<StructGPT>论文粗读
💡 Meta Data
| Title | StructGPT: A General Framework for Large Language Model to Reason over Structured Data | | —————————————————————— | ——————————————————————————————————————————————————– | | Journal | (10.18653/v1/2023.emnlp-main.574) | | Authors | Jiang Jinhao,Zhou Kun,Dong Zican,Ye Keming,Zhao Xin,Wen Ji-Rong | | Pub.date | 2023 |
📜 研究背景 & 基础 & 目的 (Motivation)
-
目的:以统一的方式提升大型语言模型 (LLMs) 在结构化数据上的推理能力
-
motivation:当前LLM在引入外部知识的时候,通常使用有结构的数据库,而数据库存放的数据通常是结构的,而LLM无法完全理解
-
直接解决方法:直接线性化(直接拼接成一长串句子)
- 缺点:但是数据量很大的时候,不可能全部都直接假如到prompt中。
-
🔬 研究方法
问题描述
使用LLM解决基于结构化数据的复杂推理任务
输入: 自然语言问题、结构化数据(知识图谱、表格、数据库)
输出: 结果(自然语言或结构化表达式)
解决思路
-
引入专门的APi操作结构化的数据记录
- 如何为特定任务设计合适的接口
- 如何利用这些接口让LLMs进行推理
提出了 Iterative Reading and Reasoning 框架解决结构化数据的问答任务——Struct GPT
Iterative Reading and Reasoning 框架
- reading 读取:构建了专门的机构从结构化数据收集相关证据
- reasoning 推理:让LLM专注于收集到的信息的推理任务
具体过程:invoking-> linearzation -> generation
struct API定义
因为用LLM来结构化数据不好,所以作者自己设计了API而不是使用LLM
-
知识图谱:
- Extraction_Neighbor_Relations(e)
- Extract_Triples(e,{r})
-
表格:
- Extract_Columns(T,{c})
- ……
-
数据库
- Extract_Table\&Column_Name (D)
- ……
Invoking
调用接口从结构化数据中提取相关信息,送到LLM中
Information Linearization
