作者的解决办法
针对这种复杂的QA问题
提出了基于新范式Retriever-Memory的模型Adaptive Note-Enhance RAG(Adaptive-Note)
模型介绍
模型由两部分组成:Iterative Information Collector (IIC)、 Adaptive Memory Reviewer (AMR)
作用:自适应地从一个成长的视角收集信息,并灵活地将新知识与所有已收集的知识整合,实现良好的性能。
IIC模块
note 是哪种形式呢?
知识结构是如何被优化的?
IIC是怎么确保最大化调整与原始查询相关的所有细节?
新note是如何被加入原本note中的?
- 知识整合问题:为解决不同检索步骤间信息交互不足的问题,IIC引入了“笔记(note)”作为知识的存储载体,而不是在每次检索后立即生成结果。
- 最大化搜索:IIC不是在检索后立即生成结果,而是最大化调整与原始查询相关的所有细节,并将它们存储在笔记中。
- 动态更新:每当有新的检索信息,IIC会将其以文本形式适应性地添加到已有的笔记中,以保证知识结构的连续性和优化。(知识结构会被持续更新和优化,整合之前所有检索步骤中有效的信息,使得最终的知识结构更全面、更准确。)
总之,这段描述了IIC如何通过笔记存储和持续优化的方式,使得各检索步骤之间的信息能够有效整合,避免了因即时生成输出而导致的知识片面性。
AMR模块
疑问一:和主动检索有什么区别呢?
论文中的 note-based stop-exploration strategy(基于笔记的停止探索策略) 和 active retrieval(主动检索) 的区别在于知识收集的方式和控制检索过程的策略:
检索触发方式:
- Active Retrieval:模型在回答过程中动态地判断是否需要额外检索,依据的是当前回答生成的反馈或置信度来决定是否触发新的检索。
- Note-based Stop-Exploration:则是基于一个“笔记”作为知识的存储和整合载体。在检索过程中,所有获得的有用信息都会被存储到笔记中,并逐步整合和优化。当模型发现笔记中已有的知识结构已经足够完善时,就会触发停止条件,从而不再继续检索。
停止机制:
- Active Retrieval 关注的是在生成过程中的动态需求,检索可能是分阶段触发的,不一定有明确的停止点,因此容易受到时机偏差(timing bias)的影响。
- Note-based Stop-Exploration 使用一个“笔记”来不断积累和评估知识的完整性,只有在知识增长不足或达到特定条件时才停止检索。这种方法可以有效规避时机偏差,确保所有检索的知识都得到充分整合,停止条件更明确和系统化。
使用目的:
- Active Retrieval 更适合用于逐步生成答案时需要特定信息的情况。
- Note-based Stop-Exploration 则更适合在复杂问题中进行广泛信息整合和更新,以确保所有相关知识都完整且无冗余地存储在笔记中,用于提供高质量、全面的回答。
总结来说,active retrieval 是一种动态的、基于反馈的检索触发机制,而 note-based stop-exploration 是一种通过笔记积累和评估来确定停止检索的策略,更侧重于避免检索过度并确保知识整合的全面性。
疑问二:the timing bias of active retrieval predictions是什么意思?
模型在回答过程中会主动判断何时需要检索额外信息,但由于模型对检索需求的预测可能不准确,可能会导致以下两种情况:
- 过早或过晚检索:模型可能在不需要时启动检索,或在需要时却未能及时检索,导致检索结果的时机与实际信息需求不匹配。
- 知识缺失:错过关键检索时机会造成知识收集不充分,影响最终回答的质量。
用自适应基于note的停止搜索策略(note-base stop-exploration strategy)替换不确定的主动检索
具体:
- 它确定最佳笔记作为最佳记忆,并用它来决定“什么时候检索以及何时停止”
- 我们的自适应策略允许首先进行贪婪勘探。如果在特定时刻,笔记不再获得知识增益,则信息收集停止。
好处:这种策略有效地避免了主动检索预测的时机偏见,并确保持续的知识增益
实验&结果
零样本就可,无需少样本训练是怎么实现的?
