<ChatCoT>论文粗读
💡 Meta Data
| Title | ChatCoT: Tool-Augmented Chain-of-Thought Reasoning on Chat-based Large Language Models | | —————————————————————— | ———————————————————————————————————————————————————— | | Journal | (10.18653/v1/2023.findings-emnlp.985) | | Authors | Chen Zhipeng,Zhou Kun,Zhang Beichen,Gong Zheng,Zhao Xin,Wen Ji-Rong | | Pub.date | 2023 |
📜 研究背景 & 基础 & 目的 (Motivation)
现有的问题:
CoT的生成过程是一次性的,在中间步骤中使用工具将需要对其进行打断,从而损害生成过程的连续性
工具的调用会打断CoT的进程
-
现有的解决方法:
-
依赖LLM预先安排工具使用计划以供后序执行
- 缺点:生成计划后无法与工具交互,及时看到明显的错误也无法纠正,存在误差累积
-
设计针对特定任务的固定操作
- 缺点:必须频繁的在LLM推理和执行行动之间切换,损害了CoT之间的连贯性(就比如CoT下一步必须是调工具)
-
作者要寻找一种更统一的方法整合CoT和tool
🔬 研究方法
解决思路
-
将LLM的工具的操作视为LLM与工具之间的交互。
-
将LLM和工具之间的交互过程建模为多轮对话,利用LLM出色的对话能力来操作工具
- 在每一轮中,LLM可以在需要时自由地与工具交互,否则自行进行推理
- 对话持续进行直到LLM得出最终答案。
-
针对问题:在此过程中,由于基于对话的LLM可以很好地理解多轮上下文,它们可以在整个对话中遵循思维链,并自然地相应地调用工具,从而保持推理过程的连续性。
所以作者提出了ChatCoT,一种用于基于聊天的LLM的工具增强型思维推理策略。