根据提取的信息,将其转换为可被大型语言模型理解的文本句子
每个结构定义一种线性化规则
来自知识图谱的信息:将其连接成一个长句子,并用特定的分隔符和边界符号标记。
对于表格:
例如“(第1行,年份,1896)”和“(第1行,城市,雅典)”。然后,对于每一行,我们将行索引提取到句首,并在三元组中省略行索引,以组成简化的句子,例如“第1行:(年份,1896),(城市,雅典)”。对于多行数据,我们通过特殊的分隔符将它们连接成一个长句子。
LLM for Generation
有两种prompt:
- 筛选数据:从线性的数据中根据问题筛选有用的数据
- 给出答案:生成最终答案(可以是自然语言也可以是形式化语言(SQL))
举例解释流程
以知识图谱为例:
- 根据问题 query 中提到的实体 搜索调用接口Extract_Neighbor_Relation、Extract_Triples
- 然后线性化
- 利用LLM根据问题选择有用的关系
- 调用Extract_Triples收集头实体 eT 和 {r} 中关系的相关三元组
- 然后线性化此信息
- LLM应评估当前信息是否足以回答问题,然后,LLM将根据评估结果采取相应操作(停止或迭代)
- 使用大型语言模型选择最相关的三元组,其尾实体将被视为最终答案
🚩 结论
在8个数据集上的实验结果表明,我们的方法可以有效提升LLMs在零样本和少样本设置下对结构化数据的推理性能,甚至可以与具有竞争力的全数据监督微调方法相媲美。
在KGQA、TableQA和text-to-SQL任务中,与在零样本设置下直接使用ChatGPT相比,我们的方法在WebQSP上实现了11.4%的Hits\@1提升,在TabFact上实现了4.2%的准确率提升,在Spider上实现了4.7%的执行准确率提升。
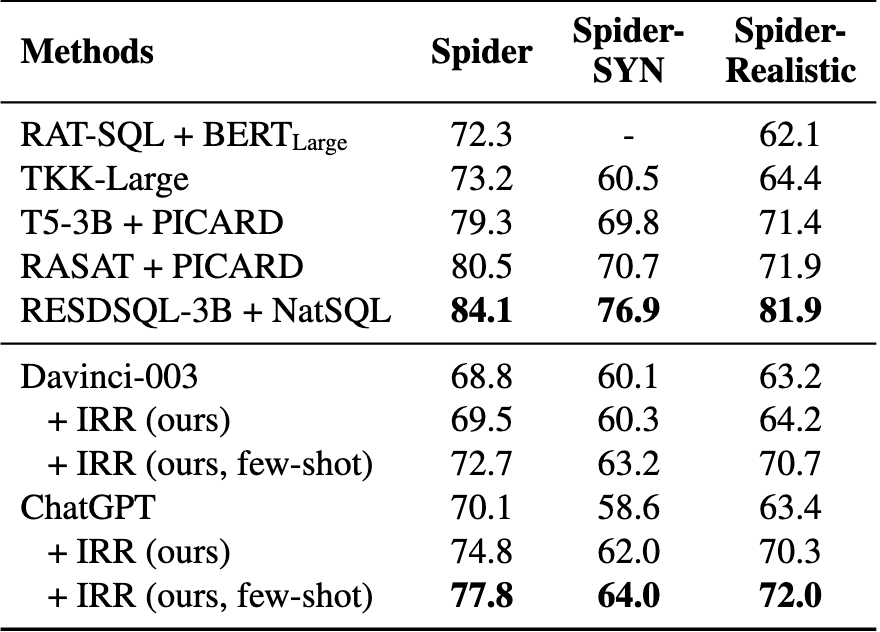
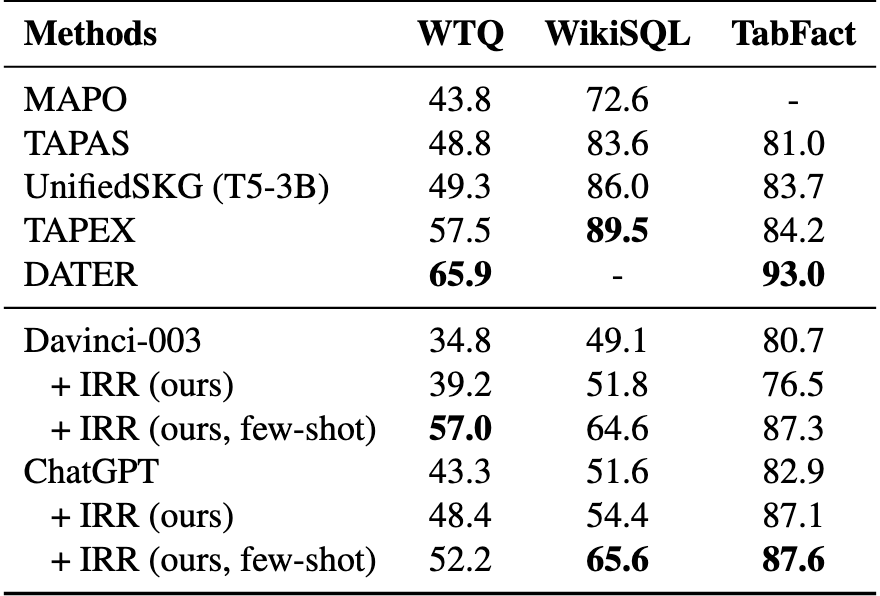
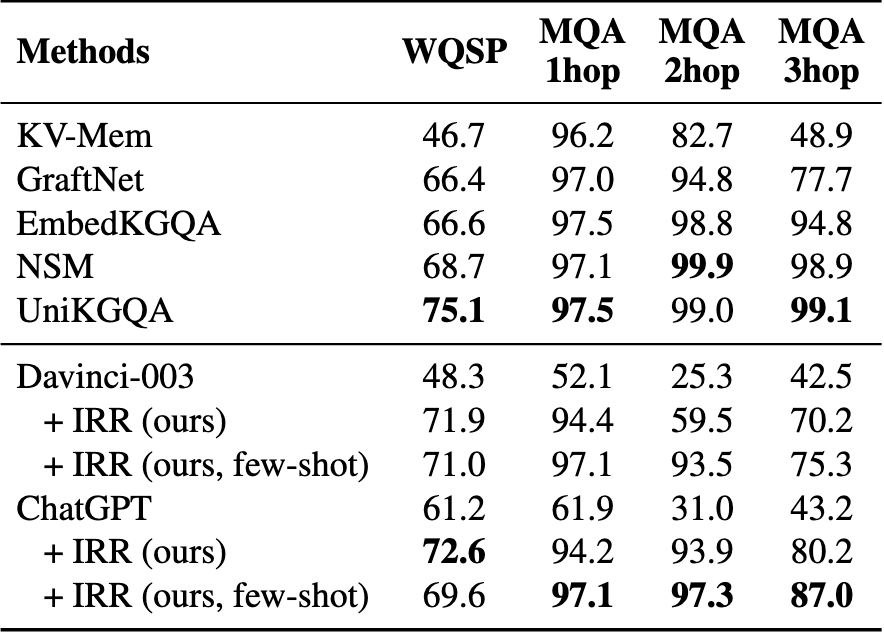
错误:
- 选择错误:相关信息不是LLM选的
- 推理错误:有相关信息但是LLM推理错误
- 生成答案格式错误:无法被结果解析识别(数据集不同很难控制生成对应的格式)
- 幻觉问题
📌 感想 & 疑问
- 是什么情况下few-shot比zero-shot更差的?
- 这种固定的pipeline可能无法让LLM选择自己要的数据
- 这种自己定义数据的线性化,是不是太死板了,他说用LLM结构化不太好,但是后面有人做了,是可以的。
- 总体来说并不算是真正的工具学习,因为不是 LLM 自主调用的,而是固定的步骤。