实验
我们在五个复杂的QA数据集上进行了大量实验,涉及总体性能比较、定量消融研究和参数分析。结果突出了Adaptive-Note的优越性、有效性和普适性,同时确认了核心组件的有效性。
贡献
- 模型: 我们探索了LLMs处理复杂QA任务的能力,并首次提出了一种基于新范式(Retrieverand-Memory)的称为Adaptive-Note的方法。大量实验结果表明,Adaptive-Note在五个复杂QA数据集上显著超越现有方法,改进达到了8.8%。
- 策略: 我们引入了一种基于笔记的自适应知识探索策略,通过知识增长的视角加强。因此,Adaptive-Note可以持续收集相关知识并自适应地记忆最优知识,产生高质量答案。
- 设计实现: 我们将Adaptive-Note设计为一种通用且即插即用的方法,可以轻松适应任何现有的LLMs而无需额外训练,而且它可以在仅仅零样本设置下取得出色的性能,而无需使用精心设计的少样本示例。
相关工作
OpenQA
开放域问答(OpenQA)。开放域问答(OpenQA)(Voorhees 1999)旨在利用大规模和非结构化信息以自然语言形式回答与领域无关的问题(Zhu et al. 2021)。
现代开放QA任务的方法通常遵循Retriever和Reader范式(Chen et al. 2017; Das et al. 2019; Wang et al. 2024)。
Retriever
“Retriever”负责根据给定的问题检索相关文档,主流方法包括:
- 基于稀疏向量的检索,如TFIDF和BM25;
- 最近开发的基于密集向量的检索,如DPR(Karpukhin等人,2020)和Contriever(Izacard等人,2022)。
Reader
Reader致力于理解检索到的段落,然后推断出正确答案。
过去几年,Reader广泛采用了Fine-tuned预训练模型,建立在基于transformer的体系结构之上。
最近,LLMs涌现的能力-无需微调,基于提示的上下文学习(ICL)(Brown等人,2020)。这使得LLMs仅仅通过提供少量演示样本便能在OpenQA任务中取得极具竞争力的表现。
我们的工作主要集中在利用LLMs解决OpenQA任务,并提出了一种新颖有效的范式,即Retriever-and-Memory。
RAG
这段内容讨论了检索增强生成(RAG)技术的演变及其在复杂问答任务中的应用和挑战,并引入了自适应检索增强生成(ARAG)概念作为改进。具体解释如下:
- 传统RAG方法及其局限:
- 传统的RAG方法基于“检索器-阅读器”结构,检索器(Retriever)从外部知识库中检索到与问题相关的段落,然后将这些段落输入到语言模型(LLM)中生成答案。
- 早期的方法是单次检索(single-time RAG),即一次性检索所需的段落并直接生成答案。但在复杂的问答任务(如multi-hop QA和long-form QA)中,单次检索往往不足以获取完整的信息,导致回答内容不充分。
- 多次检索(multi-time RAG)方法的尝试和问题:
- 为了解决单次检索信息不足的问题,一些方法(如Trivedi et al. 2023;Borgeaud et al. 2022)在生成过程中尝试多次检索,即在生成答案时连续检索新的信息。
- 但是,多次检索可能导致模型不加区分地持续获取信息,这样如果某个检索步骤引入了错误或不相关的信息,会导致低质量的回答。
- 自适应RAG(ARAG)方法的提出:
- 为了解决上述问题,提出了自适应RAG(ARAG)方法。ARAG方法通过不同的反馈机制自动决定“何时检索、检索什么”,以更加精准地满足问题的知识需求。
- 目前主流的ARAG方法包括Flare(Jiang et al. 2023)和Self-RAG(Asai et al. 2024)。例如,Flare方法在生成过程中,如果检测到低置信度的词汇(即不确定的词),则会触发检索;但这种置信度判断可能无法完全反映实际检索需求。Self-RAG方法则通过自反性(self-reflective)的标记来判断是否需要检索及评估检索内容的质量,但这对LLM生成的自反性输出准确性要求较高。
- 本文提出的解决办法:
- 由于上述ARAG方法在时机判断上的局限性,作者的目标是从“知识增长”的角度建立一个更高效、稳定的自适应RAG框架,以更加合理地控制检索过程,提高回答质量。
方法
最佳记忆是什么意思?Mopt
AMR怎么触发的终止条件?
