Do not think that much for 2+3=? 论文粗读
💡 Meta Data
| Title | Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs | | —————————————————————— | ——————————————————————————————————————————————————————————————————————— | | Journal | (10.48550/arXiv.2412.21187) | | Authors | Chen Xingyu,Xu Jiahao,Liang Tian,He Zhiwei,Pang Jianhui,Yu Dian,Song Linfeng,Liu Qiuzhi,Zhou Mengfei,Zhang Zhuosheng,Wang Rui,Tu Zhaopeng,Mi Haitao,Yu Dong | | Pub.date | 2024-12-30 |
📜 研究背景 & 基础 & 目的 (Motivation)
-
O1 在推理的过程中模拟人类长时间思考取得了卓越的表现
- 采用扩展的思考链过程,探索多种策略以增强问题解决的能力
- o1类模型存在显著的过度思考问题
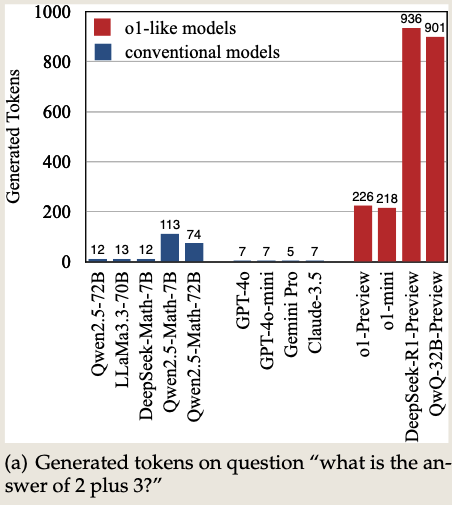
-
问题:如何在测试过程中智能且高效的扩展计算资源?(自主选择何时慢思考)
*
🔬 研究方法
对过度思考问题全面研究:
- 过度思考:为简单问题分配了过多的计算资源,几乎没有收益
在数学任务上过度思考的模式:
- 对提高准确性贡献甚微
- 缺乏推理策略的多样性
- 在简单问题中过度思考更为频繁出现
工作:
观点:推理不应该只要求准确性还要求应用合适复杂度。
- 从结果和过程的角度引入了新颖的效率指标,以评估 o1 类模型的计算资源合理使用。
