Why Can GPT ICL 论文粗读
💡 Meta Data
| Title | Why Can GPT Learn In-Context? Language Models Implicitly Perform Gradient Descent as Meta-Optimizers | | —————————————————————— | ————————————————————————————————————————————————————– | | Journal | (acl 2023) | | Authors | Dai Damai,Sun Yutao,Dong Li,Hao Yaru,Ma Shuming,Sui Zhifang,Wei Furu | | Pub.date | |
📜 研究背景 & 基础 & 目的 (Motivation)
-
LLM 涌现了few-shot In-Context learning的能力
- 通过少量示例可以预测训练的时候没有遇到的输入
-
但是ICL能力的机制还是个开放问题
🔬 研究方法
有人已经研究了发现:线性层的梯度下降和线性注意力形式上是类似的
工作一:解释ICL
transformer attention和梯度下降的形式非常类似,所以将语言模型解释为“元优化器”,将上下文学习理解为隐式微调:
公式推导:
q是当前推理到的token,X是前面不是示例的token,X‘是前面示例的token, $W_{ZSL}q$ 是 zero-shot下 q 的 attention 结果
- 初始公式
2. 简化,线性化
\[\begin{aligned}\mathcal{F}_{\mathrm{ICL}}(\mathbf{q})&\approx W_V[X^{\prime};X]\left(W_K[X^{\prime};X]\right)^T\mathbf{q}\\&=W_VX\left(W_KX\right)^T\mathbf{q}+W_VX^{\prime}\left(W_KX^{\prime}\right)^T\mathbf{q}\\&\equiv\widetilde{\mathcal{F}}_{\mathrm{ICL}}(\mathbf{q}).\end{aligned}\]3. 转换简化后的式子
\[\begin{aligned}\widetilde{\mathcal{F}}_{\mathrm{ICL}}(&(\mathbf{q})=W_\mathrm{ZSL}{\mathbf{q}}+W_VX^{\prime}\left(W_KX^{\prime}\right)^T\mathbf{q}\\&=W_\mathrm{ZSL}\mathbf{q}+\text{LinearAttn}\left(W_VX^{\prime},W_KX^{\prime},\mathbf{q}\right)\\&=W_{\mathrm{ZSL}}\mathbf{q}+\sum_iW_V\mathbf{x}_i^{\prime}\left(\left(W_K\mathbf{x}_i^{\prime}\right)^T\mathbf{q}\right)\\&=W_{\mathrm{ZSL}}\mathbf{q}+\sum_i\left((W_V\mathbf{x}_i^{\prime})\otimes(W_K\mathbf{x}_i^{\prime})\right)\mathbf{q}\\&=W_\mathrm{ZSL}{\mathbf{q}}+\Delta