模型分为三部分:一个迭代信息收集器,一个自适应记忆审阅者和一个面向任务的生成器。
总体工作流程
初始化阶段
- 输入问题q,然后在IIC中进行检索,得到前k个段落p
- 然后k个段落输入到LLm中生成一个初始note$N_0$
- $N_0$作为初始记忆$M_0$,视为$M_{opt}$
迭代阶段
- 利用当前的$M_{opt}$和原始查询q生成第t步时的新查询$q_t$
- 然后检索新的相关文章$p_t^i \in P_t$ 然后作为现在当前的状态$N_t$
- 然后AMR 对$N_t$和$M_{opt}$进行多维度评估得到一个二进制结果
- 如果为true表示$N_t$应该替换记忆的内容
- 反之就不用
- 直到AMR触发迭代的终止条件。
最终阶段
使用面向任务的生成器,用$M_{opt}$作为上下文输入,通过LLM zero-shot 上下文学习(ICL)输出最终答案$a\in A$
模块1:IIC模块
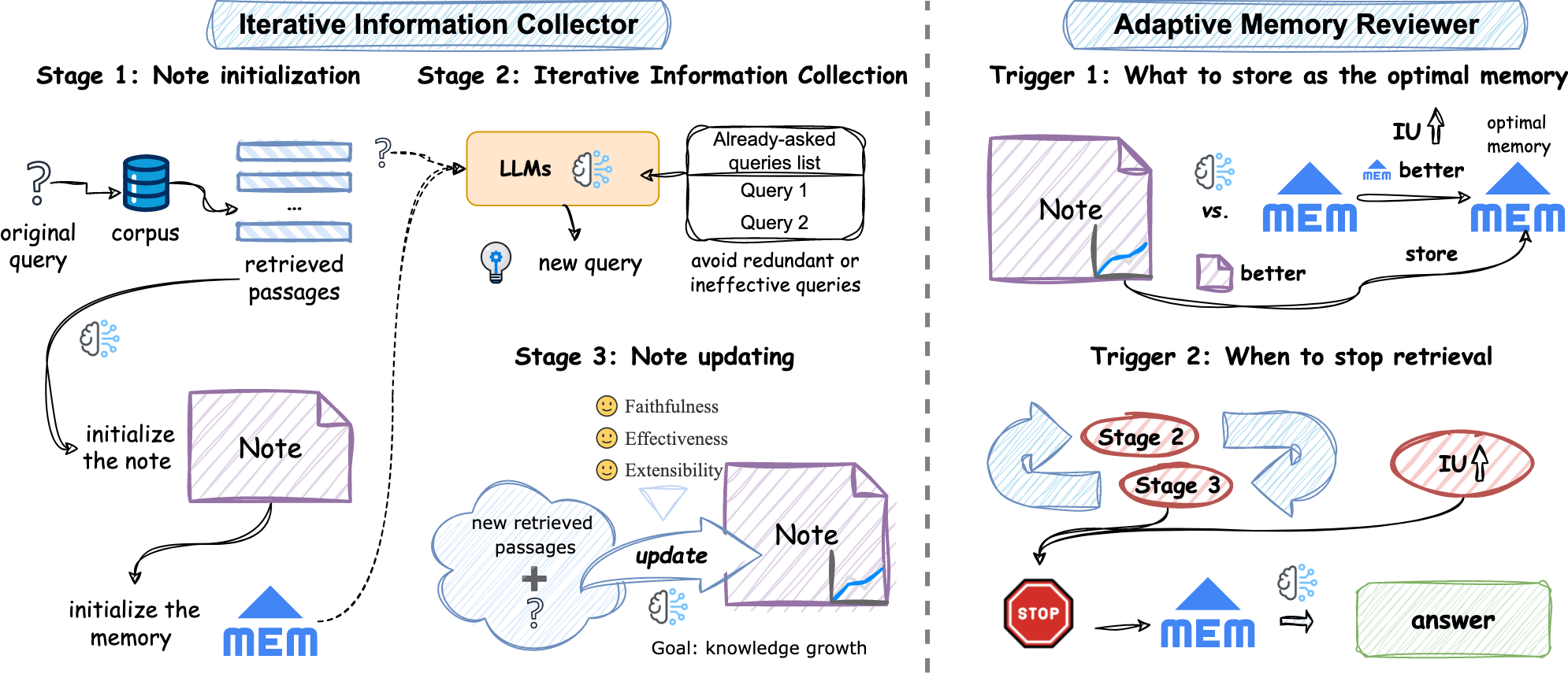
阶段一:Note初始化
-
将q作为输入给BM25得到k个文章 $P_0$
-
然后用LLM生成note $N_0$并且作为$M_0$直接赋给$M_{opt}$,将被用作后续迭代信息收集阶段的输入
(作者没有对笔记的具体格式或特定信息方面施加限制,并且使用的是zero-shot的LLM) \(N_{0}=\mathrm{LLM}(prompt_{init}(q,P_{0})) \\N_{0}=M_{0}\rightarrow M_{opt}\)
阶段二:迭代的信息检索
我们利用最佳记忆来预测下一个查询。
基于现有信息准确预测下一个高质量查询对有效探索语料库未知语义空间至关重要。
类似于人类行为,我们根据当前的最佳理解提出新问题。
这些promt都是什么?
怎么判断Nt相对于Mopt是否具有新的或额外的非冗余信息
输入:原始查询q,$M_{opt}$ 和已经问过的问题列表(防止重复问)
生成下一步的query \(q_{t}=\mathrm{LLM}(prompt_{q}(q,M_{opt},Q_{ask})),q_{t}\notin Q_{ask}\\Q_{ask}=\{q_{1},q_{2},\ldots,q_{t-1}\}\) $prompt_q$表示用于产生下一个检索的提示模板。已提问的查询列表$Q_{ask}$包含所有先前生成的查询。