初始设定
任务定义
专注于提升LLM在复杂任务上的推理能力(解决数学竞赛问题)
任务描述:
- 问题陈述:复杂问题的背景和描述
- 解答文本:获得答案单独详细解决过程
- 答案
任务目的:给定问题陈述最终生成准确答案
工具集
-
计算器:给定数据表达式可以化简
- 实现:用SymPy python库
-
方程求解器:给定方程组和未知变量,可以求解
- 实现:用SymPy python库
-
检索器:给查询提取相关信息
- 用SimCSE
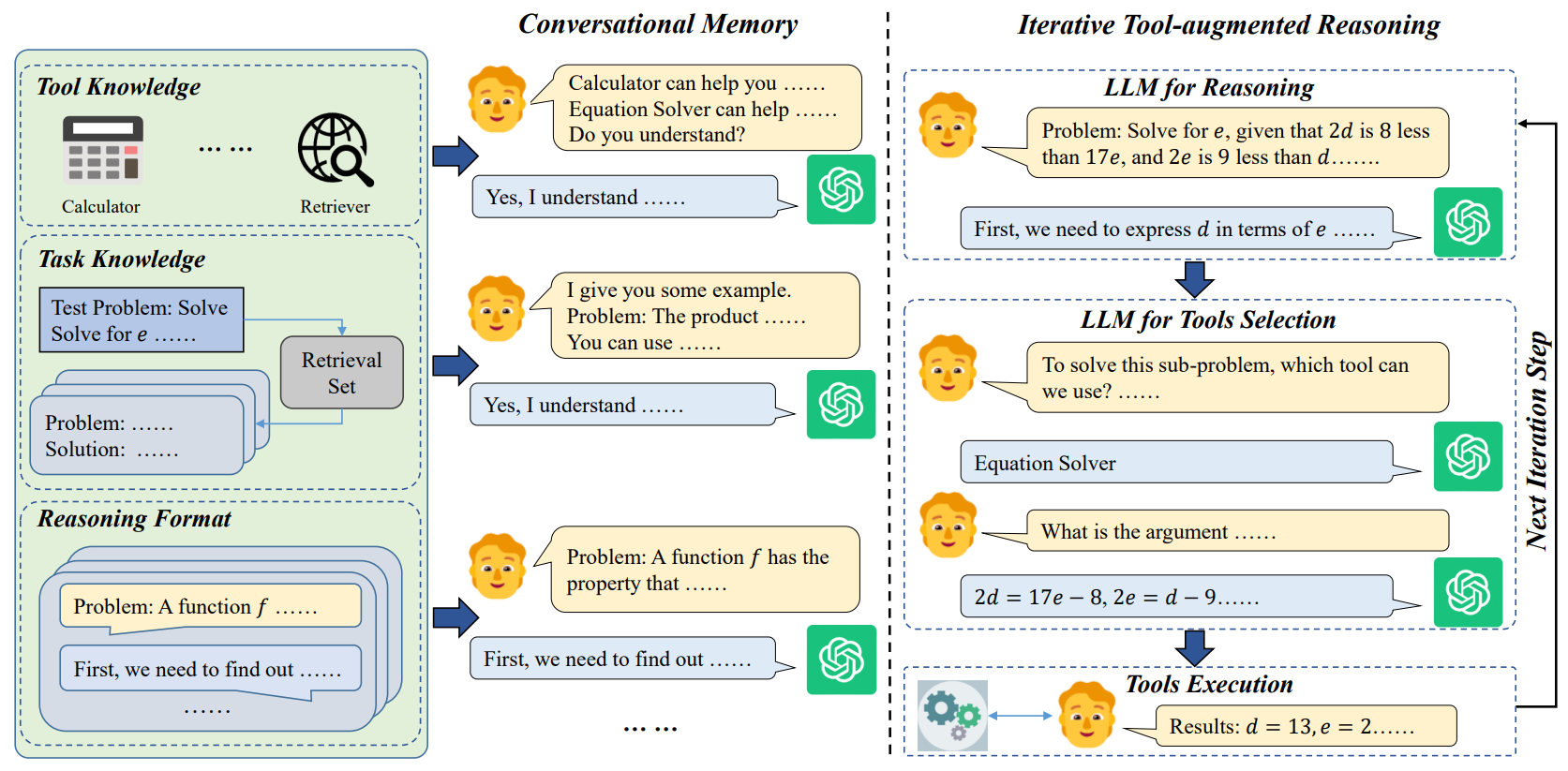
具体方法
工具学习的训练方法:In-context learning
通过agent(预定义的规则)与LLM的对话来实现推理和工具调用
整体分两个阶段:
-
给LLM输入关于工具、任务和推理格式的知识来初始化对话的早期轮次(对话形式)
-
迭代一个专门设计的工具增强型推理步骤(对话),直到获得答案
- 在每次迭代中,基于当前的结果,我们首先利用大型语言模型进行推理,然后通过大型语言模型选择合适的工具,最后执行所选工具以获得当前步骤的中间结果。
- 推理:LLM根据示例可以将推理分解为多轮对话,而无需专门的提示或指令。直到需要工具功能才停止
- 工具选择:通过prompt提示让LLM选择(问LLM用什么工具如果回复不使用工具就继续推理)
- 工具执行:给定选定的工具和参数,然后执行,可能结果无法让LLM满意,我们也可以增加几轮反馈,让LLM判断结果是否有用,然后重新使用该工具获取新结果
🚩 结论
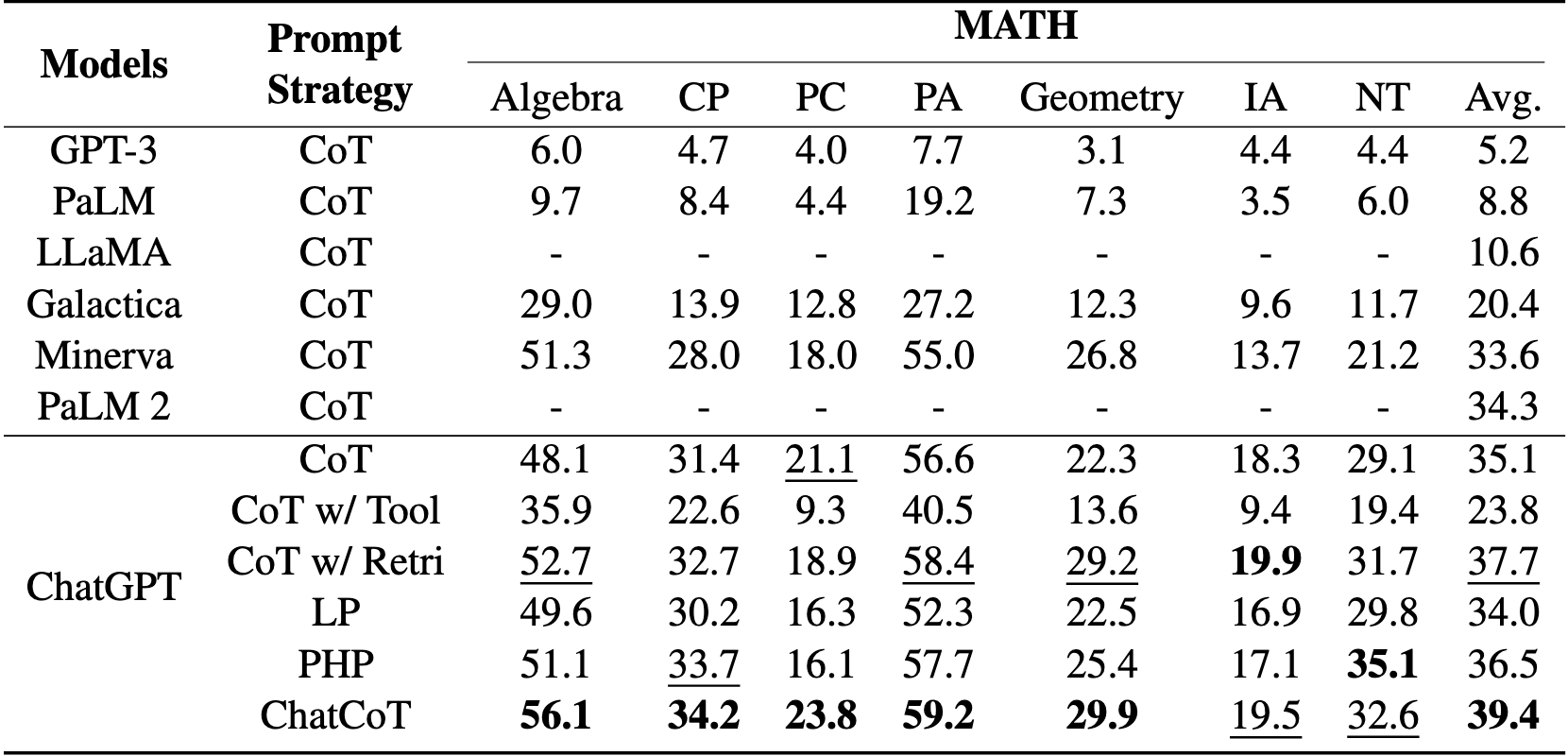
在两个复杂的推理基准数据集上进行了实验,即MATH 和HotpotQA 。
ChatCoT在MATH上取得了非常有希望的性能,与SOTA基线方法相比,平均性能相对提高了7.9%。

📌 感想 & 疑问
- 整体的prompt流程具体是什么样子?
- agent是如何搞的
- 为什么比其他的CoT+Tool好呢?
- 读一下其他CoT+Tool