W_\mathrm{ICL}{\mathbf{q}}\\&=\left(W_{\mathrm{ZSL}}+\Delta W_{\mathrm{ICL}}\right)\mathbf{q}.\end{aligned}\]所以ICL理解如下:
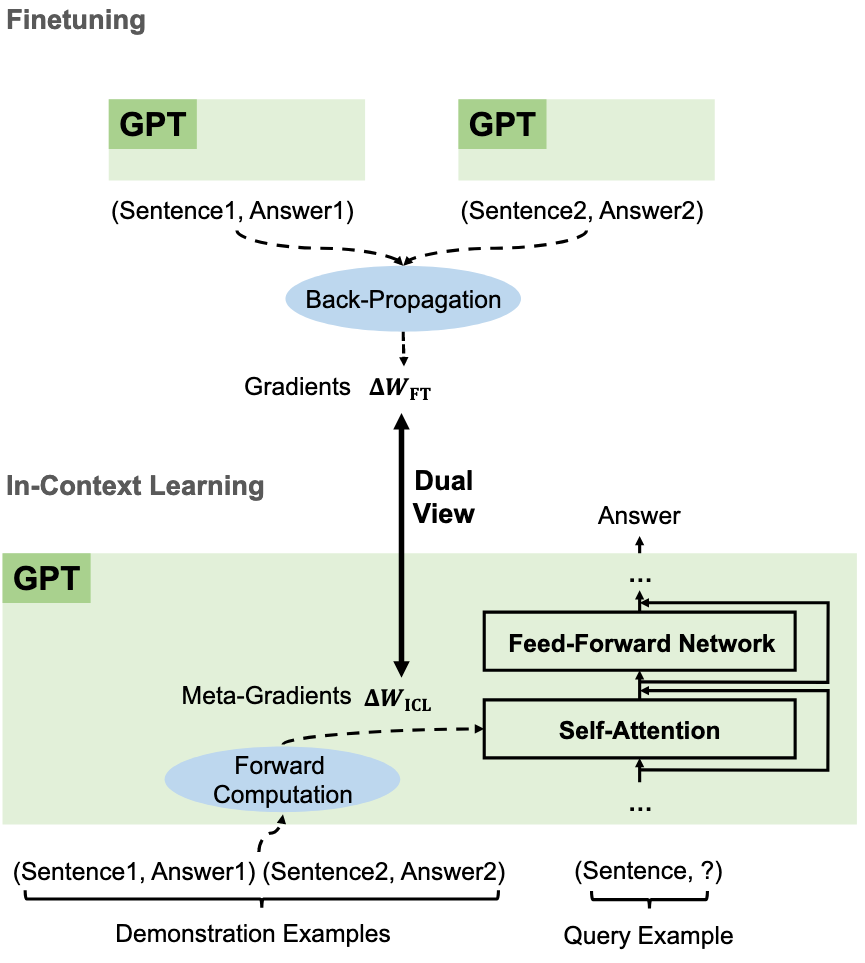
- 预训练的GPT充当元优化器
- 通过前向计算根据示范示例产生元梯度
- 然后通过注意力将这些元梯度应用于原始GPT,以构建ICL模型
ICL 与 fine-tuning 的关系 :
- ICL 通过前向计算产生元梯度
- 微调通过反向传播计算梯度
工作二:提出一种新的注意力机制
受到 fine-tuning 和 ICL 的相似性的启发,通过与基于动量的梯度下降类比设计了一种基于动量的注意力,比基础的注意力提升了性能。
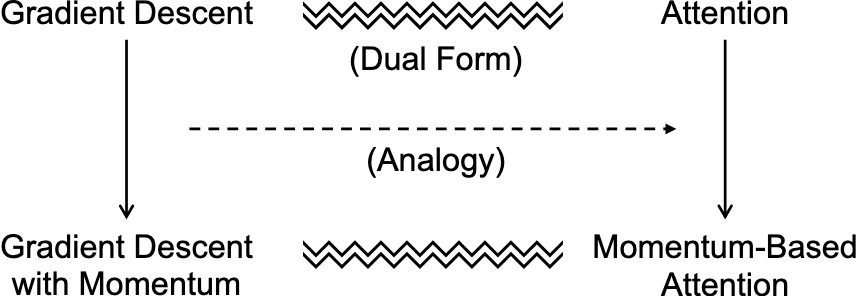
基于动量的梯度下降公式:
\[\Theta_t = \Theta_{t-1} - \gamma \sum_{i=1}^{t-1} \eta^{t-i} \nabla f_{\Theta_i}\]- 参数更新时不仅考虑当前的梯度,还结合了过去多个时间步的梯度信息
基于动量的注意力机制公式:
\[\begin{aligned}\mathrm{MoAttn}(V,K,\mathbf{q}_t)&=\mathrm{Attn}(V,K,\mathbf{q}_t)+\mathrm{EMA}(V)\\&=V\mathrm{softmax}(\frac{K^{T}\mathbf{q}_{t}}{\sqrt{d}})+\sum_{i=1}^{t-1}\eta^{t-i}\mathbf{v}_{i},\end{aligned}\]-
$v_i$是第 i 个位置token 的 value 向量
-
注意力v向量的动量明确增强了注意力的近期偏差,这已被证明对语言建模有帮助
🚩 结论
ICL 行为与显式微调相似
在六个分类任务中,比较ICL和微调的模型预测、注意力输出、对query token的注意力权重
实验结果验证了ICL和微调的行为在多个方面相似
- ICL 的结果包含了大多数 fine-tuning 预测正确的结果
- ICL 和 fine-tuning 修改 attention 输出的方向相同
- ICL 和 fine-tuning 倾向于生成相同的 attention 权重
- ICL 和 fine-tuning 对于训练的 token 的注意力相似
基于动量的注意力机制有效
-
困惑度降低

-
ICL 性能提升

📌 感想 & 疑问
-
没有解释为什么ICL不如fine-tuning
-
也没有解释一些ICL现象,
- 比如示例中标签不正确的影响不大的现象
- 为什么demostration 的顺序会影响ICL 的性能