阶段三:更新note阶段
目标:利用新的查询来探索语料库中潜在的与查询相关的语义子空间,并将新检索到的段落无缝地整合到现有知识中。
怎么设定prompt?
无固定模式:与笔记初始化阶段类似,在整合新知识时,不会预定义特定的模式(如简单地附加或插入信息),以避免限制大语言模型(LLM)的多样性和灵活性。这意味着新信息的整合过程是开放的,可以根据实际需求灵活调整。
信息增长的视角:该方法的核心在于如何有效促进信息的增长,而不是强制遵循固定的结构。这种灵活性允许模型在处理复杂信息时,能够收集、提炼和更新知识,而无需严格的格式限制。
流程
- 我们首先使用新查询$q_t$检索k个新段$P_t$。
- 接下来,我们将q、$Pt$和$M_{opt}$输入到LLM中,采用zero-shot上下文学习(ICL),最终生成更新的笔$N_t$。
$prompt_{update}(·)$表示用于更新笔记的提示模板,在三个关键方面为LLM提供多维指导:
- 忠实性。所收集的信息应符合检索文档的风格,尽可能地使用原始摘录;
- 有效性。所收集的信息应有助于解决原始查询;
- 可扩展性。所收集的信息不应已包含在内存中;换句话说,只需添加新的语义内容。我们还提供了信息增长的观点来描述这一更新过程,即基于现有的$M_{opt}$知识收集新信息,生成更新的$Nt$。
这里,$M_{opt}$是通过逐步更新得出的,逐渐比较和选择最高质量的笔记作为记忆,而不是依赖于一次性的比较。
模块2:AMR模块
自适应记忆审核者专注于两个关键问题:“$M_{opt}$是什么”和“何时停止检索”。
$M_{opt}$是什么样子的
我们指导LLM仔细审查在笔记更新阶段生成的更新笔记$N_t$的内容和最佳记忆$M_{opt}$的内容,然后比较它们的内容质量。
如果$N_t$的质量高于$M_{opt}$,则$N_t$将替换原始记忆内容成为最新的最佳记忆。
