<TooL LLM> 论文粗读
💡 Meta Data
| Title | ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs | | —————————————————————— | ———————————————————————————————————————————————————————————————————————————————————————– | | Journal | (10.48550/arXiv.2307.16789) | | Authors | Qin Yujia,Liang Shihao,Ye Yining,Zhu Kunlun,Yan Lan,Lu Yaxi,Lin Yankai,Cong Xin,Tang Xiangru,Qian Bill,Zhao Sihan,Hong Lauren,Tian Runchu,Xie Ruobing,Zhou Jie,Gerstein Mark,Li Dahai,Liu Zhiyuan,Sun Maosong | | Pub.date | 2023-10-03 |
📜 研究背景 & 基础 & 目的 (Motivation)
-
开源模型使用工具的能力还非常弱:
- 因为instruct-tuning 主要集中在基本语言任务上,而忽略了工具使用
- 与闭源的LLM有很大差距
-
当前研究:有人探讨了为工具使用指令调优数据,但他们未能充分激发大语言模型的工具使用能力,并具有固有的局限性
- 有限的API
- 受限的场景
- 低效的推理和规划
🔬 研究方法
为了弥补差距,提出了ToolLLM,一个一般工具使用框架:包含数据构建、模型训练和评估。
数据构建
提出了ToolBench,一个用于工具使用的指令微调数据集,是使用chatgpt自动构建的
构建可以分为三个阶段
-
API集合:RapidAPI Hub中16464个真实世界的的RESTful API涵盖49个类别
-
指令生成:提示Chatgpt生成涉及这些API的多样化指令,涵盖单工具和多工具场景
-
抽样不用的API组合,然后制定涉及他们的各种指令
- 抽样方法:随机从统一类别中选择2-5个工具,从每个工具抽样3个API
-
ICL+prompt 实现让gpt生成instruction