提出评估指标
准确性提升的效率
\[\xi_O=\frac{1}{N}\sum_{i=1}^{N}\sigma_i\frac{\hat{T}_i}{T_i}\]$\hat{T_i}$ 是在样本 i 第一次显式的出现答案的 token 数
$\sigma_i$ 是当回答正确时 =1 回答不正确是为 0
多样性思考的效率
\[\xi_P=\frac{1}{N}\sum_{i=1}^{N}\frac{D_i}{T_i}\] \[D_i=\sum_{m=1}^M\tau_i^mT_i^m\]$D_i$是有效类别的 token 数量,$T_i$ 所有的 token 数量
实验结果
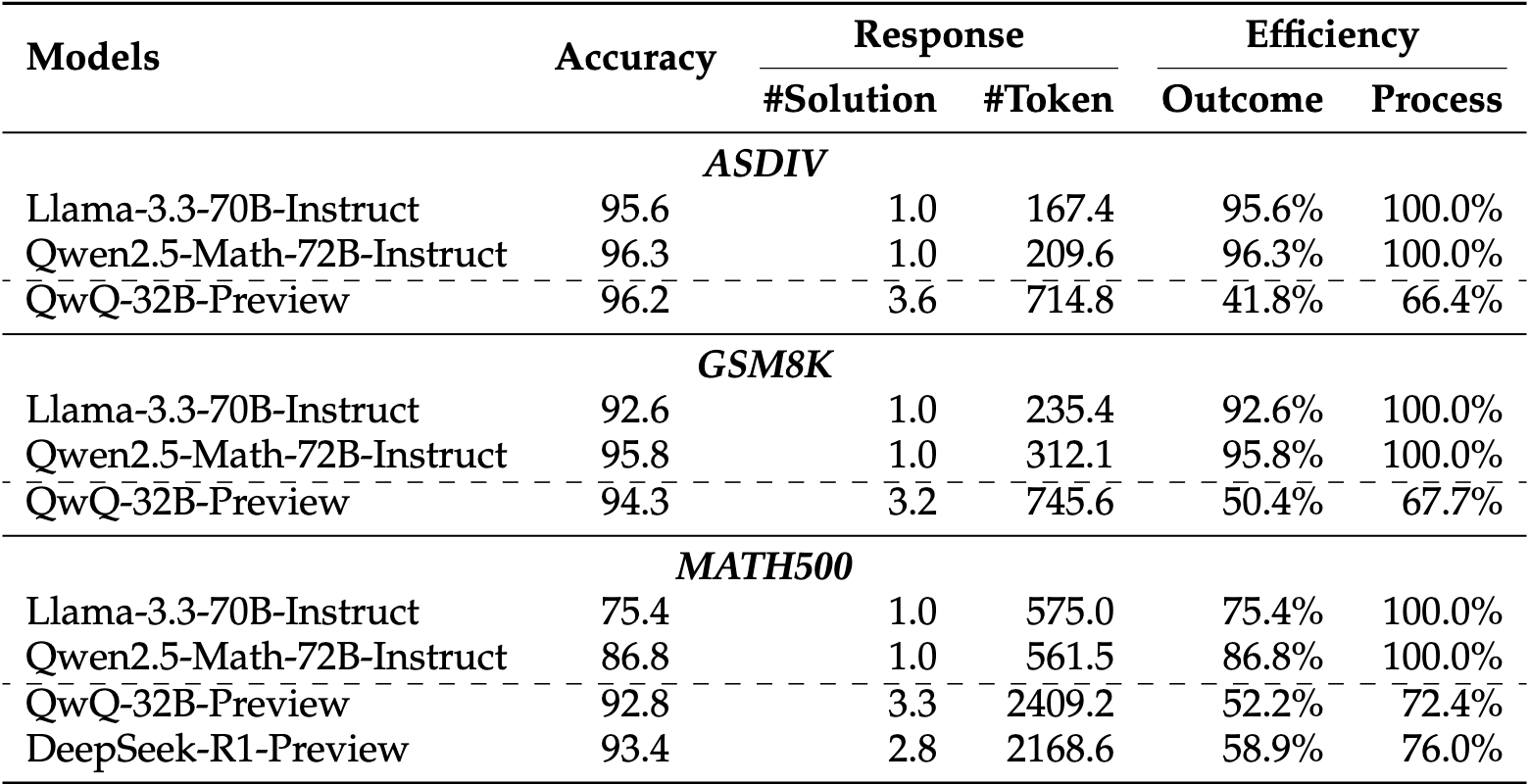
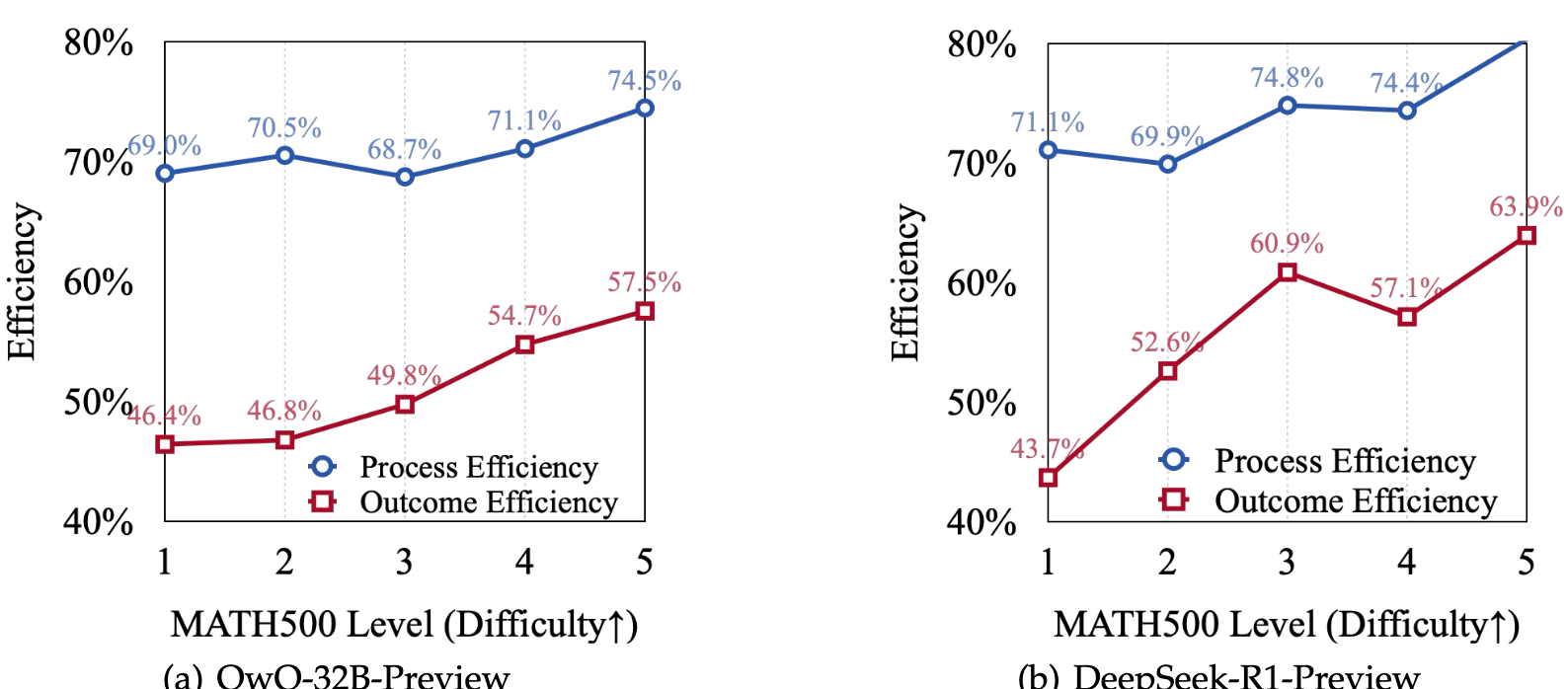
验证了那三种过度思考的模式
