Towards Autonomous Tool Utilization论文粗读
💡 Meta Data
| Title | Towards Autonomous Tool Utilization in Language Models: A Unified, Efficient and Scalable Framework | | —————————————————————— | ————————————————————————————————————————————————————- | | Journal | (LREC-COLING) | | Authors | Li Zhi,Li Yicheng,Ye Hequan,Zhang Yin | | Pub.date | |
📜 研究背景 & 基础 & 目的 (Motivation)
-
为了实现完全自主的工具使用问题:
- 仅凭一个查询语言模型能够自主决定是否使用工具,选择那个特定的工具,以及如何使用这些工具,
- 并且所有这一切都不需要在上下文中提供任何特定工具的提示
-
研究现状
-
ToolLLM选择工具需要额外的检索步骤
-
缺点:
- 会导致累积错误,
- 缺乏端到端的优化
-
-
在上下文中提供与特定场景相关的多种工具
- 缺点:有限的上下文使得拓展工具变得困难
-
Toolformer 和 TRICE 关注的问题与本文类似
- 缺点:采用自监督数据集构建效率低下,考察工具类型有限
- 缺乏对可扩展性的讨论和分析
-
🔬 研究方法
思路:期望大模型能够通过充分的内化各种的工具知识,实现完全自主的工具使用。
为了实现这个目标:引入了一种统一、高效且可扩展的语言模型微调框架
-
根据工具依赖程度,将初始query分为三种不同类型
-
可直接解决的问题
-
需要验证的问题
- LLM 一定程度上能解决但是容易产生幻觉(复杂的数学计算)
-
由于固有限制而无法解决的问题(实时查询)
-
最后通过将统一建模为序列决策问题来解决