-
然后用这些(instruction,relevant API)训练一个API retriever
-
-
解决路径注释:使用ChatGPT为每个instruction搜索有效的解决路径(API调用链)
-
解决路径:包含模型包含多个LLM推理轮次和实时API调用
-
问题:但是GPT-4对复杂的指令通过率很低,这使得注释效率很低,CoT 和 ReACT 也不行
- 错误积累
- 探索有限(仅探索一个路径)
-
解决:开发了一种新颖的基于深度优先搜索的决策树算法来增强LLM的规划和推理能力,它使LLM能评估多个推理轨迹,做出深思熟虑的决策(选择撤回或者继续走)
-
结果:显著提高了注释效率,并完成了使用ReACT无法实现的复杂指令训
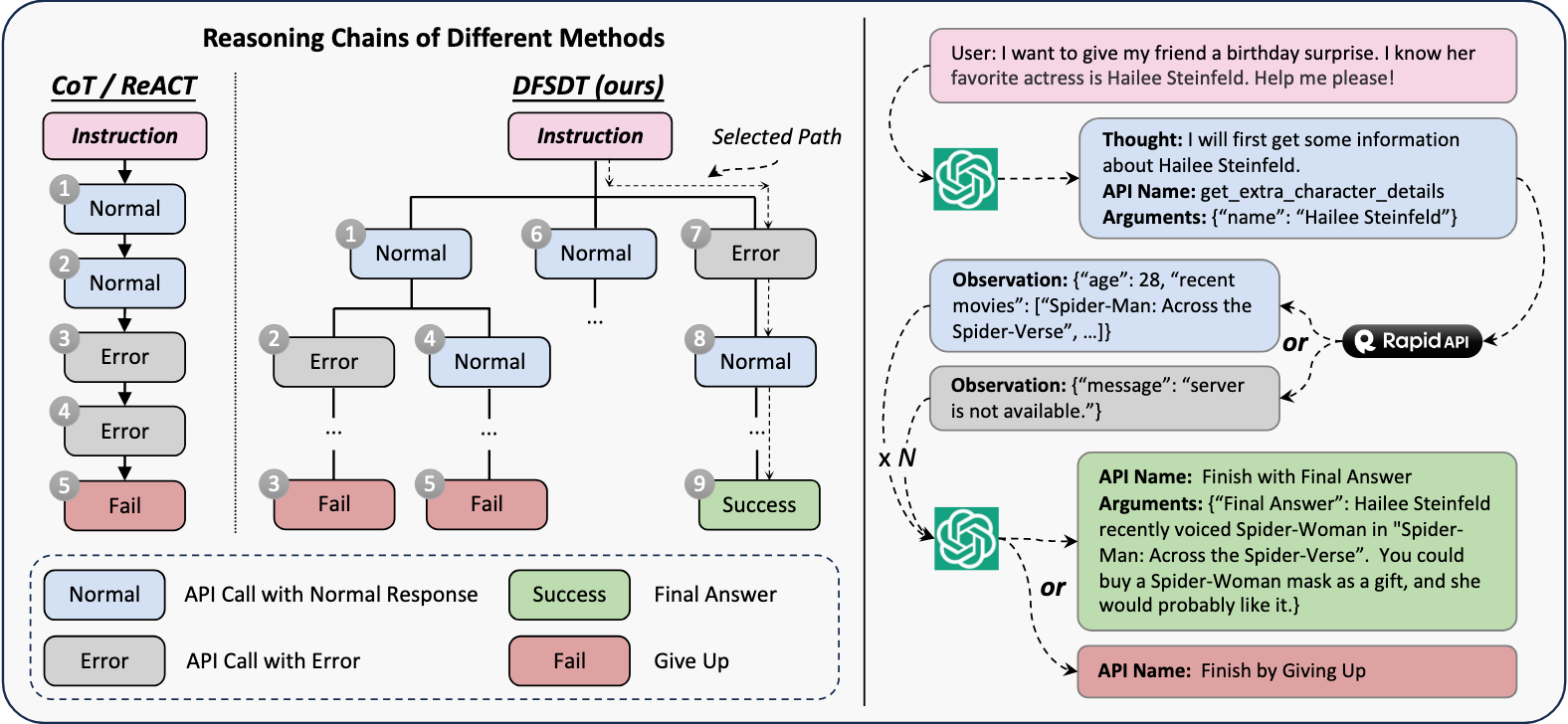
-
评估
开发了一个自动评估器 ToolEval,包含两个指标
-
通过率:衡量LLM在有限资源内成功执行指令的能力
-
获胜率:比较两种解决方案的质量和有用性
- 做法:向GPT提供一个指令和两个解决路径,获得偏好
通过这两点,构建ChatGPT的prompt
为什么要有ToolEval?
- API不断变化的
- 指令存在无线潜在解决路径
- 为每个测试指令标注一个固定的真实解决路径是不可行的
结果:发现ToolEval与人工标注者的通过率有87.1%的一致性而获胜率有80.3%
表明ToolEval很大程度上能够反映和代表人类评估。
模型训练
基于ToolBench对LLaMA进行微调,得到ToolLLaMA,并为其配备了神经网络API检索器,以推荐适合每个指令的API
API Retriever训练
使用Sentence-BERT
- API检索器将指令和API文档分别编码为两个向量嵌入,然后通过计算嵌入相似度来评估相关性,
- 指令相关的API作为正例,并从其他API中随机抽取一些作为负例进行对比学习
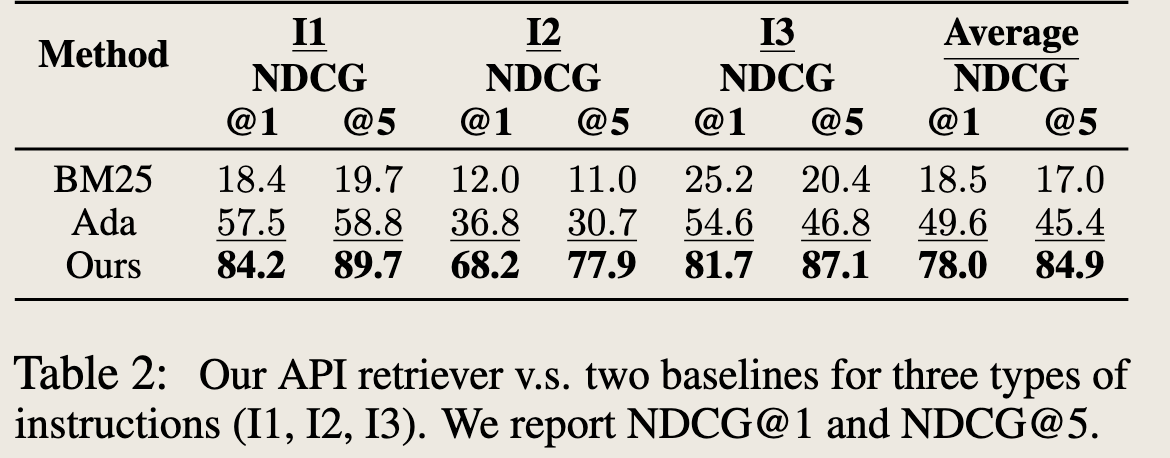
🚩 结论
- 性能好:ToolLLaMA展现出执行复杂指令和推广至未见 API 的卓越能力,并且其表现与 ChatGPT 相当
- 泛化能力好:ToolLLaMA 在一个超出分布的工具使用数据集 APIBench 中也表现出强大的零-shot 泛化能力。