To CoT or not to CoT? 论文粗读
💡 Meta Data
| Title | To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning | | —————————————————————— | ———————————————————————————————————————————————————————————————— | | Journal | (10.48550/arXiv.2409.12183) | | Authors | Sprague Zayne,Yin Fangcong,Rodriguez Juan Diego,Jiang Dongwei,Wadhwa Manya,Singhal Prasann,Zhao Xinyu,Ye Xi,Mahowald Kyle,Durrett Greg | | Pub.date | 2024-10-29 |
📜 研究背景 & 基础 & 目的 (Motivation)
-
COT 这种额外的“思考”对于哪些类型的任务真的有帮助呢?
- CoT 在大量研究中被证明是有效的,但是这些研究中许多都关注的是一部分特定的任务。(比如评估推理仅在数学领域进行评估)
🔬 研究方法
工作一
工作:
- 进行了一个定量的元分析,涵盖了110多篇使用CoT的论文,并对14个模型的20个数据集进行了自己的评估。
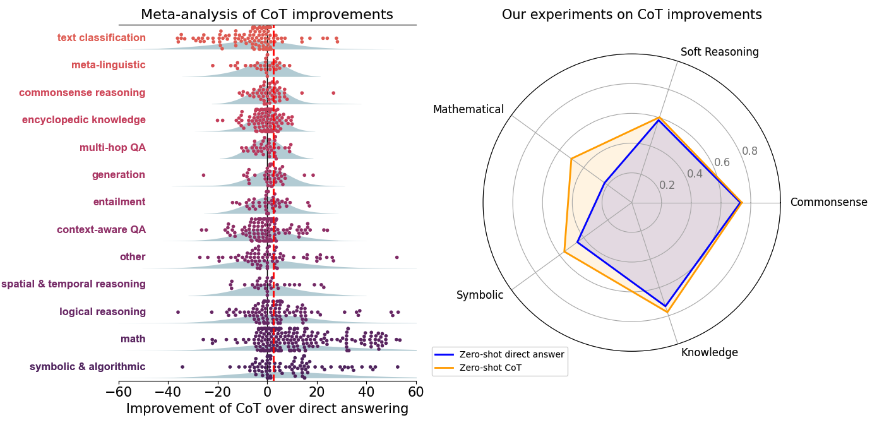
去论文中平均后:
符号推理、数学、逻辑推理提升:14.2、12.3、6.9
其他类别使用 CoT 平均表现 56.8,未使用平均表现 56.1
解释分析:为什么 CoT 仅限这些问题上会有提升?
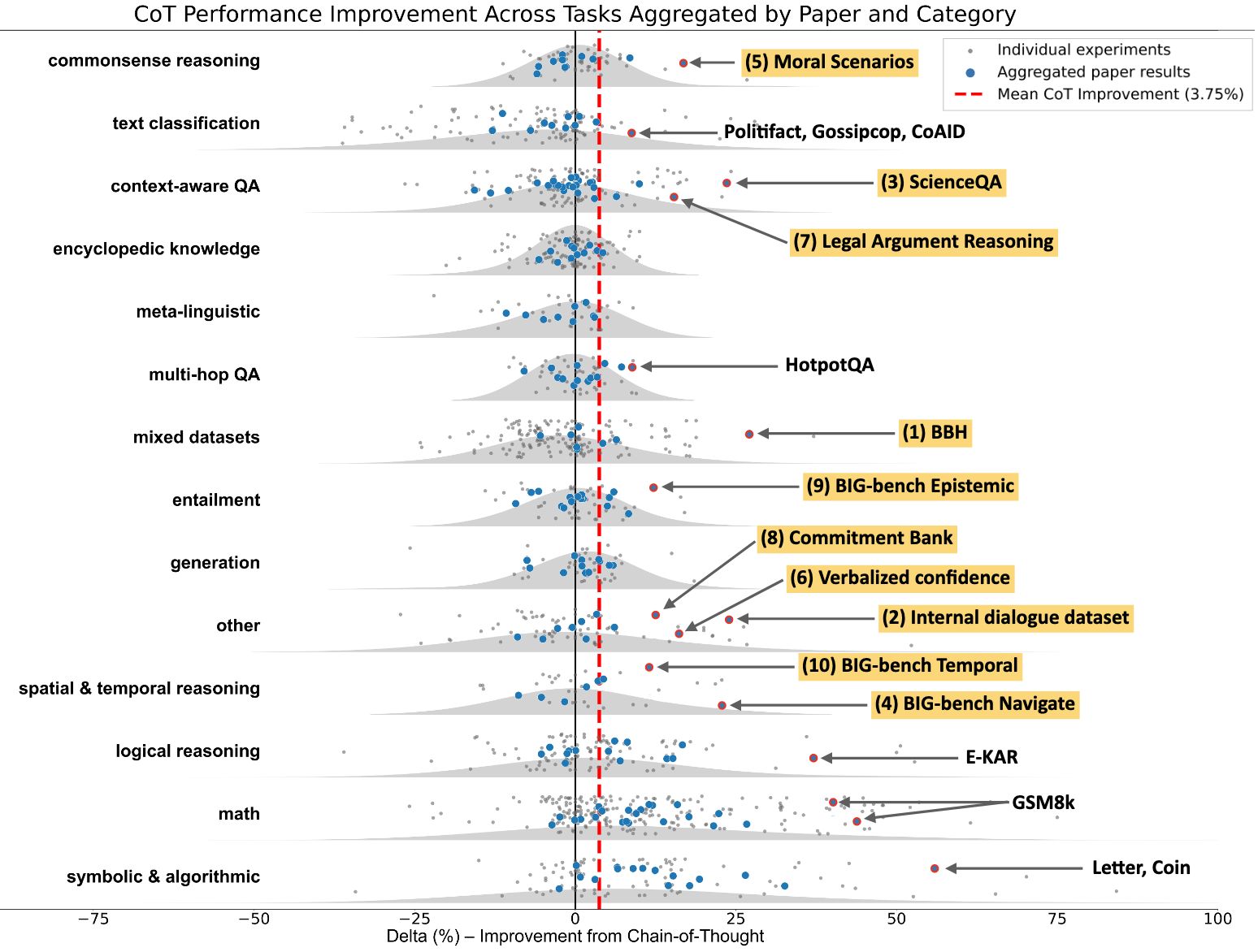
观察图中异常值:
- BIG-bench Hard:需要算法、算术或逻辑推理的问题组成的基准