否则,$M_{opt}$的内容保持不变。 \(f_{c}(N_{t},M_{opt})=\begin{cases}\mathrm{True},&\mathrm{if~}N_{t}\mathrm{~is~better~than~}M_{opt}\\\mathrm{False},&\mathrm{if~}M_{opt}\mathrm{~is~better~than~}N_{t}\end{cases}\\ \\ N_{t}\to M_{opt}, \mathrm{if} f_{c}(N_{t},M_{opt})=\mathrm{True}\) 其中,$f_c(.)$ 表示内容质量比较函数,→ 表示“存储在”。
-
首先判断Nt相对于Mopt是否具有新的或额外的非冗余信息。
-
此外,为了进行多维度比较,我们在$f_c(.)$的prompt中使用zero-shot 设置制定质量比较的评价标准。
评价标准包括:
- 内容是否包含与问题直接相关的关键信息
- 内容是否具有多个方面
- 内容是否包含充分的细节
- 内容是否足够实用。
什么时候停?
我们建立了三个停止条件来自适应地控制笔记更新,从而间接控制信息收集。
三种停止条件:
条件 1:信息更新质量不佳
- 描述:如果更新后的笔记质量未能超过当前最佳记忆 $M_{\text{opt}} $的质量,则视为一次无效的信息收集。
- 无效更新计数(IU):设定一个无效更新计数阈值 $ T_{\text{IU}} $,即允许的最大无效信息收集轮数。如果无效更新次数达到此阈值,则停止迭代。
条件 2:信息收集步数过多
- 描述:某些查询可能涉及大量细节性信息(“长尾知识”),这些信息在多次迭代后会不断增加到笔记中。然而,这些细节可能对回答原始问题并无帮助。
- 收集迭代计数(CI):设定一个最大信息收集步数阈值 $ T_{\text{CI}} $,即允许的最大信息收集步骤数。如果迭代步数达到此阈值,则停止迭代。
条件 3:检索的段落数过多
- 描述:如果检索的段落数持续增加,但信息对回答原始问题没有显著帮助,也会导致信息冗余。
- 检索段落计数(RP):设定一个最大去重检索段落数阈值 $ T_{\text{RP}} $,即最多允许去重后的段落数。如果检索的段落数达到此阈值,则停止迭代。
停止机制:
- 这三个阈值($ T_{\text{IU}} $、$ T_{\text{CI}} $ 和 $ T_{\text{RP}} $)作为迭代停止条件。如果满足其中任一条件,即会触发终止机制,停止信息收集和更新过程。