缓解过度思考
通过自我训练范式,提出了缓解过度思考的策略,简化推理过程而不影响准确性。
- 通过去除冗余解决方案来简化生成的响应,同时保持基本的反思性。
训练让回答更高效
造数据方法:自我训练的方法
生成三种数据:
- Greedy:next-token选概率最大的
- Shortest:生成十个回答,除去错误的,选择最短的
- Longest:生成十个回答,除去错误的,选择最长的
训练方式:
SFT、DPO、RPO、SimPo
训练让回答提到多样性效率
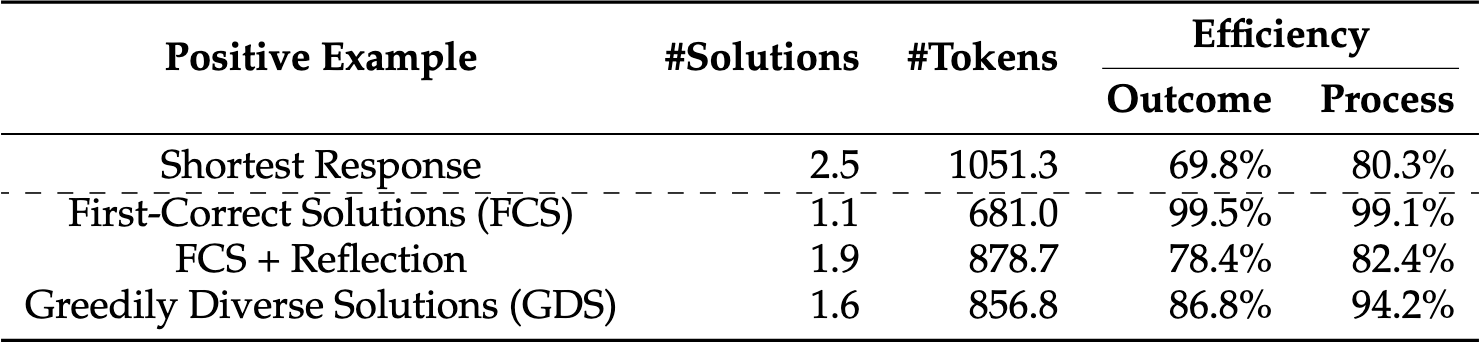
策略:截断正确答案后的 解决方案
-
First-Correct Solutions(FCS):只去第一个正确的解决方案,其他的截断
- 缺点:让 O1 变回了传统的 LLM,没有利用长程反思的优势
-
FCS + Reflection: 得到一个正确的解决方案后,再保留一个正确的解决方案
