<Self-Planning Code Generation with Large Language Models> 论文粗读
💡 Meta Data
| Title | Self-Planning Code Generation with Large Language Models | | —————————————————————— | ———————————————————————————————————————————————————————————————— | | Journal | ACM Transactions on Software Engineering and Methodology (10.1145/3672456) | | Authors | Jiang Xue,Dong Yihong,Wang Lecheng,Fang Zheng,Shang Qiwei,Li Ge,Jin Zhi,Jiao Wenpin | | Pub.date | 2023-06-30 |
📜 研究背景 & 基础 & 目的 (Motivation)
问题:
-
LLM代码生成无法应对有复杂意图的任务
- 解决方法:需要采用规划来分解复杂问题,并在实施之前安排解决方案步骤
-
生成CoT的过程和生成代码的过程本质是相似的,直接将CoT应用于代码并不能减少难度
- 解决方法:要专注实现问题的分解
🔬 研究方法
思路:将规划引入到了代码生成中,以帮助模型理解复杂意图并降低问题解决难度
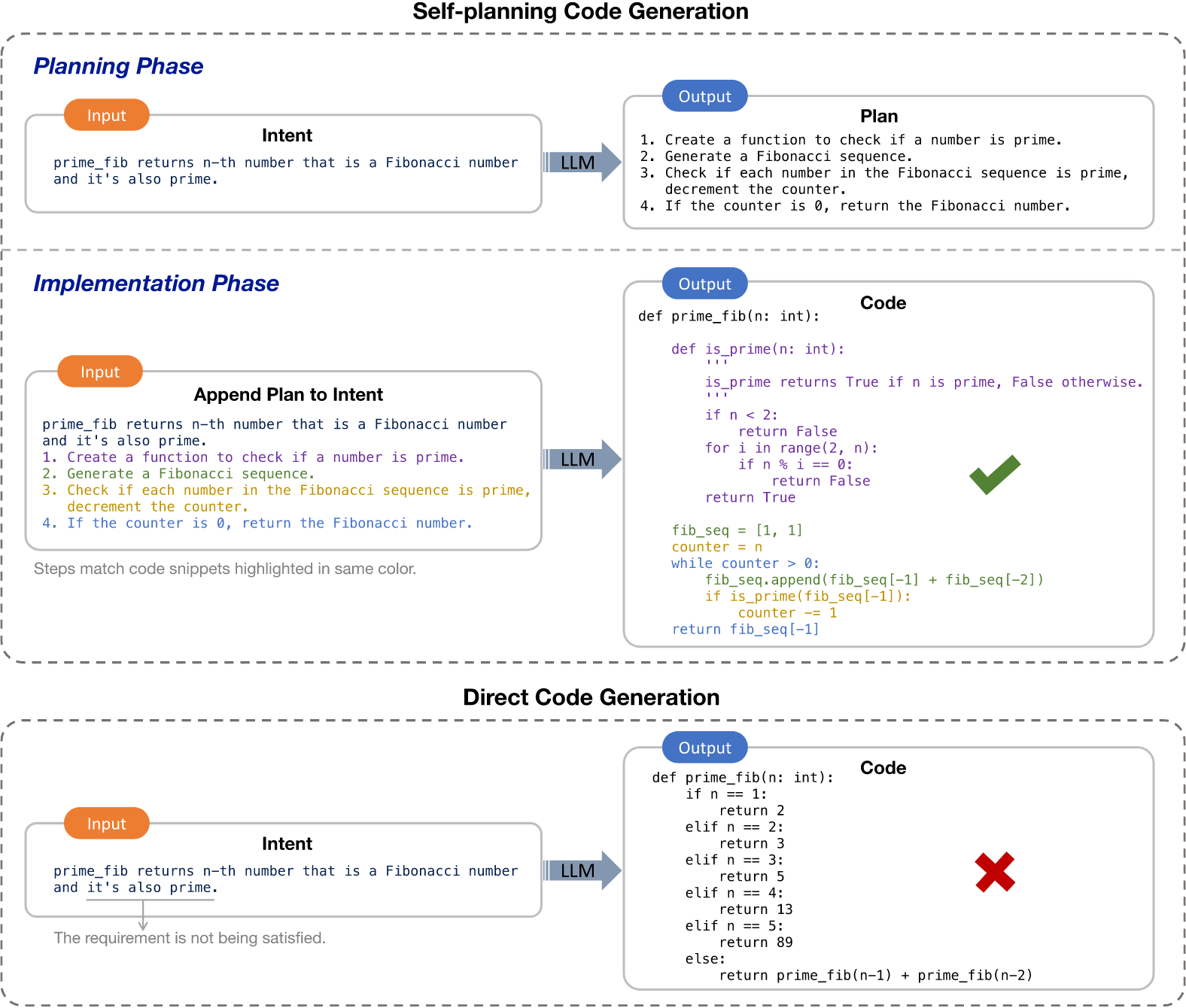
具体方法:
- 规划阶段:大型语言模型通过结合少量示例提示(包含细粒度的规划过程),从意图中规划出简洁的解决方案步骤
- 实现阶段:模型在前面解决方案步骤的指导下(把计划加入prompt中),逐步生成代码
训练方法:少样本实现规划能力,而不是标记数据(记意图-计划对),无需微调。
🚩 结论
-
性能提升:自规划代码生成在Pass\@1指标上实现了高达25.4%的相对提升,与思维链代码生成相比则实现了高达11.9%的提升
-
根据人类评估,正确性、可读性和稳健性提升了代码质量
-
规划能力:我们表明,自我规划是一种出现在足够大的大型语言模型上的涌现能力,但规划可以使大多数大型语言模型受益。
-
最优:我们深入探讨了自我规划方法的几种变体,并证明我们设计的自我规划方法是这些变体中的最佳选择。
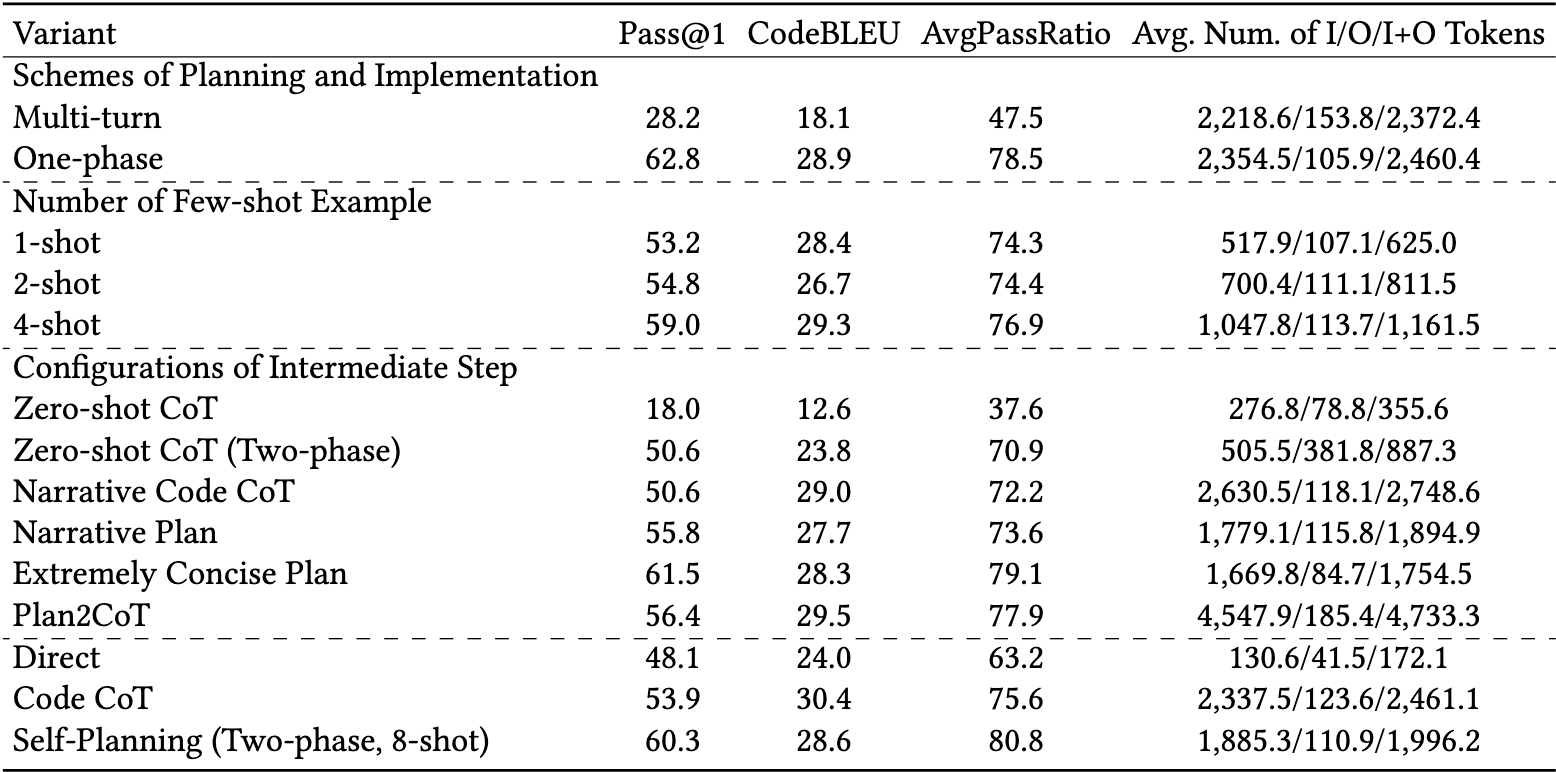
-
泛化:我们验证了自我规划方法在多种编程语言(包括Python、Java、Go和JavaScript)上的有效性。
📌 感想 & 疑问
-
为什么多轮的效果不如单轮的
- 由于大型语言模型在大量的拼接文本和代码上进行训练以预测下一个标记,因此大型语言模型可能存在截断问题,即它们无法精确控制其输出的终止。当使用计划来生成部分函数(通常是若干语句)时,很难定义截断规则。