- 停止符号⟨Stop⟩是一个布尔值,表示是否停止迭代过程。符号≥表示满足任何触发条件都会返回1。
模块3:面向任务的生成器
任务导向型生成器读取最佳内存$M_{opt}$,并输出原始查询q的答案α。
由于不同QA任务的输出风格(例如长或短的生成),我们将prompt定制为任务导向型。
\[\alpha=\mathrm{LLM}(prompt_{g}(q,M_{opt}))\]例如,多跳QA任务需要简短精确的输出,通常只有几个词,而我们内存中的知识则呈现为长文本。因此,我们指导LLM仅输出关键答案,不包括多余的词语。相比之下,对于长篇QA任务,我们指导响应风格而非严格的限制。
$prompt_g(·)$代表任务导向生成器的promt模板集合
实验
数据集和评估指标
-
Multi-hop QA任务:选择了三个具有挑战性的英语数据集进行评估,即 HotpotQA、2WikiMultiHopQA(2WikiMQA)和 MuSiQue。每个数据集使用了Trivedi等(2023)发布的一个包含500个随机选择样本的子集。评估指标包括F1分数(F1)和精确匹配(EM),用于衡量答案的准确性和完整性。
-
Long-form QA任务:选择了一个英语数据集ASQA和一个中文数据集CRUD。ASQA数据集使用ALCE(Gao等,2023)重新编译的948个查询,并使用其官方的评估指标,即字符串精确匹配(str-em)和字符串命中率(str-hit)。对于CRUD数据集,只使用其QA任务的数据集(包含单文档和多文档QA样本),并采用CRUD提出的RAGQuestEval评估指标,包括问题级别的召回率(Q-R)、标记级别的F1(T-F1)、召回率(T-R)和精确率(T-P)。
基线模型和LLMs
- 比较了三种基线模型:
- No Retrieval (NoR):直接将查询输入到LLM中生成答案,不进行任何检索过程。
- Single-time RAG (STRAG):一次性检索知识用于回答原始查询。
- Adaptive RAG (ARAG):采用自适应的前向探索策略,逐步检索知识以提升答案质量。
