<Toolformer> 论文粗读
💡 Meta Data
| Title | Toolformer: Language Models Can Teach Themselves to Use Tools | | —————————————————————— | ——————————————————————————————————————————————————————————— | | Journal | (10.48550/ARXIV.2302.04761) | | Authors | Schick Timo,Dwivedi-Yu Jane,Dessì Roberto,Raileanu Roberta,Lomeli Maria,Zettlemoyer Luke,Cancedda Nicola,Scialom Thomas | | Pub.date | 2023 |
📜 研究背景 & 基础 & 目的 (Motivation)
-
LLM的对于一些任务上有卓越的能力,但是基本功能方面却存在困难,例如算数或事实查找。
- 这些领域是小模型的强项
-
当前的研究:要么依赖大量的人类标注数据、要么仅限于特定任务的工具使用,阻碍了工具在语言模型中的广泛采用。
🔬 研究方法
思路
-
让LLM通过简单的API自我学习使用外部工具。
-
提出了Toolformer,实现以下愿望:
-
自监督学习工具,不用人类标注数据
-
原因:
- 人类标注成本高
- 人类觉得有用的不一定是LLM觉得有用的
-
-
LM 不能失去其泛化能力,不局限于特定任务
-
方法
利用In-context learning,从零开始生成数据集
- 首先仅通过少量人类编写的API使用示例,让语言模型为一个庞大的语言建模数据集标注潜在的API调用
- 然后使用自监督损失(self-supervised loss)来确定哪些API调用实际上有助于模型预测未来的token
- 最后微调模型
具体:
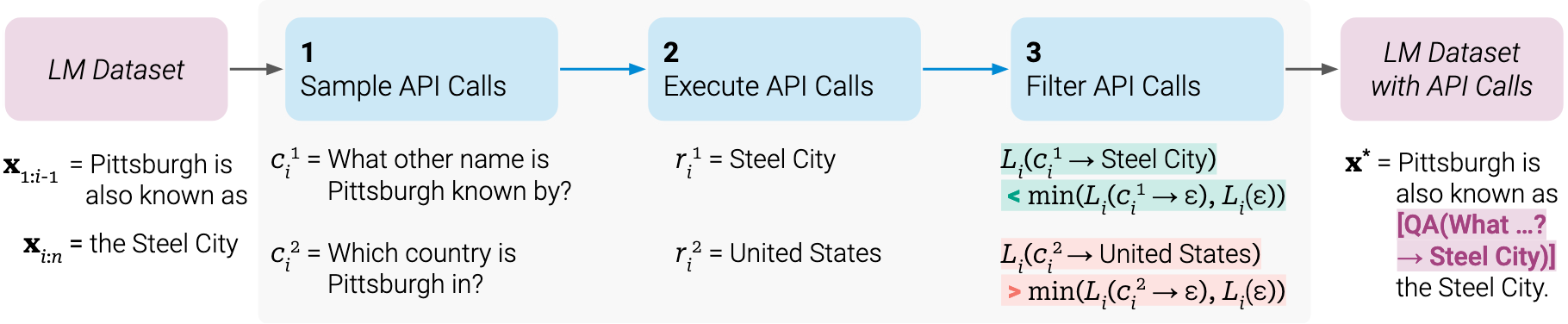
-
给定一个普通文本的数据集,然后转化成带有API调用的数据集
-
编写prompt,利用In-context-learning 采样大量潜在的API调用(生成多个API调用)
- 先找到序列中哪个位置调用API(设定一个阈值,如果生成<API>概率大于阈值则保留该位置)
- 然后选定API:选定位置后,继续生成,然后进行采样多个API候补
-
然后执行API调用(每个API的返回是文本序列)
-
-
然后检查获得的相应是否有助于未来的token,来筛选
- 具体就是比较加入API调用后,生成后序序列的概率和不加API调用的概率哪个大(要大过设定的阈值),如果加入API后大超过阈值那就是有帮助,则保留
-
经过筛选得到了增强的数据集,然后进行微调
生成过程中如果生成到了spacial token了就中断生成过程,获得API响应后,插入响应和</API> token后继续解码过程
🚩 结论
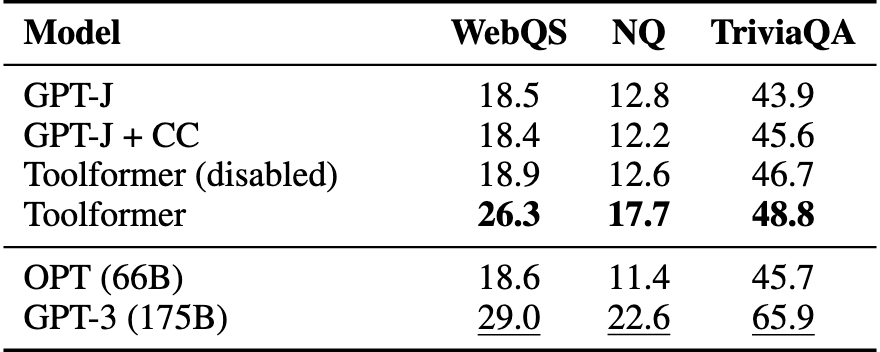
- Toolformer 显著提高了zero-shot性能
- 语言建模能力也没有牺牲
📌 感想 & 疑问
缺点:
- 无法与搜索引擎交互,只能用他给出的结果,无法重构查询等,然后就没有修补办法。
收获:
- 微调以后再禁用API测试,确实是一个检测微调后有没有损失模型性能的好办法
- 微调过程中仅对工具选择算loss感觉挺有用 *