- BIG-bench Navigate是一个空间推理任务,但在得出最终结论时严重依赖于计算步数这一数学基础
- BIG-bench Temporal是一个时间推理任务(回答关于某些事件何时可能发生的问题),但它需要推理能力来解决
- 法律论证推理(SemEval-2024 Task 5)(Bongard et al., 2022)被归类为上下文感知的QA,但也需要相当大的推理能力
- MMLU-道德场景(Hendrycks et al., 2021a)需要同时回答两个独立的问题,这本质上涉及到两个更简单问题的符号组合。
发现1:
-
CoT 仅在需要数学、逻辑或算法推理的问题上显著有帮助。
-
具体发现 CoT 仅在数据集的数学部分有所益处
- 在 MMLU 中 CoT 带来的性能提升中,有多达 95%归因于问题或生成输出中包含“=”的问法
- 而非数学问题,我们没有发现任何特征可以知识 CoT 何时会有帮助
-
实验:

结果:

- 在非符号推理类别:(常识问题、语言理解和阅读理解)zero-shot CoT 和 zero-shot 直接回答性能几乎没有区别。
- 在数学和符号类别改进获得了很大提升
- ContextHub 和 MuSR 谋杀谜题这样半符号数据集显示出一定的增益。
- 增加样本也影响甚微(在 CoT 有帮助时)
“半符号推理”可以理解为介于纯符号推理与非符号推理之间的一种推理方式。在纯符号推理中,我们通常可以把问题映射到一个被广泛认可并使用的形式系统(比如一阶逻辑或数学表达),然后用已有的符号求解器来直接计算答案。而在非符号推理中,问题往往依赖于常识、情境理解或经验判断,缺乏一个公认的形式系统来表达和解决问题。
“半符号推理”则结合了这两种思路:
- 部分地依赖某个已有的形式系统:在问题里可能存在某些可以形式化的规则、逻辑或推理准则(比如“有动机、有作案手段、有作案机会就意味着是凶手”),这些可以用符号的形式表达并交给求解器处理。