- 使用GPT-3.5作为NoR的内置LLM。对于STRAG,选择了Vanilla RAG、Chain-of-note、Self-refine和Self-rerank作为对比模型。ARAG中包含FLARE、Self-RAG和ReAct三种方法进行比较。具体实现方面,Self-RAG和ReAct使用了Langchain框架。此外,还进行了多种LLM的实验,包括GPT-3.5-turbo-0125、Qwen2-7b和Llama3-8b,默认情况下使用GPT-3.5作为模型。
检索器和语料库
- 为了确保所有基线模型之间的公平比较,在每个数据集中对检索器和语料库进行了统一设置。
- 对于所有Multi-hop数据集,使用BM25作为检索器(通过Elasticsearch实现),语料库为Trivedi等(2023)发布的数据集对应语料。
- 对于ASQA,使用密集检索器GTR-XXL,并使用ALCE提供的语料库(基于2018年12月20日的Wikipedia快照,分割为100词的段落)。
- 对于CRUD,使用了包含80000个中文新闻文档的语料库,遵循CRUD的检索配置(块大小为512,top-k为2)。除CRUD外,其他数据集的默认top-k为5。
提示的设置
- 实验方法在零-shot的设置下进行所有LLM推理。由于不同数据集需要不同的输出格式,因此为每个数据集设计了相应的提示(prompt)。为确保所有方法在同一数据集上的公平性,统一了生成时的提示。
- 对于三个具有相似输出格式的Multi-hop QA数据集,设计了相同的提示,引导LLM基于给定内容直接生成答案,减少不必要的词语。对于ASQA和CRUD,遵循作者提供的提示配置,去掉了ALCE的引用输出功能和CRUD的few-shot设置。
自适应过程的设置
- 在自适应过程中,为了在较低预算内达到最佳效果,将检索段落数量(RP)限制为15。默认情况下,收集器迭代计数(CI)和无效更新计数(IU)分别设置为3和1。
结果与分析
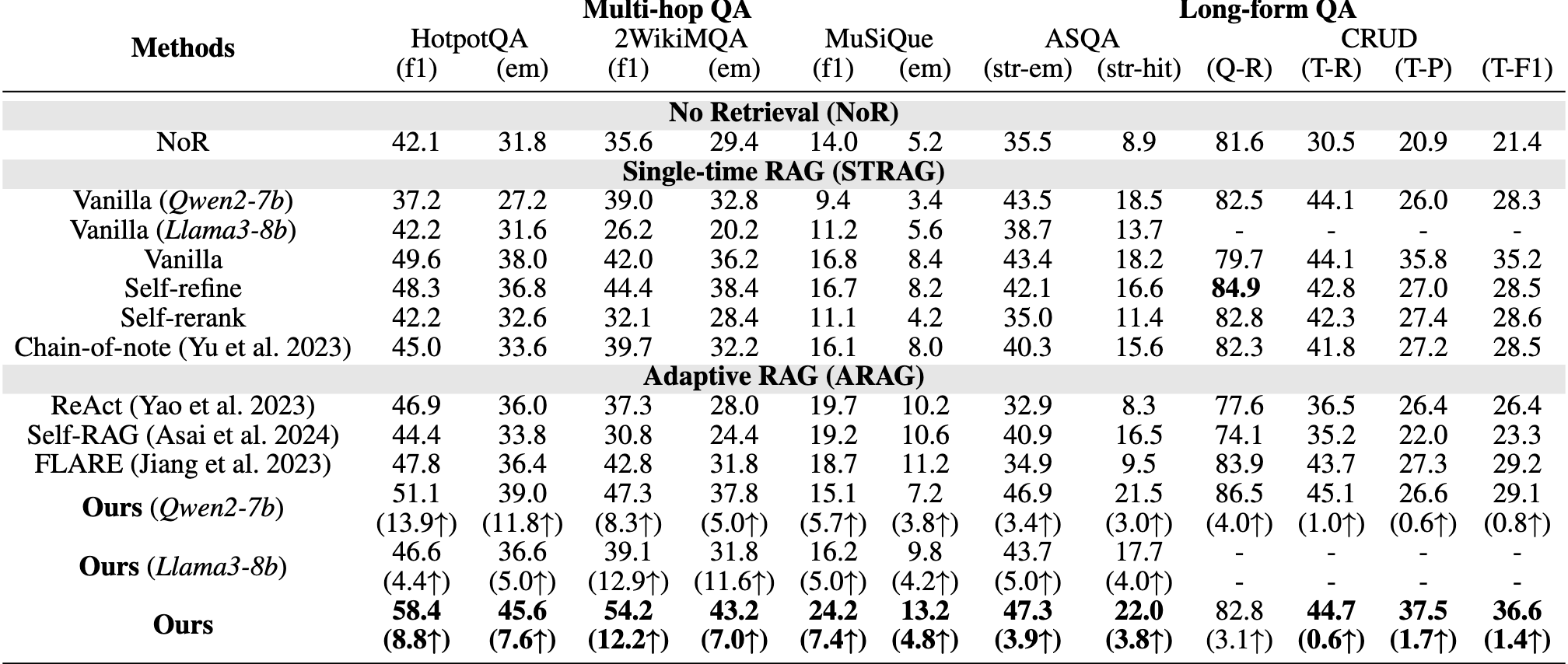
1. 主要结果
- 与单次检索RAG方法的比较:使用GPT-3.5作为所有方法的内置LLM,实验结果显示,所提出的方法显著优于单次检索方法。特别是在2WikiMQA数据集上,相比Vanilla RAG,性能提升达12.2%。这是因为单次检索方法依赖于单次检索的质量,而Adaptive-Note方法则可以在语料库中自适应地探索更多知识,提升答案质量。