- 目的是希望在保持效率的同时,不完全丧失模型“长程反思”优势
- 缺点:第二个也只是用同一个思路去验证或重复第一个解法,缺乏“新意”
-
Greedily Diverse Solutions (GDS):贪心地寻找新思路
- 如果第二个解法只是重复或核对第一个,则舍弃;
- 如果第二个解法确实提供了新视角或额外价值,就把它保留。
每个问题,生成 10 个答案,然后选择最短的结果
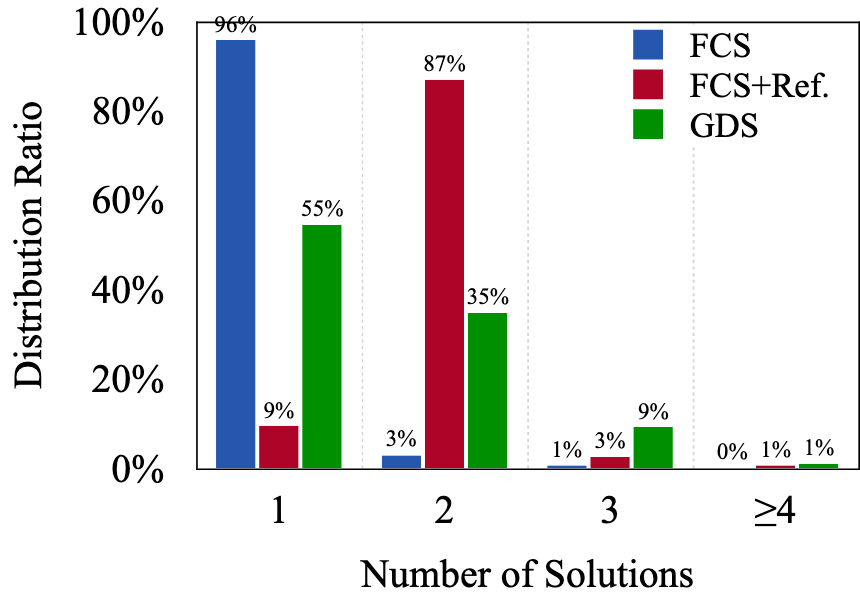
🚩 结论
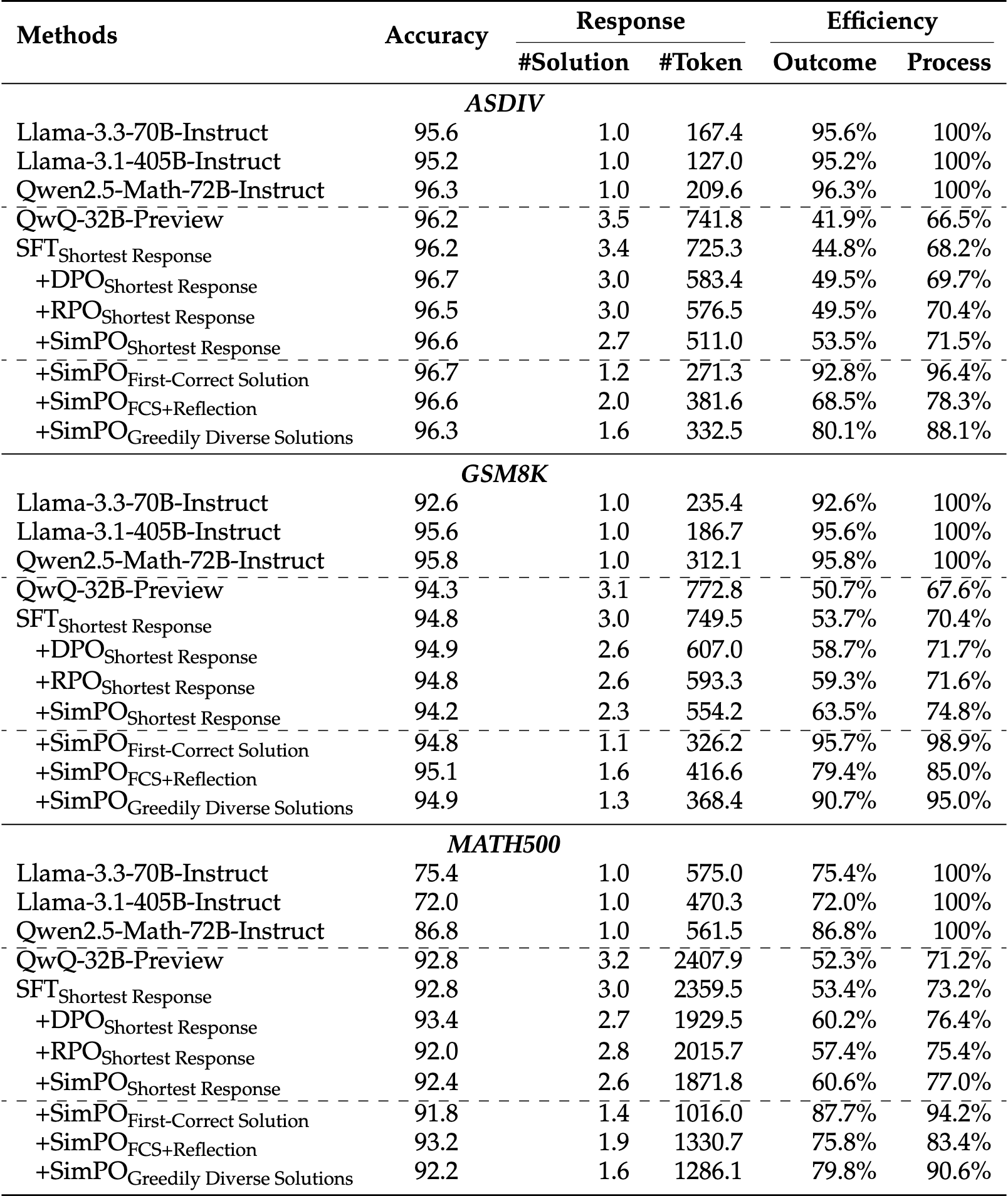
-
保持模型性能的同时,成功减少了计算开销
- GSM8K、MATH500、GPQA和AIME
📌 感想 & 疑问
- 这些数据集都是定量分析或推理的数据集,O1 类模型是不用其他任务上(除推理之外)吗?其他任务上的过度思考会怎么样?