- 仍然需要常识或经验性的推理:问题中往往存在无法被完全形式化的部分,需要通过语言模型或人类常识来补充额外信息或进行解释。例如,在谋杀案场景中,区分角色之间复杂的社会关系、有时候需要联想到常见的社会行为或动机,超出了简单逻辑公式所能直接处理的范围。
因此,在半符号推理中,我们既需要能把可形式化的部分映射到符号表达中去,同时又要结合常识理解和更高层次的推理,以最终得到问题的答案。
工作二
-
数学和形式逻辑推理数据集可以分为两个处理阶段:
- 一个规划步骤(例:将一个问题解析为方程)
- 一个执行步骤(生成中间输出并向解决方案逼近)
CoT 主要帮助执行经计算和符号操作的执行步骤。
工作:
- 将规划与执行分开并与工具增强的 LLMs 进行比较,分析了 CoT 在这些问题上的表现。
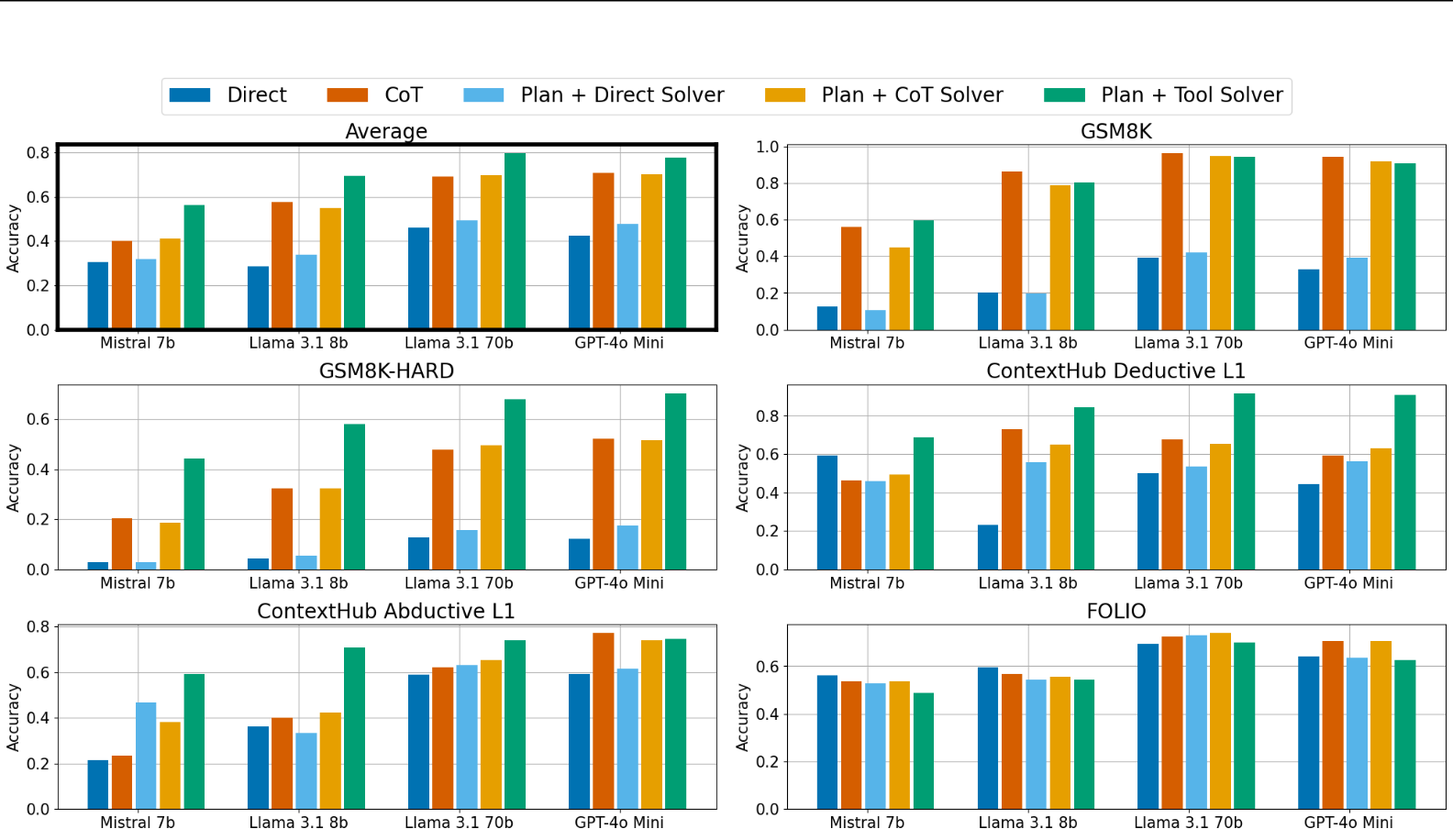
发现2:
-
CoT 主要帮助执行计算和符号操作的步骤,但未能达到工具增强的 LLMs 的性能。
- 使用 CoT 提示的LLM 能够生成可执行的解决计划,并比直接回答更好执行计划。
- 使用 LLM 生成解决计划,然后用工具求解,在两个阶段、所有任务中均优于使用 CoT
🚩 结论
发现:
-
CoT 在涉及数学或逻辑的任务上表现出显著的性能提升,而在其他类型的任务上提升则小得多
- 在 MMLU 上直接生成答案而不用 CoT 的准确率与使用 CoT 时相同,除非问题和模型包含符号运算和推理。
-
CoT 的大部分收益来自于符号执行,但是相对于使用工具求解,表现并不好
结论:
-
- CoT 在许多任务重是不必要的,CoT可以有选择的应用,保持性能的同时节省推理成本。
- CoT
- 需要用超越基于prompt 的 CoT,探索新范式(比如搜索、交互 agent、更多微调来学习 CoT),以更好地利用整个大模型应用范围内的中间计算。