- 与其他自适应RAG方法的比较:与FLARE、Self-RAG和ReAct等自适应RAG方法相比,Adaptive-Note在多跳QA和长篇QA任务上持续取得最高表现。这是因为Adaptive-Note方法采用了贪婪的信息收集策略,充分整合每个检索到的段落,避免了忽略关键知识的问题。
2. 不同LLM上的表现
- 为验证方法的通用性,作者在GPT-3.5、Qwen2-7b和Llama3-8b上进行了实验,结果表明Adaptive-Note在所有模型上均显著优于Vanilla RAG,验证了方法的鲁棒性和通用性。
3. 公平top-k下的深入比较
Vanilla RAG 在公平的 top-k 设置下的整体性能。
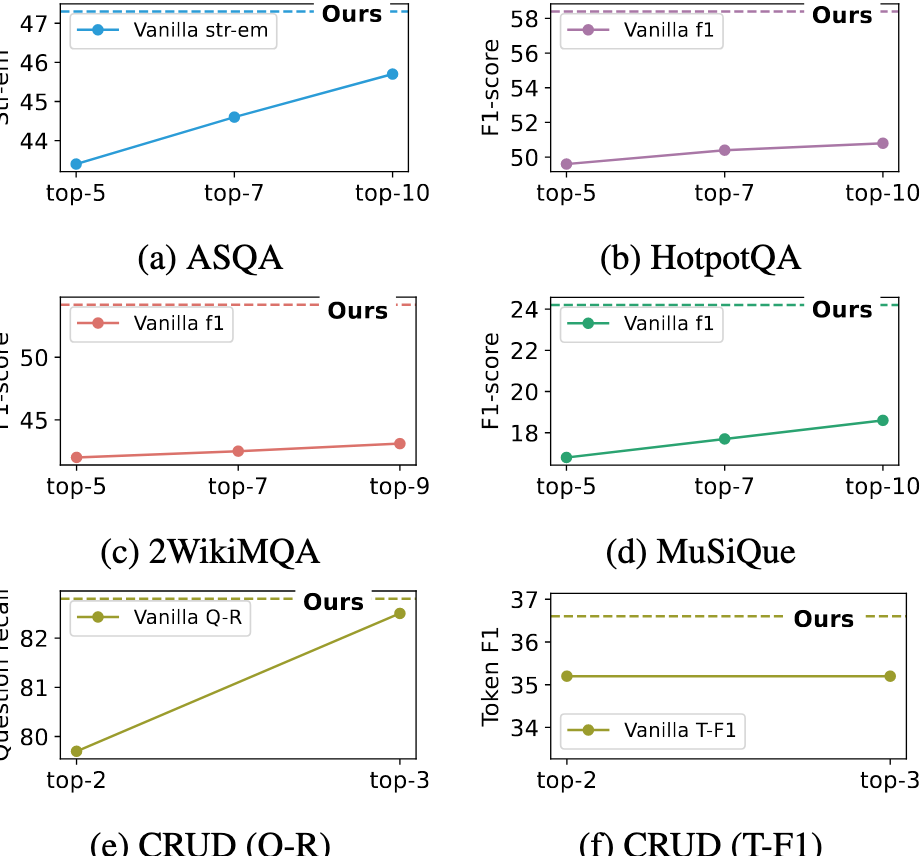
由于自适应RAG方法(如Adaptive-Note)在检索过程中会进行多次、动态的检索,可能最终获取的信息量比一次性检索的RAG(如Vanilla RAG)要多,直接比较两者的检索结果会存在不公平性。因此,为了进行公平比较,作者引入了“公平top-k”的概念。
- 为了在相同top-k设置下进行更公平的性能比较,作者计算了自适应检索步骤中去重后的平均检索段落数量作为“公平top-k”。结果显示,在所有数据集上,Adaptive-Note在公平top-k设置下的表现仍然优于Vanilla RAG。
4. 消融实验
- 迭代信息收集器(IIC)的有效性:实验表明,仅使用IIC模块就能提升性能,尤其在多跳QA任务中效果更明显,因为该模块能生成基于前序知识的新查询,有助于多跳推理。
- 自适应记忆审查器(AMR)的有效性:与不使用AMR模块相比,加入AMR可以进一步提高性能,因为AMR模块能够在高质量笔记生成后提前停止检索,减少不相关噪音。
5. 参数分析
- CI和IU的影响:在固定IU为1的情况下,CI增加时,多跳QA数据集的性能提升;对于长篇QA任务,CI=2已能达到最佳性能。
- top-k的影响:在不同top-k设置下,Adaptive-Note始终优于Vanilla RAG,验证了其在不同检索段落数量下的稳定性。
总结来说,Adaptive-Note在复杂QA任务中展现了显著的性能优势和良好的通用性,通过有效的信息收集和整合策略,提升了答案的准确性和覆盖度。