- $\begin{aligned}P(\mathrm{Y,W_e,W_i,H\mid X})&=P(\mathrm{W_{e}}\mid\mathrm{X})&\times P(\mathrm{W_{i}\mid W_{e},X})&\times P(\mathrm{H}\mid\mathrm{W_{e}},\mathrm{W_{i}},\mathrm{X})&\times P(\mathrm{Y}\mid\mathrm{H},\mathrm{W}\mathrm{e},\mathrm{W}\mathrm{i},\mathrm{X})\end{aligned}$ *
-
-
构建数据集的方法:
-
“指导、执行、重新格式化“的高效数据集构建策略
- 以基础种子查询为起点,通过自我指导来增强这些查询
- 用 LLM 参考查询、工具指令来制定 API 调用
- 如果 API 调用成功,专门的团队会评估数据示例
- 最后重组数据,将工具指令从输入角色转换为输出角色
-
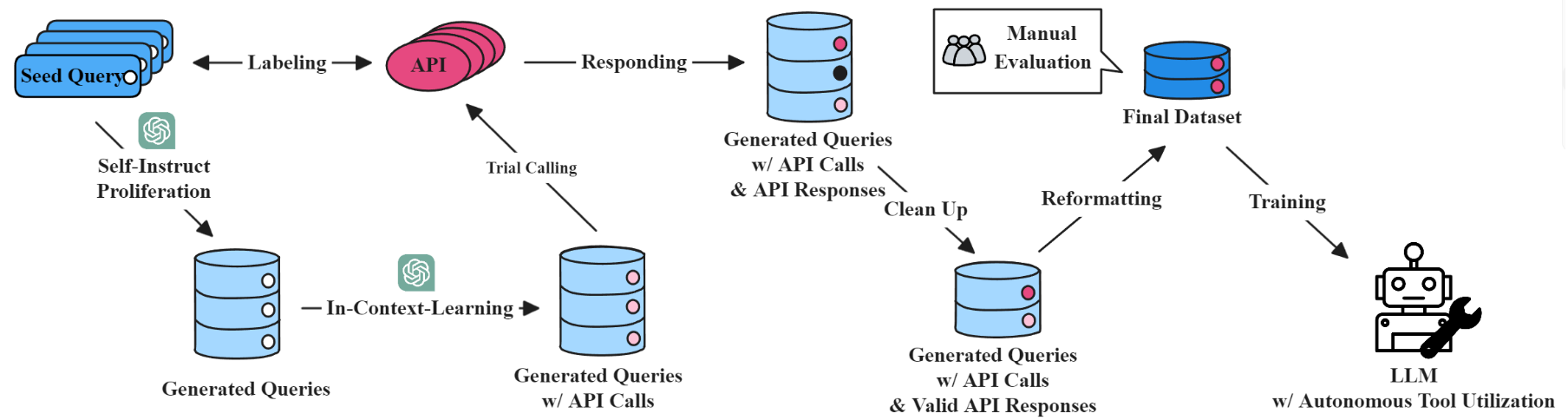
-
持续学习:动态平衡重演策略
- 从关注新的 API 类别开始,逐渐增加旧 API 类别的比例直到实现平衡(防止忘记旧的 API 调用的知识)
- 结果:只需最少的新工具标注数据即可展现出卓越的性能,同时保持现有的工具能力
🚩 结论
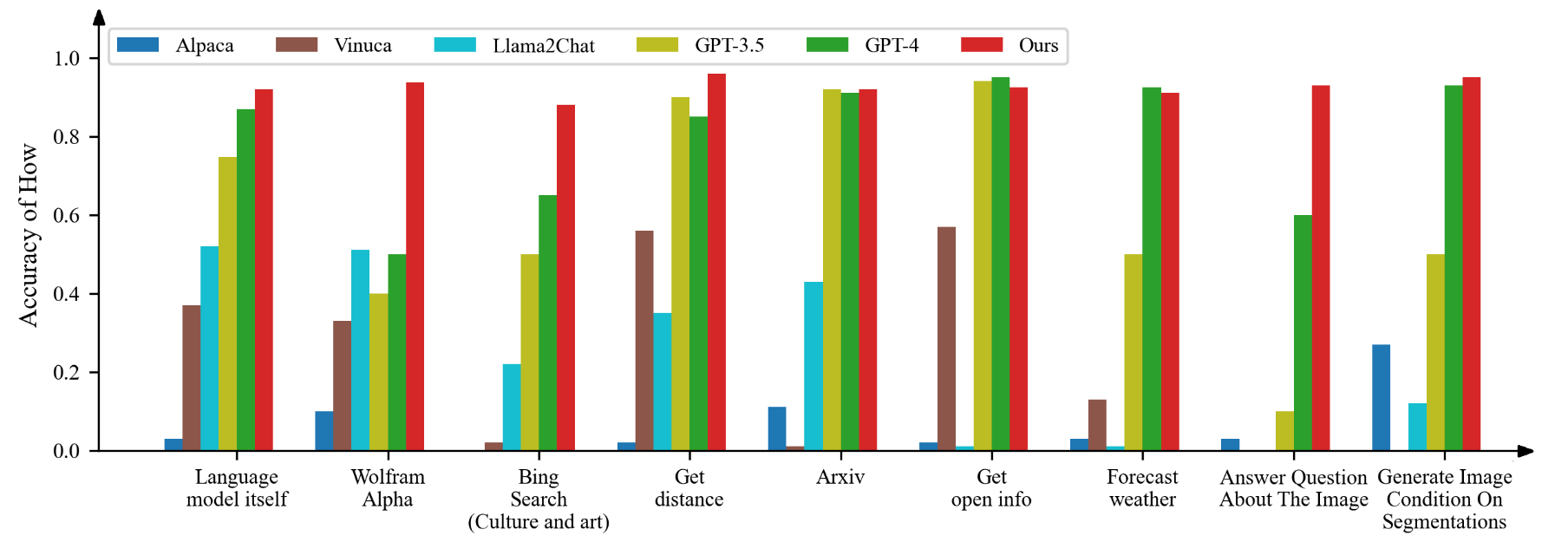
- 通过对包含26种多样化API的注释数据集进行端到端训练,该模型表现出一定的自我意识,在必要时会自动寻求工具的帮助。
- 它在多个评估指标上显著超越了原始指令调优的开源语言模型和GPT-3.5/4。
- 消融实验:我们的统一框架可以有效促进模型在不同工具之间学习。
- 持续学习只需要最少的新标注即可展现出卓越的性能
📌 感想 & 疑问
- 本文的创新点:就是一个概率分解,然后端到端的训练
- 概率分解真的有用吗?最后不还是 nexttoken 微调吗?